目次
データサイエンティストの必須知識、「データ分析とは? | 統計学の基礎」について解説します。
データを分析する
データは私たちの日常生活のあらゆるところに存在しています。購買履歴、気温の変動、ウェブサイトの訪問数、医療データなど、さまざまなデータが日々生成されています。これらのデータから有益な情報を引き出すためには、データの分析が必要です。データ分析の主な手法として「統計学」があります。
統計学とは?
統計学は、データの収集、整理、解析、解釈、そしてその結果をもとにした意思決定の方法を研究する学問です。実際のデータに基づいて、未知の事実や未来の予測できます。
統計学の基本的な概念をいくつか紹介します。
- 平均 (Mean): データセットの合計値をデータの数で割ったもの。例えば、5人の学生のテストの点数が、50, 60, 70, 80, 90点だった場合、平均点は ( \frac{50 + 60 + 70 + 80 + 90}{5} = 70 ) となります。
scores = [50, 60, 70, 80, 90]
average = sum(scores) / len(scores)
print(average)- 中央値 (Median): データセットを昇順に並べたときに中央に位置する値。データの数が偶数の場合は、中央の2つの値の平均となります。
sorted_scores = sorted(scores)
middle_index = len(sorted_scores) // 2
if len(sorted_scores) % 2 == 0:
median = (sorted_scores[middle_index - 1] + sorted_scores[middle_index]) / 2
else:
median = sorted_scores[middle_index]
print(median)- モード (Mode): データセット内で最も頻繁に出現する値。
統計学はこれらの基本的な概念から、より高度な分析手法や理論まで幅広く研究されています。また、統計学はデータの背後にあるパターンや関係性を理解するための強力なツールとして、さまざまな分野で活用されています。
統計学をマスターすることで、データに隠れた情報を発見したり、未来を予測できます。データの重要性が増している現代社会では、統計学の知識は価値があります。
横断面データと時系列データ
データはその収集の仕方や性質によって、いくつかのタイプに分類されます。ここでは、主に「横断面データ」と「時系列データ」という2つのデータのタイプについて説明します。
- 横断面データ: ある特定の時点での複数の対象から収集されるデータ。例として、2023年の高校生の身長データ、都市別の一人当たりの平均所得などがあります。
- 時系列データ: 時間の経過とともに一定の間隔で収集されるデータ。株価の変動、月別の気温の変動などが該当します。
連続型データと離散型データ
データはその値の性質によって「連続型」と「離散型」の2つに分類されます。
- 連続型データ: 2つの値の間に無限の可能性が存在するデータ。例として、人の身長や体重、時間などがあります。
- 離散型データ: 限られた数の値しか取らないデータ。例として、サイコロの出目や家族の人数、曜日などが該当します。
散布図
散布図は2つの変数の関係性を視覚的に表すグラフです。X軸とY軸にそれぞれの変数を取り、データの点をプロットします。
例として、学生の勉強時間とそのテストの点数の関係を散布図で表現してみましょう。
import matplotlib.pyplot as plt
# Sample data
study_hours = [1, 2, 3, 4, 5]
test_scores = [50, 60, 65, 70, 90]
plt.scatter(study_hours, test_scores)
plt.title('Scatter Plot: Study Hours vs Test Scores')
plt.xlabel('Study Hours')
plt.ylabel('Test Scores')
plt.grid(True)
plt.show()
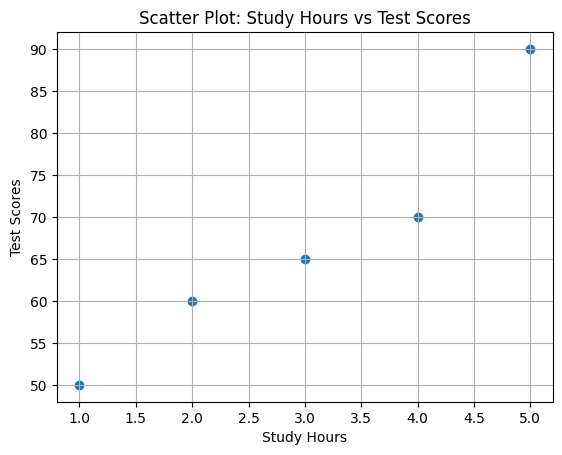
この散布図から、勉強時間が増えるとテストの点数も上がる傾向があることが読み取れます。
散布図は、2つの変数の関係性やトレンド、外れ値の存在などを簡単に確認できるため、データ分析においてとても有用なツールです。

▼AIを使った副業・起業アイデアを紹介♪