アンサンブル学習の基礎
アンサンブル学習は、複数の学習アルゴリズムやモデルを組み合わせて、より高いパフォーマンスを得るための手法です。単一のモデルよりも組み合わせたモデルの方が、一般的には高い精度や堅牢性を持つことが多いです。
定義と概要
アンサンブル学習は、複数のモデル(通常は決定木など)を組み合わせてその予測の平均や多数決を取ることで、単一のモデルよりも優れた予測結果を得るための方法です。アンサンブル手法は、バリアンスを減少させる効果があり、これによって過学習を防ぎます。
アンサンブル学習の動機
アンサンブル学習の背後にある主な動機は、単一のモデルが持つ限界を超えて、より高い精度を実現することです。具体的には、以下のような動機があります。
- 多様性の導入: 異なるモデルやアルゴリズムを組み合わせることで、それぞれのモデルが持つ欠点を補完し合う。
- 過学習の削減: 複数のモデルを組み合わせることで、個々のモデルが学習データの特定のノイズに過度に適合することを防ぐ。
- 堅牢性の向上: 個々のモデルが誤って予測するケースでも、多数のモデルを組み合わせることでその影響を緩和し、全体としての予測の信頼性を向上させる。
アンサンブル学習は、単一のモデルでは難しい特定の問題に対して、複数のモデルの「集合知」を活用して解決できます。この考え方は、”弱い学習器”を多数組み合わせることで、”強い学習器”を作り出すというアイディアに基づいています。
これらの動機に基づき、アンサンブル学習は多くの実世界の問題に対して高い性能を発揮し、多くのデータサイエンスのコンペティションや実業界のタスクで使用されています。
アンサンブル学習の主な手法
アンサンブル学習は、複数の学習アルゴリズムやモデルを組み合わせて、より高いパフォーマンスを得るための手法です。ここでは、主なアンサンブル手法について簡単に説明します。
バギング
バギングは、訓練データから複数回ランダムにサンプリングし(ブートストラップサンプリング)、それぞれのサンプルに基づいてモデルを訓練する手法です。最終的な予測は、各モデルの予測を平均化(回帰の場合)または多数決(分類の場合)して行います。
ランダムフォレスト
ランダムフォレストは、バギングの一形態であり、決定木を基本としたアンサンブル手法です。各木は、データのブートストラップサンプルと、ランダムに選択された特徴量のサブセットを使用して訓練されます。このランダム性により、モデルの多様性が向上し、過学習を抑えます。
ブースティング
ブースティングは、複数の弱い学習器を逐次的に訓練して、強い学習器を作成する手法です。各ステージでの学習は、前のステージでの誤りを正しく予測することに焦点を当てて行われます。
AdaBoost
AdaBoostは最も初期のブースティングアルゴリズムの一つであり、繰り返し訓練の過程で、誤って分類されたデータ点に高い重みを割り当てることで次の学習器がそれらのデータ点を正しく分類することに焦点を当てます。
Gradient Boosting
Gradient Boostingはブースティングの手法の一つで、残差(実際の値と予測値との差)を予測する新しいモデルを逐次的に追加することで性能を向上させていきます。この手法は、回帰、分類、ランキングなどの多くの問題に適用可能です。
【Pythonのサンプルコード】
# 必要なライブラリのインポート
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# データの準備
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)
# ランダムフォレスト
rf = RandomForestClassifier(n_estimators=100)
rf.fit(X_train, y_train)
rf_pred = rf.predict(X_test)
print("Random Forest Accuracy:", accuracy_score(y_test, rf_pred))
# AdaBoost
ab = AdaBoostClassifier(n_estimators=100)
ab.fit(X_train, y_train)
ab_pred = ab.predict(X_test)
print("AdaBoost Accuracy:", accuracy_score(y_test, ab_pred))
# Gradient Boosting
gb = GradientBoostingClassifier(n_estimators=100)
gb.fit(X_train, y_train)
gb_pred = gb.predict(X_test)
print("Gradient Boosting Accuracy:", accuracy_score(y_test, gb_pred))Random Forest Accuracy: 0.9777777777777777
AdaBoost Accuracy: 1.0
Gradient Boosting Accuracy: 0.9777777777777777XGBoost
XGBoostは、”Extreme Gradient Boosting”の略で、Gradient Boostingの高速な実装として広く知られています。特に、大規模なデータセットに対して高速に動作する点や、正則化項を持つことで過学習を抑制できる点が特徴です。また、欠損値の自動処理、並列計算、クロスバリデーションなどの多くの便利な機能もサポートしています。
【Pythonのサンプルコード】
import xgboost as xgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
preds = model.predict(X_test)
print("XGBoost Accuracy:", accuracy_score(y_test, preds))XGBoost Accuracy: 0.9555555555555556
LightGBM
LightGBMは、Microsoftが開発したGradient Boostingのフレームワークで、大規模なデータセットや高次元のデータにも効率的に対応できる点が特徴です。特に、Leaf-wise(葉ベース)の成長戦略を使用することで、高い精度を持ちながらも高速な学習が可能です。
【Pythonのサンプルコード】
import lightgbm as lgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)
model = lgb.LGBMClassifier()
model.fit(X_train, y_train)
preds = model.predict(X_test)
print("LightGBM Accuracy:", accuracy_score(y_test, preds))LightGBM Accuracy: 0.9555555555555556
CatBoost
CatBoostは、Yandexが開発したGradient Boostingのフレームワークで、特にカテゴリカル変数の処理に優れています。内部的にカテゴリカル変数のエンコーディングを行うため、前処理の手間が省けるのが特徴です。
【Pythonのサンプルコード】
import catboost as cb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)
model = cb.CatBoostClassifier(verbose=0)
model.fit(X_train, y_train)
preds = model.predict(X_test)
print("CatBoost Accuracy:", accuracy_score(y_test, preds))CatBoost Accuracy: 0.9333333333333333
スタッキング
スタッキングは、複数の異なるモデルの予測結果を入力として、新しいモデル(メタモデルとも呼ばれる)を訓練する手法です。これにより、各モデルの強みを組み合わせることができ、予測の精度を向上させます。
【Pythonのサンプルコード】
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)
estimators = [
('tree', DecisionTreeClassifier()),
('xgb', xgb.XGBClassifier()),
('lgb', lgb.LGBMClassifier())
]
clf = StackingClassifier(estimators=estimators, final_estimator=LogisticRegression())
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
print("Stacking Accuracy:", accuracy_score(y_test, preds))Stacking Accuracy: 0.9777777777777777
このサンプルコードでは、決定木、XGBoost、およびLightGBMを初めのレベルのモデルとして使用し、これらのモデルからの予測を基に、ロジスティック回帰というメタモデルを訓練しています。これにより、各モデルの予測の強みを組み合わせて、最終的な予測を行います。
スタッキングの主なアイディアは、個々のモデルが持つ異なるバイアスやバリアンスを効果的に組み合わせることで、全体としての予測性能を向上させることです。ただし、実際にスタッキングを適用する際には、過学習に注意する必要があります。特に、スタッキングに使用するモデルの数や種類、メタモデルの選択などのパラメータは、クロスバリデーションなどを用いて適切に調整します。
アンサンブル学習のメリット・デメリット
メリット
- 性能の向上: 複数のモデルを組み合わせることで、個々のモデルよりも高い予測性能を達成できます。
- 過学習のリスク低減: 異なるモデルが持つ異なるバイアスやバリアンスを平均化することで、過学習のリスクを低減します。
- 多様性: 異なるタイプのモデルや異なるハイパーパラメータ設定を組み合わせることで、モデルの多様性を確保できます。
- 堅牢性: 一部のモデルが特定のデータに対して誤った予測を行っても、他のモデルがその誤りを補正することが期待されます。
デメリット
- 計算コスト: 複数のモデルを訓練・予測するため、計算コストが増加します。
- モデルの複雑性: アンサンブルモデルは、個々のモデルよりも解釈が難しくなる可能性があります。
- 訓練時間: 複数のモデルを訓練するため、訓練に要する時間が増加することがあります。
- メモリ使用量: 複数のモデルを同時にメモリ上に保持する必要があるため、メモリ使用量が増加します。
過学習とバイアス
過学習の理解
過学習とは、モデルが訓練データに過度に適合し、新しいデータ(テストデータ)に対しての汎化性能が低下する現象を指します。これは、モデルが訓練データのノイズや偶発的なパターンを学習してしまうために起こります。
グラフ: 過学習の典型的なグラフを示す。訓練データの精度は向上し続ける一方、テストデータの精度はある点から低下する。
バイアスとバリアンスのトレードオフ
バイアスとは、モデルの予測が真の値からどれほど離れているかを示すもので、高いバイアスはモデルがデータの真の構造を捉えていないことを意味します。一方、バリアンスとは、モデルの予測が異なる訓練データセットにどれほど敏感であるかを示すもので、高いバリアンスはモデルが訓練データの偶発的なノイズに過度に適合していることを意味します。
アンサンブル学習は、バイアスとバリアンスのトレードオフを改善するための一つの手法として使用されます。特に、バギングはバリアンスを低減するのに効果的であり、ブースティングはバイアスを低減するのに効果的です。
バイアスとバリアンスのトレードオフの理解は、モデルの設計や選択にとても重要です。高いバイアスを持つモデルは、データの真の構造や関係を十分に捉えられない「未学習」の状態になる可能性があります。一方、高いバリアンスを持つモデルは、訓練データのノイズや特定のサンプルに過度に適合し、「過学習」の状態になる可能性があります。
グラフ: バイアスとバリアンスのトレードオフを示すグラフを描画。モデルの複雑性が増すにつれて、バイアスは減少し、バリアンスは増加する。
アンサンブル学習は、個々の学習器のバイアスとバリアンスをバランス良く組み合わせることで、全体としての予測性能を向上させることを目指しています。例えば、バギングは、高バリアンスなモデルの誤差を平均化することでバリアンスを低減します。一方、ブースティングは、連続的にモデルを追加することで、前のモデルが犯した誤りを補正し、バイアスを低減します。
Pythonのサンプルコード
以下は、バイアスとバリアンスのトレードオフを視覚的に理解するためのシンプルなPythonコードの例です。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# サンプルデータの生成
np.random.seed(42)
X = np.sort(5 * np.random.rand(80, 1), axis=0)
y = np.sin(X).ravel() + np.random.normal(0, 0.5, X.shape[0])
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの複雑性とバイアス、バリアンスの関係を示すグラフを描画
train_errors, test_errors = [], []
degrees = np.arange(1, 10)
for degree in degrees:
# 多項式回帰モデルを用いて度数を変えて学習
polynomial = np.polyfit(X_train.ravel(), y_train, degree)
y_train_predict = np.polyval(polynomial, X_train.ravel())
y_test_predict = np.polyval(polynomial, X_test.ravel())
train_errors.append(mean_squared_error(y_train, y_train_predict))
test_errors.append(mean_squared_error(y_test, y_test_predict))
plt.plot(degrees, train_errors, label="Training error")
plt.plot(degrees, test_errors, label="Testing error")
plt.xlabel('Degree of Polynomial')
plt.ylabel('Mean Squared Error')
plt.legend()
plt.title('Bias-Variance Tradeoff')
plt.show()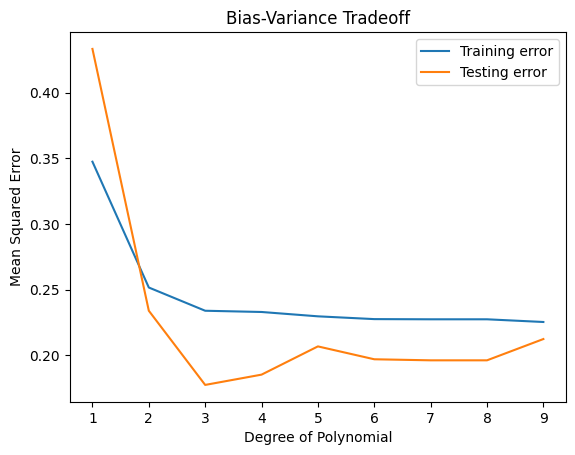
このコードは、多項式の度数を変化させることでモデルの複雑性を変え、それに伴う訓練データとテストデータの誤差の変化を視覚的に示します。モデルの複雑性が増すにつれて訓練データの誤差は減少しますが、テストデータの誤差はある点から増加し始めることが確認できます。これは、モデルが過学習していることを示しています。
実際の利用シーン
業界別の利用事例
- 金融業界:
- クレジットスコアリング: 顧客の信用スコアを予測するためにアンサンブル学習を使用し、貸し倒れリスクを低減させます。
- 株価予測: 複数のモデルを組み合わせて、より正確な株価の動きを予測します。
- 医療業界:
- 疾患の診断: 病気の早期発見や進行度を予測するために、患者のデータを基にした予測モデルを構築します。
- 薬の効果予測: 患者の遺伝子情報や過去の治療履歴から、特定の薬の効果や副作用のリスクを予測します。
- eコマース:
- 推薦システム: 顧客の過去の購買履歴や閲覧履歴をもとに、次に購入する可能性の高い商品を推薦します。
- 顧客の購買離脱予測: 顧客がサービスを離れるリスクを早期に検出し、リテンション対策を講じます。
- 不動産業界:
- 物件価格予測: 地域や物件の特徴を基に、物件の販売価格を予測するモデルを構築します。
- 製造業:
- 製品の品質予測: 製造過程のデータを基に、製品の品質や不良率を予測します。
- 供給チェーンの最適化: アンサンブル学習を利用して、需要予測を行い、生産計画や在庫管理を最適化します。
- エネルギー業界:
- 電力需要予測: 天気や時期、イベント情報などのデータを基に、電力の需要を予測し、供給計画を最適化します。
- 農業:
- 収穫量予測: 土壌のデータや天気情報を基に、作物の収穫量を予測します。
- 病害虫の発生予測: 環境データや過去の発生履歴をもとに、病害虫の発生を予測し、対策を講じます。
問題への適用
アンサンブル学習は、Kaggleなどのデータサイエンスのコンペティションでもよく用いられます。これらのコンペティションでは、高い精度が求められるため、単一のモデルよりも複数のモデルを組み合わせたアンサンブル学習が効果的です。
例: Titanicの生存予測問題
この問題では、Titanicの乗客データを使用して、乗客が生き残るかどうかを予測するモデルを作成します。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import accuracy_score
# データの読み込み
data = pd.read_csv('titanic.csv')
X = data.drop('Survived', axis=1)
y = data['Survived']
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ランダムフォレストとGradient Boostingでの学習
rf = RandomForestClassifier(n_estimators=100, random_state=42)
gb = GradientBoostingClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
gb.fit(X_train, y_train)
# 予測
rf_pred = rf.predict(X_test)
gb_pred = gb.predict(X_test)
# アンサンブル: 2つのモデルの予測を平均
ensemble_pred = (rf_pred + gb_pred) / 2
ensemble_pred = (ensemble_pred > 0.5).astype(int)
# 精度の計算
accuracy = accuracy_score(y_test, ensemble_pred)
print(f"Ensemble Accuracy: {accuracy:.4f}")Ensemble Accuracy: 0.8500
この例では、ランダムフォレストとGradient Boostingの2つの異なるモデルを訓練し、それらの予測を組み合わせてアンサンブル学習を実装しています。結果として、各モデルの良さを組み合わせ、テストデータに対する予測の精度を向上させます。
問題への適用
アンサンブル学習は、リアルワールドの多くの問題に対して有効であり、多様なデータセットや状況に適応できます。特に、データのノイズが多い、または特徴が多岐にわたる場合、単一のモデルよりもアンサンブル学習の方が高い精度を持つことが一般的です。そのため、多くの産業分野や研究領域で、アンサンブル学習は広く採用されています。
Pythonでの実装方法
必要なライブラリのインポート
アンサンブル学習を実装するためには、いくつかのライブラリをインポートする必要があります。以下はその例です。
このコードは、ランダムフォレストとGradient Boostingという2つのアルゴリズムを使用して、与えられたデータセット上で分類し、その後ランダムフォレストによる特徴重要度を可視化するものです。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as pltデータの準備
データセットを読み込み、訓練データとテストデータに分けます。
# データの読み込み
data = pd.read_csv('your_dataset.csv')
X = data.drop('target_column', axis=1)
y = data['target_column']
# 訓練データとテストデータの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)モデルの訓練
ランダムフォレストとGradient Boostingの2つのモデルを訓練します。
# ランダムフォレスト
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
# Gradient Boosting
gb = GradientBoostingClassifier(n_estimators=100, random_state=42)
gb.fit(X_train, y_train)予測と評価
訓練したモデルを使用してテストデータの予測を行い、精度を評価します。
# 予測
rf_predictions = rf.predict(X_test)
gb_predictions = gb.predict(X_test)
# 評価
rf_accuracy = accuracy_score(y_test, rf_predictions)
gb_accuracy = accuracy_score(y_test, gb_predictions)
print(f"Random Forest Accuracy: {rf_accuracy}")
print(f"Gradient Boosting Accuracy: {gb_accuracy}")アンサンブル学習の可視化
モデルの特徴重要度を可視化して、どの特徴が予測に最も影響を与えているかを確認します。
# 特徴重要度の可視化
features = X.columns
importances = rf.feature_importances_
indices = np.argsort(importances)
plt.figure(figsize=(12,8))
plt.title('Feature Importances')
plt.barh(range(len(indices)), importances[indices], align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()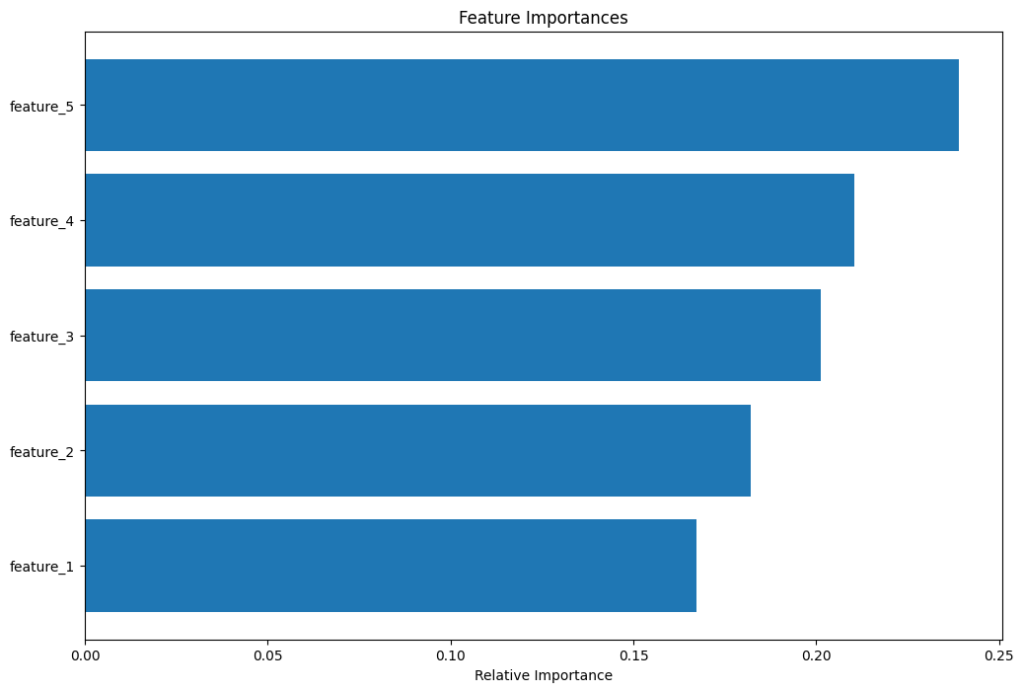
まとめ
アンサンブル学習は、複数の学習アルゴリズムを組み合わせることで、より高い予測性能を目指す手法です。特に、ランダムフォレストやGradient Boostingなどのアンサンブル学習アルゴリズムは、多くの機械学習タスクで高い性能を発揮します。PythonのScikit-learnライブラリを使用することで、これらのアルゴリズムを簡単に実装・評価できます。

▼AIを使った副業・起業アイデアを紹介♪