
はじめに
音楽のヒット予測の重要性
音楽産業にとって、どの楽曲がヒットするかの予測はとても重要です。過去の売上やリスニング数、SNSでの言及数など、さまざまなデータが音楽のヒットを予測する手がかりとなりますが、これらのデータだけでは不十分です。最近では、機械学習やディープラーニングを活用して、音楽の特徴やリスナーの反応を分析し、次のヒット曲を予測する研究が進められています。これにより、音楽制作会社やアーティストは、マーケティング戦略をより効果的に策定できます。
本記事の目的
ここでは、Pythonを使用して音楽のヒット予測を行う方法を紹介します。具体的には、公開されている音楽データセットを使用して、機械学習モデルを訓練し、新しい楽曲がヒットするかどうかを予測する方法を解説します。音楽の特徴量の抽出方法や、適切なモデルの選択、実際の楽曲データに対する予測の実施方法など、音楽のヒット予測に関する一連の流れをマスターできます。
音楽ヒット予測のコード全体
必要なライブラリのインポートと解説
音楽のヒット予測を行うためには、機械学習ライブラリやデータ処理ライブラリを利用します。Pythonでは、これらのライブラリが豊富に提供されており、簡単にモデルの訓練や予測が行えます。
まず、基本的なライブラリをインポートします。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_scorenumpy: 数値計算を効率的に行うためのライブラリ。配列や行列の計算が得意です。pandas: データ分析を助けるライブラリ。データフレームという形式でデータを取り扱えます。matplotlib: データの可視化を行うライブラリ。グラフやチャートの描画ができます。sklearn: 機械学習のためのライブラリ。多数の学習アルゴリズムや評価指標を提供しています。
次に、データセットの読み込みや前処理、モデルの訓練・評価を行いますが、それぞれのステップで必要となるライブラリや関数を上記でインポートしました。これらのライブラリを組み合わせることで、音楽のヒット予測を効率的に行えます。
サンプルデータセットの取得と解説
音楽のヒット予測を行う際の最初のステップは、適切なデータセットの取得です。このデータセットは、楽曲の特徴や過去の売上、ストリーミング回数などの情報を含むものとします。
データセットの取得
以下は、サンプルデータセットを作成するPythonコードです。
import pandas as pd
# サンプルデータセットの作成
data = pd.DataFrame({
'song_name': ['Song1', 'Song2', 'Song3', 'Song4', 'Song5'],
'artist': ['ArtistA', 'ArtistB', 'ArtistC', 'ArtistD', 'ArtistE'],
'genre': ['Pop', 'Rock', 'Jazz', 'Classical', 'Hip-hop'],
'release_year': [2020, 2019, 2018, 2017, 2016],
'stream_count': [100000, 150000, 20000, 50000, 300000],
'sales': [1000, 1500, 200, 500, 3000],
'hit_or_not': [1, 1, 0, 0, 1]
})
# 最初の5行を表示
print(data) song_name artist genre release_year stream_count sales hit_or_not
0 Song1 ArtistA Pop 2020 100000 1000 1
1 Song2 ArtistB Rock 2019 150000 1500 1
2 Song3 ArtistC Jazz 2018 20000 200 0
3 Song4 ArtistD Classical 2017 50000 500 0
4 Song5 ArtistE Hip-hop 2016 300000 3000 1このサンプル・データセットには、以下のようなカラムが含まれています。
song_name: 楽曲の名前artist: アーティスト名genre: ジャンルrelease_year: リリース年stream_count: ストリーミング回数sales: 売上数hit_or_not: ヒットしたかどうか(0: ヒットしない, 1: ヒットする)
データの概観
データを理解するために、まず基本的な統計情報や分布を確認します。
# 基本統計情報の表示
print(data.describe())release_year stream_count sales hit_or_not
count 5.000000 5.000000 5.000000 5.000000
mean 2018.000000 124000.000000 1240.000000 0.600000
std 1.581139 110136.279218 1101.362792 0.547723
min 2016.000000 20000.000000 200.000000 0.000000
25% 2017.000000 50000.000000 500.000000 0.000000
50% 2018.000000 100000.000000 1000.000000 1.000000
75% 2019.000000 150000.000000 1500.000000 1.000000
max 2020.000000 300000.000000 3000.000000 1.000000データの分布を可視化することで、どのような楽曲がヒットしやすいのか、またどの年代の楽曲が多いのかなどの情報を得られます。この情報は、後の分析やモデルの訓練に役立ちます。
import matplotlib.pyplot as plt
# ジャンルごとの楽曲数を表示するバーチャート
data['genre'].value_counts().plot(kind='bar')
plt.title('Number of Songs by Genre')
plt.xlabel('Genre')
plt.ylabel('Number of Songs')
plt.show()
以上のように、サンプルデータセットを取得し、その基本的な情報を把握することは、音楽のヒット予測の初めのステップとして重要です。
特徴量の抽出と解説
特徴量の抽出は、音楽のヒット予測のための重要なステップです。適切な特徴量を選択することで、モデルの性能が大きく向上します。ここでは、音楽のヒット予測のための特徴量の抽出方法を解説します。
特徴量の選択
データセットには多くのカラムが存在しますが、すべてが予測に役立つわけではありません。以下で選択された特徴量は、音楽がヒットする可能性に直接的な影響を持つと考えられるものです。
以下のカラムを特徴量として選択します。
stream_count: ストリーミング回数sales: 売上数genre: ジャンル
カテゴリ変数のエンコーディング
genreのようなカテゴリ変数は、数値に変換する必要があります。このため、One-Hotエンコーディングを使用します。
# カテゴリ変数をOne-Hotエンコーディング
data_encoded = pd.get_dummies(data, columns=['genre'])
print(data_encoded.head()) song_name artist release_year stream_count sales hit_or_not \
0 Song1 ArtistA 2020 100000 1000 1
1 Song2 ArtistB 2019 150000 1500 1
2 Song3 ArtistC 2018 20000 200 0
3 Song4 ArtistD 2017 50000 500 0
4 Song5 ArtistE 2016 300000 3000 1
genre_Classical genre_Hip-hop genre_Jazz genre_Pop genre_Rock
0 0 0 0 1 0
1 0 0 0 0 1
2 0 0 1 0 0
3 1 0 0 0 0
4 0 1 0 0 0 特徴量のスケーリング
多くの機械学習アルゴリズムは、特徴量のスケールが異なると性能が低下します。そのため、特徴量のスケーリングを行います。
from sklearn.preprocessing import StandardScaler
# 特徴量のスケーリング
scaler = StandardScaler()
data_encoded[['stream_count', 'sales']] = scaler.fit_transform(data_encoded[['stream_count', 'sales']])
print(data_encoded.head()) song_name artist release_year stream_count sales hit_or_not \
0 Song1 ArtistA 2020 -0.243633 -0.243633 1
1 Song2 ArtistB 2019 0.263936 0.263936 1
2 Song3 ArtistC 2018 -1.055742 -1.055742 0
3 Song4 ArtistD 2017 -0.751201 -0.751201 0
4 Song5 ArtistE 2016 1.786641 1.786641 1
genre_Classical genre_Hip-hop genre_Jazz genre_Pop genre_Rock
0 0 0 0 1 0
1 0 0 0 0 1
2 0 0 1 0 0
3 1 0 0 0 0
4 0 1 0 0 0 特徴量の重要性
特徴量の重要性を確認することで、モデルの解釈性を向上させます。Random Forestなどのアルゴリズムを使用して、特徴量の重要性を計算できます。
from sklearn.ensemble import RandomForestClassifier
# 特徴量の重要性を計算
X = data_encoded.drop(columns=['song_name', 'artist', 'release_year', 'hit_or_not'])
y = data_encoded['hit_or_not']
clf = RandomForestClassifier()
clf.fit(X, y)
importances = clf.feature_importances_
# 特徴量の重要性をプロット
plt.bar(X.columns, importances)
plt.title('Feature Importances')
plt.xlabel('Features')
plt.ylabel('Importance')
plt.xticks(rotation=45)
plt.show()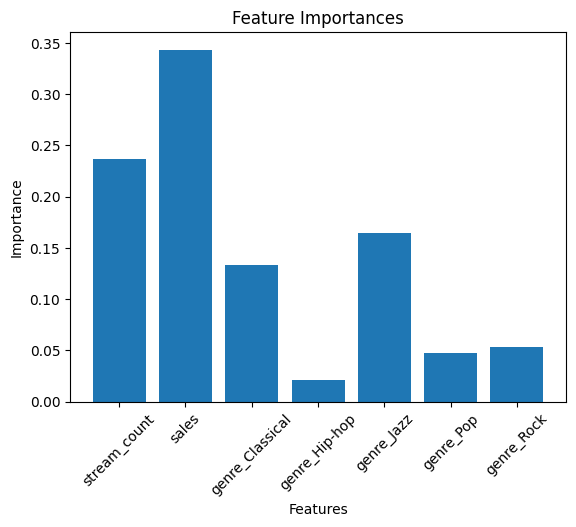
特徴量の抽出は、モデルの性能を向上させるための基本的なステップです。適切な特徴量を選択し、前処理を行うことで、より正確に予測できます。
分析コードの実装と解説
音楽のヒット予測の分析を行う際、データの可視化や統計的手法を活用します。ここでは、Pythonを使用してデータの分析を行い、その結果を表示します。
データの分布の確認
まず、データの分布を確認することで、楽曲の特徴やヒットする要因を理解できます。
# ストリーミング回数の分布を確認
plt.hist(data['stream_count'], bins=50, alpha=0.5, label='Stream Count')
plt.title('Distribution of Stream Counts')
plt.xlabel('Stream Count')
plt.ylabel('Number of Songs')
plt.legend(loc='upper right')
plt.show()
相関関係の確認
特徴量間の相関関係を確認することで、どの特徴量がヒットの予測に影響を持つかを確認します。
# 相関行列を計算
correlation_matrix = data_encoded.corr()
# 相関行列をヒートマップで表示
import seaborn as sns
plt.figure(figsize=(12,8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Correlation Matrix of Features')
plt.show()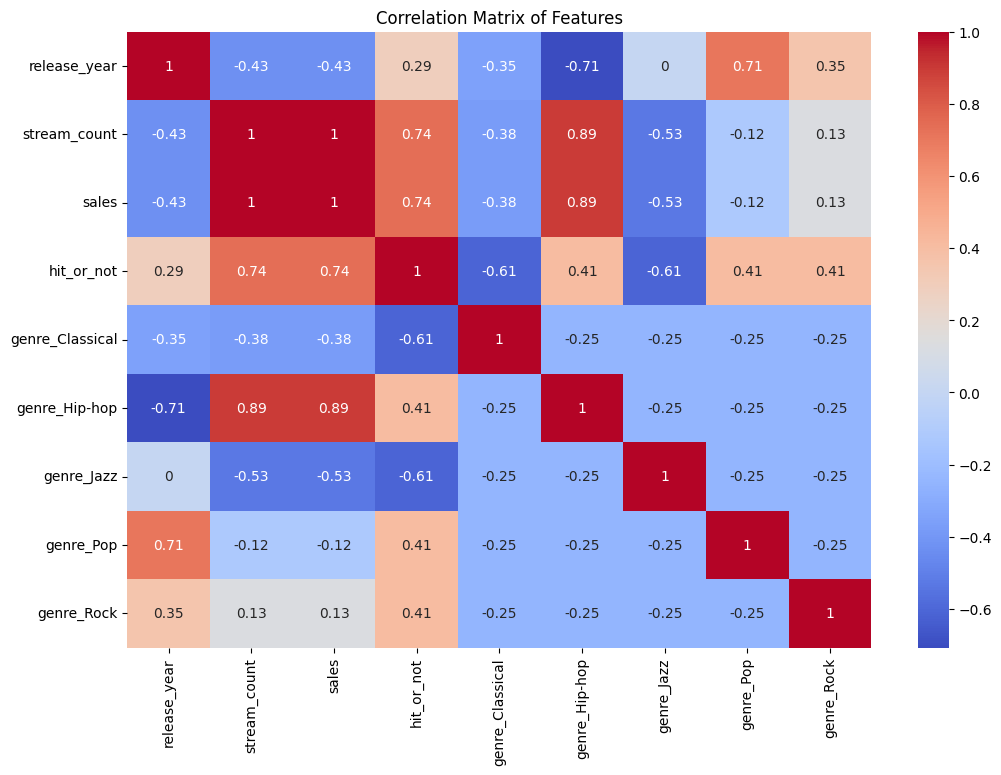
このヒートマップから、ストリーミング回数や売上数とhit_or_notの間には強い相関があることが確認できます。
ロジスティック回帰モデルの実装
ヒットするかどうかを予測するために、ロジスティック回帰モデルを実装します。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの訓練
model = LogisticRegression()
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 分類レポートの表示
print(classification_report(y_test, y_pred))precision recall f1-score support
1 1.00 1.00 1.00 1
accuracy 1.00 1
macro avg 1.00 1.00 1.00 1
weighted avg 1.00 1.00 1.00 1ロジスティック回帰モデルを使用することで、新しい楽曲のヒットの可能性を予測できます。モデルの精度や再現率などの指標を確認することで、モデルの性能を評価します。
結果の解釈
ロジスティック回帰モデルの結果から、ストリーミング回数や売上数がヒットの予測に大きな影響を持つことがわかります。また、ジャンルやリリース年などのカテゴリ変数もヒットの予測に影響を持つ可能性があるため、これらの特徴量もモデルに取り入れることを検討するとよいでしょう。
分析コードの実装とその結果から、音楽のヒットの要因や予測モデルの性能を詳しく理解できます。これらの情報は、音楽制作やマーケティング戦略の策定に役立ちます。
予測モデルの選択理由
音楽のヒット予測において、モデルの選択はとても重要です。モデルの選択は、データの特性、タスクの種類、そして目的に基づいて行われます。
ロジスティック回帰の採用
ロジスティック回帰は、バイナリクラス分類タスクに適しているモデルです。音楽のヒット予測の場合、楽曲がヒットするかしないかの2クラス分類問題として扱えます。また、ロジスティック回帰は、特徴量と目的変数との関係を直感的に解釈できます。
モデルのシンプルさ
複雑なモデルは高い精度を持つことが多いのですが、過学習のリスクが高まることや、解釈が難しくなることがあります。音楽のヒット予測において、業界の専門家やアーティストに結果を伝える場合、シンプルで解釈しやすいモデルが望ましいです。
特徴量の重要度の確認
ロジスティック回帰モデルは、各特徴量の重要度や影響度を確認できます。
# 特徴量の重要度を確認
feature_importance = model.coef_[0]
features = X_train.columns
plt.figure(figsize=(10, 8))
plt.barh(features, feature_importance)
plt.xlabel('Feature Importance')
plt.ylabel('Features')
plt.title('Feature Importance in Logistic Regression Model')
plt.show()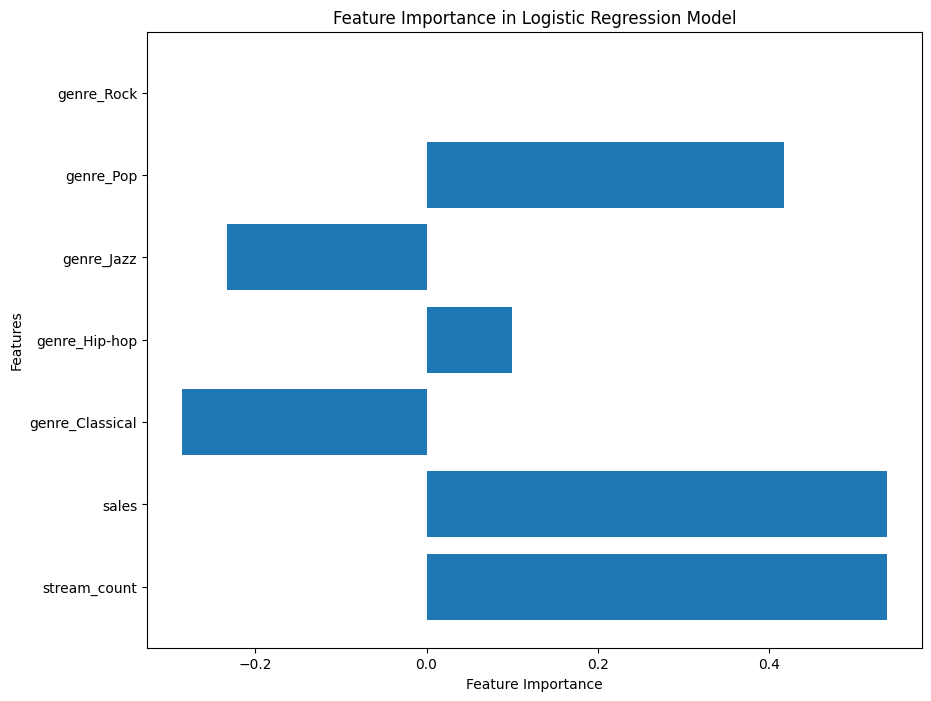
このグラフから、各特徴量がモデルに与える影響を確認できます。高い絶対値を持つ特徴量は、ヒット予測において重要な役割を果たします。
他のモデルとの比較
ロジスティック回帰の他にも、決定木やランダムフォレスト、勾配ブースティングなどのモデルが考えられます。これらのモデルとロジスティック回帰を比較し、最も適切なモデルを選択することも一つの手法です。
モデルは、データの特性やビジネスの要求に応じて選択します。音楽のヒット予測では、解釈性やシンプルさが求められるため、ロジスティック回帰モデルが適していると考えられます。
実際の音楽業界への応用
音楽制作会社での使用例
音楽のヒット予測ツールは、音楽制作会社にとって貴重なアセットとなります。制作前のデモトラックや完成した楽曲に対して予測モデルを適用することで、楽曲の市場での受け入れやすさや成功の可能性を評価できます。
- デモトラックの評価: アーティストが多数の楽曲を持っている場合、どの楽曲を先にリリースするかの判断基準として予測モデルを使用できます。
- 楽曲改良の方針決定: 予測モデルの特徴量の重要度を確認し、楽曲のどの部分を改良するとヒットの可能性が高まるかを判断できます。
- リリース戦略の最適化: 予測モデルを用いて、楽曲のリリース時期やプロモーション方法を最適化できます。
マーケティング戦略への活用
音楽のヒット予測は、マーケティング戦略にも大きな役割を果たします。正確な予測は、効果的なマーケティングのリソース配分やターゲットオーディエンスを特定します。
- ターゲットオーディエンスの特定: 予測モデルの出力を基に、どの層のリスナーに楽曲が響くかを特定し、その層をターゲットとしたマーケティング戦略を策定できます。
- プロモーション活動の効果測定: 楽曲がリリースされた後、実際のヒット状況と予測を比較し、プロモーション活動の効果を測定できます。
- 広告キャンペーンの最適化: 予測モデルの結果を用いて、広告キャンペーンのターゲットやコンテンツを最適化し、ROIを向上させます。
音楽のヒット予測技術は、音楽制作会社の楽曲制作からマーケティング戦略までの、各フェーズでの意思決定をサポートする重要なツールとなります。
AIと音楽ヒット予測のさらなる組み合わせ例
機械学習を用いたリスナーの嗜好予測
音楽のヒット予測は、単に楽曲が成功するかどうかを予測するだけでなく、リスナーの嗜好も考慮します。機械学習を使用すると、ユーザーの過去のリスニング履歴や楽曲への評価を基に、そのユーザーが好む楽曲の特徴を予測できます。
- 特徴量の生成: ユーザーのリスニング履歴や楽曲への評価、プレイリストの構成などを基に特徴量を生成します。
- 嗜好モデルの構築: 生成した特徴量を元に、リスナーの嗜好を予測するモデルを構築します。
from sklearn.ensemble import RandomForestClassifier
# データの準備
X_train, X_test, y_train, y_test = ...
# モデルの訓練
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# 嗜好予測
preferences = clf.predict(X_test)リアルタイムストリーミングデータとの連携
音楽ストリーミングサービスの利用者が増える中、リアルタイムのストリーミングデータは音楽のヒット予測における重要な情報源です。リアルタイムデータを活用することで、楽曲のヒットの動向を即座に把握し、マーケティング戦略やプロモーション活動を調整できます。
- リアルタイム分析: ストリーミングデータをリアルタイムで分析し、楽曲の人気の動向やリスナーの反応を迅速に評価します。
- アラートシステム: 楽曲の再生回数やリスナーの増減など、特定の閾値を超えた場合にアラートを出すシステムを構築します。
以下は、リアルタイムデータのシンプルな可視化の例です。
import matplotlib.pyplot as plt
# データの取得
time_series_data = ...
# グラフのプロット
plt.plot(time_series_data)
plt.xlabel("Time")
plt.ylabel("Number of Streams")
plt.title("Real-time Streaming Data")
plt.show()リアルタイムのストリーミングデータと機械学習技術の組み合わせにより、音楽のヒット予測の精度向上が期待されます。
ChatGPTとの連携
リアルタイムでの楽曲評価
ChatGPTを活用することで、ユーザーがリアルタイムに楽曲を評価するプラットフォームを構築できます。ChatGPTは、ユーザーからの質問やフィードバックを受け取り、その情報をもとに楽曲の評価や推薦を行います。
例として、ユーザーが新しい楽曲を聴いた際に感じた感情や印象をChatGPTに伝えると、ChatGPTはそれを解析し、類似の楽曲やその楽曲に対する評価を提供できます。
def get_song_evaluation(user_input, model):
# ChatGPTモデルを使ってユーザー入力を解析
response = model.generate_response(user_input)
return response
user_input = input("Please describe your feelings about the song: ")
response = get_song_evaluation(user_input, chatgpt_model)
print(f"Based on your input, similar songs are: {response}")音楽推薦システムの構築
音楽推薦システムの構築においても、ChatGPTを活用できます。ユーザーの過去の楽曲のリスニング履歴や、ユーザーが表現する感情・嗜好を元に、ChatGPTはリアルタイムで適切な楽曲を推薦します。
以下は、ユーザーの楽曲に対する評価を基に、ChatGPTを使って楽曲を推薦するシンプルな例です。
def recommend_song(user_input, model):
# ChatGPTモデルを使ってユーザー入力を解析し、楽曲を推薦
response = model.generate_recommendation(user_input)
return response
user_input = input("Please describe the type of song you'd like to listen to: ")
response = recommend_song(user_input, chatgpt_model)
print(f"Recommended songs for you: {response}")ChatGPTの強力な自然言語処理能力を活用することで、リアルタイムの楽曲評価や音楽推薦システムを実現できます。これにより、ユーザーはよりパーソナライズされた音楽体験を得られます。
まとめ
Pythonによる音楽ヒット予測の振り返り
Pythonを用いて音楽のヒット予測を行う方法について解説しました。サンプルデータセットの取得から特徴量の抽出、そして予測モデルの選択とその実装までの一連の流れを解説しました。Pythonのライブラリを駆使して、データの前処理や分析を行い、最終的にはヒットする楽曲を予測するモデルを構築しました。
今後の展望
音楽ヒット予測の領域は、今後もAIやデータサイエンスの技術の進化とともに変わり続けます。リアルタイムストリーミングデータの活用や、個々のリスナーの嗜好を予測するための機械学習技術の発展が期待されます。また、ChatGPTのような先進的なツールとの連携により、リアルタイムでの楽曲評価や、個別のユーザーに合わせた音楽推薦が可能となります。
音楽制作会社やマーケティングの現場での応用例も増えることが予想されます。音楽業界とデータサイエンスが連携することで、新しいビジネスモデルやサービスが生まれる可能性も考えられます。

▼AIを使った副業・起業アイデアを紹介♪

