
AIエンジニアになって長寿者の血液を分析しよう。最近の研究では、長寿者の血液には特長があることがわかりました。
ここでは、長寿者の血液に含まれる重要なバイオマーカーを分析するPythonコードを紹介します。
AIや機械学習技術を駆使して、どのバイオマーカーが長寿に影響を与えるかを見つけ出します。
さらに、この技術を他の業界に応用する方法についても解説しますので、AIエンジニアやプログラマーに転職して年収アップをめざす方には必見の内容です。
異常に長生きした人の血液の特徴
長寿者の血液には重要な違いがあることが分かったそうです。
最新の研究では、90歳以上の人々に共通するコレステロールやグルコースなどのバイオマーカーが明らかになりました。44,000人のスウェーデン人データを分析し、100歳以上の人は一般的にグルコースやクレアチニン、尿酸のレベルが低いことが判明したということです。
また、ほとんどのバイオマーカーで異常値が少なく、総コレステロールや鉄分のレベルが高い人ほど長生きする傾向が見られました。
この発見は、代謝健康や栄養が長寿に影響を与える可能性を示唆していますが、遺伝や生活習慣の影響についてはさらなる研究が必要ということです。
AIで長寿者の血液を分析:利用されるIT技術
異常に長生きした人の血液には、共通の特徴があるということですね。
長寿の血液の分析、研究で使用される主なIT技術は、下記のとおりです。
- プログラム言語
Python: データ分析や機械学習のライブラリが豊富で、特に研究や学術用途で広く使われています。
R: 統計分析やデータ可視化に強みがあり、生物医学研究でもよく利用されます。 - AI技術
機械学習: データセットからパターンを見つけ、予測モデルを構築するために使用されます。特に分類や回帰分析に利用されます。
ディープラーニング: 複雑なデータから特徴を抽出し、より精度の高い予測を行うための技術です。 - データベース技術
SQL: 大規模なデータセットの管理とクエリのために使用される関係データベース管理システム(RDBMS)。
NoSQL: 非構造化データや多様なデータ形式を扱うためのデータベース(例:MongoDB)。 - クラウド技術
Amazon Web Services (AWS): データストレージや計算リソースを提供し、大規模データの処理を支援します。
Google Cloud Platform (GCP): 機械学習モデルのトレーニングやデータの保存に使用されます。 - セキュリティ対策
データ暗号化: 個人情報や研究データを保護するためにデータを暗号化します。
アクセス制御: データへのアクセス権を厳密に管理し、認可されたユーザーのみがデータにアクセスできるようにします。
セキュアなデータ転送: 安全なプロトコル(例:HTTPS)を用いてデータを送信し、通信途中でのデータ漏洩を防ぎます。
各IT技術を活用して、長寿に関する研究データの収集、分析が行われています。
PythonとAIで長寿者の血液を分析
PythonとAIで、長寿者の血液を分析するコードを書いてみましょう。
PythonのAIや機械学習で、長寿のバイオマーカーの分析を行います。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
# Generate sample data
np.random.seed(42)
data = {
'age': np.random.randint(60, 100, 1000),
'cholesterol': np.random.uniform(150, 300, 1000),
'glucose': np.random.uniform(70, 200, 1000),
'creatinine': np.random.uniform(0.5, 1.5, 1000),
'uric_acid': np.random.uniform(3, 7, 1000),
'liver_function': np.random.uniform(10, 40, 1000),
'kidney_function': np.random.uniform(0.5, 1.5, 1000),
'iron': np.random.uniform(50, 150, 1000),
'albumin': np.random.uniform(3.5, 5.5, 1000),
'centenarian': np.random.choice([0, 1], 1000, p=[0.97, 0.03])
}
df = pd.DataFrame(data)
# Display the first few rows of the dataframe
print(df.head())
# Split the data into training and testing sets
X = df.drop('centenarian', axis=1)
y = df['centenarian']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate the model
print("Classification Report:")
print(classification_report(y_test, y_pred))
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
# Feature importance
importances = model.feature_importances_
features = X.columns
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(10, 6))
plt.title("Feature Importances")
plt.bar(range(X.shape[1]), importances[indices], align="center")
plt.xticks(range(X.shape[1]), features[indices], rotation=90)
plt.tight_layout()
plt.show()
# Plot distribution of biomarkers
plt.figure(figsize=(12, 8))
for column in df.columns[:-1]:
sns.histplot(df[column], kde=True, label=column)
plt.legend()
plt.title("Distribution of Biomarkers")
plt.show() kidney_function iron albumin centenarian
0 0.592529 131.810417 5.481425 0
1 0.899432 145.791208 3.995234 0
2 0.918929 132.426799 4.512913 0
3 1.014562 106.484144 5.188805 0
4 1.208964 67.965697 3.978446 0
Classification Report:
precision recall f1-score support
0 0.98 1.00 0.99 197
1 0.00 0.00 0.00 3
accuracy 0.98 200
macro avg 0.49 0.50 0.50 200
weighted avg 0.97 0.98 0.98 200
Confusion Matrix:
[[197 0]
[ 3 0]]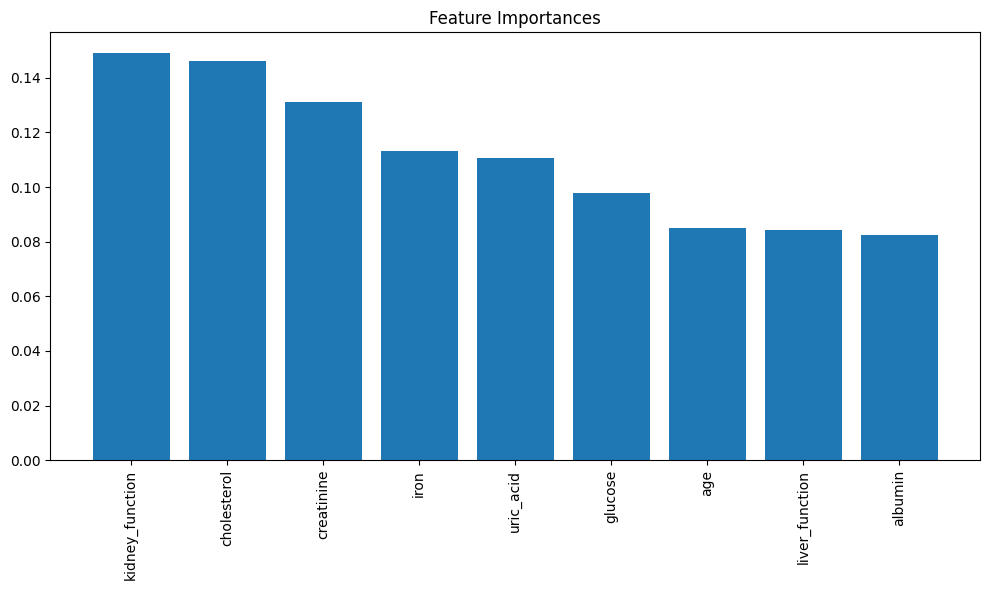
コードの解説
- データ生成: サンプルデータを生成する。年齢、コレステロール、グルコース、クレアチニン、尿酸、肝機能、腎機能、鉄、アルブミンのデータをランダムに生成し、
centenarian(百寿者)のフラグを設定。 - データの表示: 生成したデータの最初の数行を表示。
- データの分割: データを訓練セットとテストセットに分割。
- モデルの訓練: ランダムフォレスト分類器を用いてモデルを訓練。
- 予測: テストセットを用いて予測を行う。
- モデルの評価: 分類レポートと混同行列を表示してモデルの性能を評価。
- 特徴量の重要度: 特徴量の重要度をプロットして、どの特徴が長寿に寄与しているかを確認。
- バイオマーカーの分布のプロット: 各バイオマーカーの分布をヒストグラムでプロットして視覚化。
AIで長寿者の血液を分析:応用アイデア
AIで長寿者の血液を分析する技術の、応用アイデアを考えてみましょう。
同業種(ヘルスケア・医療分野)への応用アイデア
- 予防医療の強化:
バイオマーカーを用いて個々の健康状態をモニタリングし、早期に疾病リスクを発見することで、予防医療を強化する。 - 個別化医療:
患者ごとに異なるバイオマーカーのプロファイルを基に、より効果的な治療法を提案し、医療の個別化を進める。 - 健康寿命の延伸:
長寿者のバイオマーカーを参考にして、健康寿命を延ばすための新しい栄養指導やライフスタイル改善プログラムを開発する。 - 高齢者ケアの向上:
ケアホームの高齢者を対象にしたバイオマーカーのモニタリングを導入し、より適切なケアプランを策定する。 - 遺伝研究の推進:
長寿者の遺伝的要因を解析し、遺伝カウンセリングや遺伝的リスク評価の精度を高める。
他業種への応用アイデア
- スポーツ・フィットネス:
アスリートや一般のフィットネス愛好者に対して、バイオマーカーを利用したパフォーマンスの最適化や怪我予防のプログラムを提供する。 - 保険業界:
バイオマーカーを用いた健康リスク評価を保険商品の設計に取り入れ、個々の健康状態に応じた保険プランを提供する。 - 食品業界:
健康寿命を延ばすために有効な栄養素を含む食品や、サプリメントの開発にバイオマーカー研究の知見を活用する。 - ウェルネス・リゾート:
長寿のバイオマーカーに基づいた健康プログラムやスパトリートメントを提供し、顧客の健康維持をサポートする。 - 人材管理・企業健康プログラム:
従業員の健康管理の一環としてバイオマーカーを用いた健康評価を行い、病気の予防や健康促進に役立つプログラムを導入する。
AIで長寿者の血液を分析する技術は、さまざまな分野に応用できそうですね。まさに、早い者勝ちのビジネスチャンスです。
AIで長寿者の血液を分析:まとめ
長寿者の血液に含まれる重要なバイオマーカーを分析するIT技術や、Pythonでの具体的なコーディング方法を紹介しました。
AIエンジニアやプログラマーに転職を考えている人の参考になったと思います。
また、この技術を応用するビジネスアイデアも紹介しました。
あなたもAIエンジニアやプログラマーに転職して、長寿の秘密を解明しましょう。
これからの時代、医療の未来を切り開くのは医者ではなく、AIエンジニアです。

▼AIを使った副業・起業アイデアを紹介♪

