
インターネットやiPhoneの登場を予測した有名な未来学者レイ・カーツワイルが、今度は5年以内に人間が不死を手に入れる可能性があると予測しています。AIと生命科学の進歩によって、人間の寿命の限界が取り払われる未来が近づいているのかもしれません。AIを活用した「不死」関連ビジネスの可能性を探ってみましょう。
レイ・カーツワイル:常に時代の先を行く予言者

レイ・カーツワイルは、最も影響力のある未来学者の一人です。1948年生まれの彼は、発明家、著作家であるだけでなく、AIの分野のリーダーであり、多くの予測が的中してきた先見性を持つ人物です。
マサチューセッツ工科大学(MIT)を卒業したカーツワイルは、光学文字認識や音声合成など、いくつもの画期的な技術開発に貢献してきました。その功績により、米国技術革新国家勲章など数多くの栄誉を受けています。
現在Googleのチーフエンジニアとして活躍するカーツワイルは、著書「シンギュラリティは近い」(2005年)とその続編「シンギュラリティはより近い」(2025年)では、技術の進歩が人類の未来に与える深い影響について探究しています。
カーツワイルの特筆すべき点は、その驚くべき予測能力にあります。彼はインターネットの台頭、スマートフォンの出現、そして1997年のIBMのディープブルーがチェスチャンピオンのガリー・カスパロフに勝利することさえも予見していました。そして今、彼は大胆な予測をしています。人類は2030年までに不死を手に入れる可能性があるというのです。
「不死」関連のAI起業アイデア3選
では、カーツワイル予言を参考に、AIを利用した「不死」のビジネスアイデアを考えてみましょう。
1. 「LifeSpan AI」パーソナルヘルスオプティマイザー
あなたの日々のデータを分析し、最長寿命を達成する個別化された計画を提供するAIプラットフォームです。遺伝子データ、生活習慣情報、バイオマーカーを組み合わせて、あなたの寿命を最大化する推奨事項を提供します。
このプラットフォームの特徴:
- 生体センサーとの連携による継続的な健康モニタリング
- 食事、運動、睡眠のパターン認識による個別化された推奨事項
- 幹細胞治療や遺伝子治療などの最新長寿技術へのアクセス
- 認知機能トレーニングプログラム
- デジタル意識保存のための定期的なマインドスキャン
2. 「MindVault」デジタル意識保存サービス
カーツワイルが提唱する「デジタル不死」の概念に基づいたサービスです。AIを使用して、あなたの記憶、性格、思考パターンを定期的にデジタル形式で保存します。将来的には、このデータを使用してあなたのデジタル分身を作成することをめざします。
このサービスの特徴:
- 脳活動パターンの定期的な記録と分析
- 記憶強化とデジタル保存のための認知トレーニング
- 個人の決断履歴の詳細なデータベース化
- 会話スタイルと感情反応のAIモデリング
- 家族や友人との将来的な対話のためのデジタル分身作成
3. 「イモータルエコシステム」総合長寿プラットフォーム
不死をめざす人々のためのオールインワンプラットフォームです。世界中の長寿研究、治療法、テクノロジーにアクセスできるマーケットプレイスと、同じ目標を持つユーザーを繋ぐコミュニティ機能を備えています。
このプラットフォームの特徴:
- 寿命延長治療へのアクセス
- 世界中の長寿クリニックとのマッチング
- 遺伝子編集技術の最新情報とアクセス
- 冷凍保存サービスの比較とアクセス
- バイオハッカーや研究者とのコミュニティ機能
- 「寿命貯蓄口座」—将来の治療のための長期的な資金計画
「不死」関連技術を実現するPythonコード
では実際に、「不死」関連技術を実現するPythonコードを書いてみましょう。
以下は、LifeSpan AIプラットフォームで使用できる、バイオマーカーを分析して寿命予測するPythonコードの例です。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import datetime
# LifeSpan AI - Biomarker analysis and longevity prediction model
class LifeSpanAI:
def __init__(self):
"""Initialize LifeSpan AI"""
self.model = None
self.scaler = StandardScaler()
self.biomarkers = [
"血圧収縮期", "血圧拡張期", "BMI", "体脂肪率", "筋肉量",
"テロメア長", "グルコース", "インスリン", "HbA1c",
"総コレステロール", "HDL", "LDL", "中性脂肪",
"炎症マーカーCRP", "ビタミンD", "コルチゾール",
"睡眠時間", "日平均歩数", "ストレススコア"
]
# Train the model
self._train_longevity_model()
def _generate_synthetic_data(self, n_samples=1000):
"""Generate synthetic data for training"""
np.random.seed(42)
# Generate data for population aged 20-80
ages = np.random.normal(50, 15, n_samples).clip(20, 80)
# Generate biomarker data
data = {}
# Reflect tendency for biomarkers to worsen with age
data["血圧収縮期"] = 110 + ages * 0.5 + np.random.normal(0, 10, n_samples)
data["血圧拡張期"] = 70 + ages * 0.2 + np.random.normal(0, 7, n_samples)
data["BMI"] = 22 + ages * 0.05 + np.random.normal(0, 3, n_samples)
data["体脂肪率"] = 15 + ages * 0.1 + np.random.normal(0, 5, n_samples)
data["筋肉量"] = 45 - ages * 0.2 + np.random.normal(0, 5, n_samples)
# Telomere length has strong negative correlation with age
data["テロメア長"] = 10 - ages * 0.1 + np.random.normal(0, 0.5, n_samples)
data["グルコース"] = 85 + ages * 0.2 + np.random.normal(0, 10, n_samples)
data["インスリン"] = 5 + ages * 0.1 + np.random.normal(0, 2, n_samples)
data["HbA1c"] = 5 + ages * 0.01 + np.random.normal(0, 0.3, n_samples)
data["総コレステロール"] = 170 + ages * 0.5 + np.random.normal(0, 20, n_samples)
data["HDL"] = 60 - ages * 0.1 + np.random.normal(0, 10, n_samples)
data["LDL"] = 100 + ages * 0.5 + np.random.normal(0, 20, n_samples)
data["中性脂肪"] = 100 + ages * 0.7 + np.random.normal(0, 30, n_samples)
data["炎症マーカーCRP"] = 0.5 + ages * 0.03 + np.random.normal(0, 0.5, n_samples).clip(0, 10)
data["ビタミンD"] = 40 - ages * 0.2 + np.random.normal(0, 10, n_samples)
data["コルチゾール"] = 12 + ages * 0.05 + np.random.normal(0, 3, n_samples)
# Healthy habits often have negative correlation with age
data["睡眠時間"] = 8 - ages * 0.01 + np.random.normal(0, 1, n_samples)
data["日平均歩数"] = 10000 - ages * 50 + np.random.normal(0, 2000, n_samples)
data["ストレススコア"] = 3 + ages * 0.05 + np.random.normal(0, 2, n_samples)
# Calculate predicted lifespan (based on biomarkers)
# Base lifespan is 85, add the influence of each biomarker
lifespan = 85 + \
-0.1 * (data["血圧収縮期"] - 120).clip(0, 100) + \
-0.1 * (data["血圧拡張期"] - 80).clip(0, 50) + \
-0.5 * (data["BMI"] - 25).clip(0, 20) + \
-0.2 * (data["体脂肪率"] - 20).clip(0, 40) + \
0.2 * (data["筋肉量"] - 30).clip(0, 30) + \
2.0 * (data["テロメア長"] - 5).clip(-5, 10) + \
-0.05 * (data["グルコース"] - 85).clip(0, 200) + \
-0.2 * (data["インスリン"] - 5).clip(0, 50) + \
-2.0 * (data["HbA1c"] - 5.7).clip(0, 10) + \
-0.02 * (data["総コレステロール"] - 200).clip(0, 300) + \
0.1 * (data["HDL"] - 40).clip(-40, 60) + \
-0.03 * (data["LDL"] - 100).clip(0, 200) + \
-0.01 * (data["中性脂肪"] - 150).clip(0, 1000) + \
-2.0 * (data["炎症マーカーCRP"] - 1).clip(0, 20) + \
0.1 * (data["ビタミンD"] - 30).clip(-30, 70) + \
-0.5 * (data["コルチゾール"] - 15).clip(0, 30) + \
0.5 * (data["睡眠時間"] - 7).clip(-7, 3) + \
0.001 * (data["日平均歩数"] - 5000).clip(-5000, 15000) + \
-0.5 * (data["ストレススコア"] - 5).clip(0, 10) + \
np.random.normal(0, 3, n_samples) # Random element
# Limit to realistic range
lifespan = lifespan.clip(60, 120)
# Convert to DataFrame
df = pd.DataFrame(data)
return df, lifespan
def _train_longevity_model(self):
"""Train the longevity prediction model"""
# Generate synthetic data
features, target = self._generate_synthetic_data(n_samples=5000)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.2, random_state=42)
# Scale features
X_train_scaled = self.scaler.fit_transform(X_train)
X_test_scaled = self.scaler.transform(X_test)
# Train random forest regression model
self.model = RandomForestRegressor(n_estimators=100, random_state=42)
self.model.fit(X_train_scaled, y_train)
# Evaluate model accuracy
score = self.model.score(X_test_scaled, y_test)
print(f"Model Accuracy (R²): {score:.4f}")
# Calculate feature importance
self.feature_importance = dict(zip(features.columns, self.model.feature_importances_))
def analyze_biomarkers(self, user_data):
"""Analyze user's biomarkers and provide lifespan prediction and improvement suggestions"""
# Convert to DataFrame
user_df = pd.DataFrame([user_data])
# Remove features not used in model training (age and gender)
user_df_model = user_df.copy()
if '年齢' in user_df_model.columns:
user_age = user_df_model['年齢'].values[0]
user_df_model = user_df_model.drop(columns=['年齢'])
else:
user_age = 40 # Default age
if '性別' in user_df_model.columns:
user_df_model = user_df_model.drop(columns=['性別'])
# Fill in missing biomarkers with average values
for biomarker in self.biomarkers:
if biomarker not in user_df_model.columns:
print(f"Warning: No data for {biomarker}. Using average value instead.")
user_df_model[biomarker] = 0
# Scale features
user_scaled = self.scaler.transform(user_df_model)
# Predict lifespan
predicted_lifespan = self.model.predict(user_scaled)[0]
# Identify which biomarkers have the most impact on lifespan
impact_analysis = {}
for biomarker in self.biomarkers:
# Consider feature importance and user's values
if biomarker in self.feature_importance:
importance = self.feature_importance[biomarker]
# Calculate deviation from normal range
if biomarker == "血圧収縮期":
deviation = (user_df_model[biomarker].values[0] - 120) / 20
elif biomarker == "血圧拡張期":
deviation = (user_df_model[biomarker].values[0] - 80) / 10
elif biomarker == "BMI":
deviation = abs(user_df_model[biomarker].values[0] - 22) / 5
elif biomarker == "テロメア長":
deviation = (5 - user_df_model[biomarker].values[0]) / 2
else:
# Apply simplified calculation for other biomarkers
deviation = 0
# Combine importance and deviation to calculate impact
impact = importance * (1 + deviation)
impact_analysis[biomarker] = impact
# Sort by impact in descending order
sorted_impact = sorted(impact_analysis.items(), key=lambda x: x[1], reverse=True)
# Identify top 3 biomarkers to improve
top_areas_to_improve = sorted_impact[:3]
# Generate improvement suggestions
improvement_suggestions = {}
for biomarker, impact in top_areas_to_improve:
if biomarker == "血圧収縮期" or biomarker == "血圧拡張期":
improvement_suggestions[biomarker] = "有酸素運動を週に3回、30分以上行うことで血圧を下げることができます。また、塩分摂取を減らし、DASH食を試してみてください。"
elif biomarker == "BMI" or biomarker == "体脂肪率":
improvement_suggestions[biomarker] = "バランスの取れた食事と定期的な運動を組み合わせて、健康的な体重を維持しましょう。急激なダイエットは避け、1週間に0.5kgの減量を目指してください。"
elif biomarker == "テロメア長":
improvement_suggestions[biomarker] = "ストレスを減らし、瞑想や十分な睡眠を取ることでテロメアの短縮を遅らせることができます。また、抗酸化物質が豊富な食品を摂ることも効果的です。"
elif biomarker == "グルコース" or biomarker == "インスリン" or biomarker == "HbA1c":
improvement_suggestions[biomarker] = "精製炭水化物や砂糖の摂取を減らし、低GI食品を選びましょう。食事の前に少し運動をすると、インスリン感受性が向上します。"
elif biomarker in ["総コレステロール", "HDL", "LDL", "中性脂肪"]:
improvement_suggestions[biomarker] = "オメガ3脂肪酸が豊富な魚を週に2回以上食べ、トランス脂肪酸と飽和脂肪酸を減らしましょう。オリーブオイルなどの健康的な油を使用することも効果的です。"
elif biomarker == "炎症マーカーCRP":
improvement_suggestions[biomarker] = "慢性炎症を減らすために、抗炎症作用のある食品(ターメリック、生姜、ベリー類など)を摂り、十分な運動と睡眠を確保しましょう。"
elif biomarker == "ビタミンD":
improvement_suggestions[biomarker] = "適切な日光浴(UVインデックスに注意)と、ビタミンDが豊富な食品(脂の多い魚、強化乳製品など)を摂ることで、レベルを上げることができます。"
elif biomarker == "睡眠時間":
improvement_suggestions[biomarker] = "7〜8時間の質の高い睡眠を目指しましょう。就寝前の青色光を避け、一貫した睡眠スケジュールを維持することが重要です。"
elif biomarker == "日平均歩数":
improvement_suggestions[biomarker] = "毎日の目標を1,000歩ずつ増やし、最終的に10,000歩を目指しましょう。デスクワークの合間に短い散歩を取り入れるのも効果的です。"
elif biomarker == "ストレススコア":
improvement_suggestions[biomarker] = "マインドフルネス瞑想、深呼吸、ヨガなどのリラクゼーション技術を日常に取り入れましょう。ストレスの原因を特定し、可能であれば排除することも重要です。"
else:
improvement_suggestions[biomarker] = f"{biomarker}を改善するために、専門家に相談することをお勧めします。"
# Return analysis results
results = {
"予測寿命": round(predicted_lifespan, 1),
"現在の年齢からの余命": round(predicted_lifespan - user_age, 1),
"改善すべき重要なバイオマーカー": [item[0] for item in top_areas_to_improve],
"改善提案": improvement_suggestions,
"バイオマーカーの影響度": dict(sorted_impact)
}
return results
def visualize_longevity_potential(self, current_prediction, optimized_prediction):
"""Visualize longevity extension potential"""
labels = ['Current Predicted Lifespan', 'Optimized Lifespan']
values = [current_prediction, optimized_prediction]
gain = optimized_prediction - current_prediction
plt.figure(figsize=(10, 6))
bars = plt.bar(labels, values, color=['skyblue', 'lightgreen'])
plt.title('Longevity Extension Potential Analysis', fontsize=16)
plt.ylabel('Predicted Lifespan (years)', fontsize=12)
plt.ylim(0, max(values) * 1.2)
# Display values above bars
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height + 1,
f'{height:.1f} yrs', ha='center', va='bottom')
# Show lifespan increase with arrow
plt.annotate(f'+{gain:.1f} yrs',
xy=(1, current_prediction),
xytext=(1, current_prediction + gain/2),
arrowprops=dict(facecolor='green', shrink=0.05),
ha='center', fontsize=14)
plt.tight_layout()
plt.show()
def simulate_intervention_effects(self, user_data):
"""Simulate intervention effects"""
# Current prediction
current_results = self.analyze_biomarkers(user_data)
current_lifespan = current_results["予測寿命"]
# Create optimized data based on biomarkers that need improvement
optimized_data = user_data.copy()
# Optimize top 3 biomarkers
for biomarker in current_results["改善すべき重要なバイオマーカー"]:
if biomarker == "血圧収縮期":
optimized_data[biomarker] = 120 # Ideal value
elif biomarker == "血圧拡張期":
optimized_data[biomarker] = 80
elif biomarker == "BMI":
optimized_data[biomarker] = 22
elif biomarker == "体脂肪率":
# Set optimal value based on gender
if '性別' in user_data and user_data['性別'] == "女性":
optimized_data[biomarker] = 22
else:
optimized_data[biomarker] = 15
elif biomarker == "テロメア長":
# Improve current value by 20%
optimized_data[biomarker] = user_data[biomarker] * 1.2
elif biomarker == "グルコース":
optimized_data[biomarker] = 85
elif biomarker == "HbA1c":
optimized_data[biomarker] = 5.2
elif biomarker == "総コレステロール":
optimized_data[biomarker] = 180
elif biomarker == "HDL":
optimized_data[biomarker] = 60
elif biomarker == "LDL":
optimized_data[biomarker] = 100
elif biomarker == "中性脂肪":
optimized_data[biomarker] = 100
elif biomarker == "炎症マーカーCRP":
optimized_data[biomarker] = 0.5
elif biomarker == "ビタミンD":
optimized_data[biomarker] = 50
elif biomarker == "睡眠時間":
optimized_data[biomarker] = 8
elif biomarker == "日平均歩数":
optimized_data[biomarker] = 10000
elif biomarker == "ストレススコア":
optimized_data[biomarker] = 2
# Predict with optimized data
optimized_results = self.analyze_biomarkers(optimized_data)
optimized_lifespan = optimized_results["予測寿命"]
# Visualize results
self.visualize_longevity_potential(current_lifespan, optimized_lifespan)
return {
"現在の予測寿命": current_lifespan,
"最適化後の予測寿命": optimized_lifespan,
"寿命延長ポテンシャル": optimized_lifespan - current_lifespan,
"現在の分析": current_results,
"最適化後の分析": optimized_results
}
# Usage example
if __name__ == "__main__":
# Initialize LifeSpan AI
lifespan_ai = LifeSpanAI()
# Sample user data
user_data = {
"年齢": 45,
"性別": "男性",
"血圧収縮期": 135,
"血圧拡張期": 85,
"BMI": 27.5,
"体脂肪率": 24,
"筋肉量": 35,
"テロメア長": 6.2,
"グルコース": 95,
"インスリン": 7.5,
"HbA1c": 5.8,
"総コレステロール": 210,
"HDL": 45,
"LDL": 130,
"中性脂肪": 180,
"炎症マーカーCRP": 1.8,
"ビタミンD": 30,
"コルチゾール": 14,
"睡眠時間": 6.5,
"日平均歩数": 5500,
"ストレススコア": 6
}
print("===== LifeSpan AI: Longevity Analysis Report =====")
# Analyze biomarkers
results = lifespan_ai.analyze_biomarkers(user_data)
print(f"\nPredicted Lifespan: {results['予測寿命']} years")
print(f"Life Expectancy from Current Age: {results['現在の年齢からの余命']} years")
print("\nKey Biomarkers to Improve:")
for i, biomarker in enumerate(results['改善すべき重要なバイオマーカー'], 1):
print(f"{i}. {biomarker}")
print("\nImprovement Suggestions:")
for biomarker, suggestion in results['改善提案'].items():
print(f"- {biomarker}: {suggestion}")
print("\n===== Intervention Effect Simulation =====")
intervention_results = lifespan_ai.simulate_intervention_effects(user_data)
print(f"\nLifespan Extension Potential: +{intervention_results['寿命延長ポテンシャル']:.1f} years")Model Accuracy (R²): 0.8290
===== LifeSpan AI: Longevity Analysis Report =====
Predicted Lifespan: 83.1 years
Life Expectancy from Current Age: 38.1 years
Key Biomarkers to Improve:
1. テロメア長
2. 日平均歩数
3. 血圧収縮期
Improvement Suggestions:
- テロメア長: ストレスを減らし、瞑想や十分な睡眠を取ることでテロメアの短縮を遅らせることができます。また、抗酸化物質が豊富な食品を摂ることも効果的です。
- 日平均歩数: 毎日の目標を1,000歩ずつ増やし、最終的に10,000歩を目指しましょう。デスクワークの合間に短い散歩を取り入れるのも効果的です。
- 血圧収縮期: 有酸素運動を週に3回、30分以上行うことで血圧を下げることができます。また、塩分摂取を減らし、DASH食を試してみてください。
===== Intervention Effect Simulation =====
Lifespan Extension Potential: +8.0 years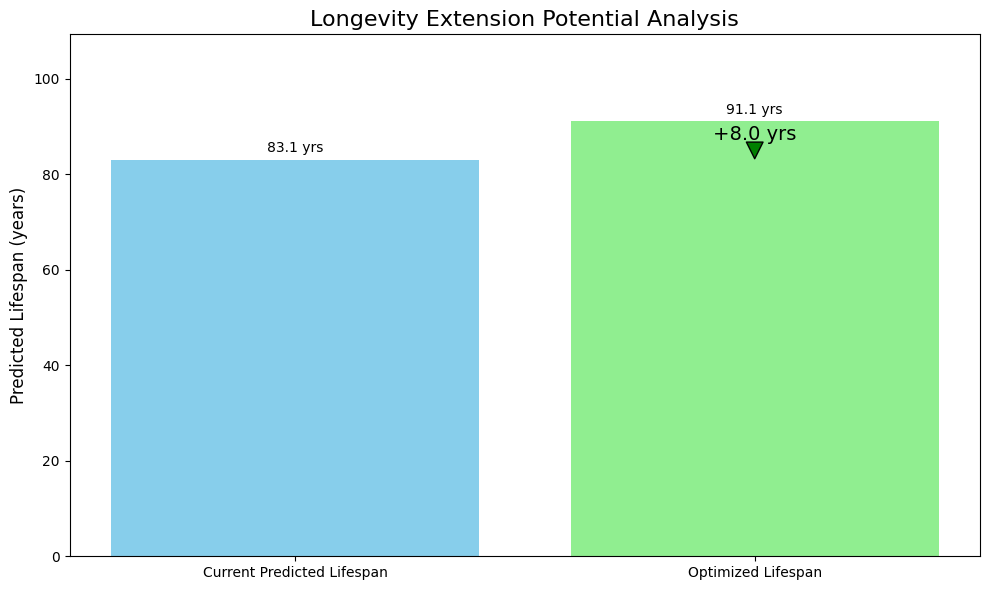
このPythonコードは、バイオマーカーデータから寿命を予測し、改善すべき健康要因と具体的な提案を提示するものです。主な機能は:
- バイオマーカーの分析: 血圧、BMI、テロメア長などの健康指標を評価
- 寿命予測: 機械学習モデル(ランダムフォレスト)を使って予測寿命を計算
- 改善提案: 最も影響力のある健康要因とその改善方法を提案
- シミュレーション: 健康改善による寿命延長効果を視覚化
実際のアプリでは、このコードをさらに発展させてテロメア検査結果や遺伝子データとの連携、ウェアラブルデバイスからのリアルタイムデータ取得などの機能を追加できます。
「不死」関連ビジネスのまとめ
カーツワイルの不死に関する予測は、科学とテクノロジーの急速な進歩が人間の寿命の限界を大きく拡張する可能性を示唆しています。AIを活用することで、この分野には多くのビジネスチャンスが生まれています。
「LifeSpan AI」、「MindVault」、「イモータルエコシステム」などのビジネスモデルは、人間の寿命延長とデジタル不死という新たな市場を切り開く可能性があります。これらのプラットフォームは、個人の健康データを活用して、寿命を最大化する個別の推奨事項を提供できます。
一方で、こうした技術やサービスは倫理的な懸念や社会的な不平等をもたらす可能性があることも忘れてはなりません。不死技術へのアクセスが平等に提供されるか、個人データのプライバシー、人間のアイデンティティの本質などの問題に対処する必要があります。
不死の実現可能性については議論の余地がありますが、健康寿命の延長と生活の質の向上は現在の技術でも達成可能な目標です。AIを活用したヘルスケアソリューションは、私たちの健康状態を最適化し、より長く、より健康な生活を送るための道具となるでしょう。
私たちが不死を実現するかどうかにかかわらず、生物学的限界の探求は医学、倫理学、哲学、社会学など多くの分野にわたる興味深い旅であり、今後何十年もの間、人類の未来を形作る重要なテーマであり続けるでしょう。

▼AIを使った副業・起業アイデアを紹介♪

