
配送ルート最適化の4ステップ
Pythonを使用して配送ロボットのルートを最適化しまよう。このプロセスでは、以下のステップを踏みます。
- サンプルデータの生成:搬送すべきアイテムの位置と目的地の位置をランダムに生成します。
- データの可視化:生成したデータを可視化して、状況を理解しやすくします。
- ルート最適化のアルゴリズム:簡単なアルゴリズムを使用して、最適なルートを計算します。
- 最適化されたルートの可視化:計算された最適なルートをグラフ上に表示します。
それでは、Pythonコードを書いてみましょう。まずはサンプルデータの生成とその可視化から始めます。
import matplotlib.pyplot as plt
import numpy as np
import random
from itertools import permutations
# パラメータ設定
num_points = 5 # アイテム数
x_range = (0, 100) # x座標の範囲
y_range = (0, 100) # y座標の範囲
# サンプルデータ生成 (アイテムの初期位置と目的地)
start_points = [(random.randint(*x_range), random.randint(*y_range)) for _ in range(num_points)]
end_points = [(random.randint(*x_range), random.randint(*y_range)) for _ in range(num_points)]
# データの可視化
plt.figure(figsize=(10, 6))
plt.scatter(*zip(*start_points), c='blue', label='Start Points')
plt.scatter(*zip(*end_points), c='red', label='End Points')
plt.title('Sample Data for Transport Robot Route Optimization')
plt.xlabel('X Coordinate')
plt.ylabel('Y Coordinate')
plt.legend()
plt.grid(True)
plt.show()
# 生成されたデータを表示
start_points, end_points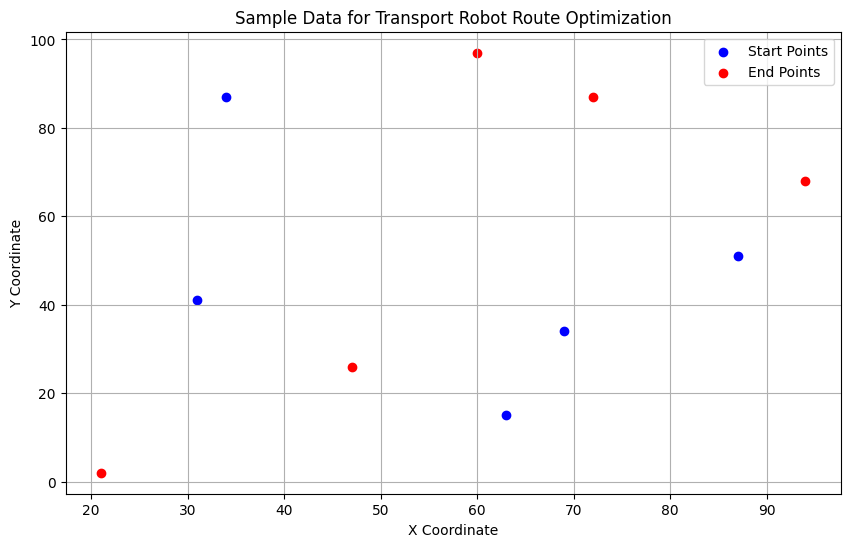
サンプルデータが生成され、可視化されました。このデータには、5つのアイテムの初期位置(青い点)とそれぞれの目的地(赤い点)が含まれています。
次に、ルートを最適化するアルゴリズムを考えます。この例では、全組み合わせを試して最短ルートを見つけるシンプルな方法を採用します。距離の計算にはユークリッド距離(2点間の直線距離)を使用します。
計算された最適なルートを可視化することで、ロボットがどのようにアイテムを運ぶべきかを示します。
それでは、最適化アルゴリズムとその結果の可視化のコードを記述しましょう。
def calculate_total_distance(route, start_points, end_points):
""" 経路の合計距離を計算する """
total_distance = 0
for i in range(len(route)):
start = start_points[route[i]]
end = end_points[route[i]]
distance = np.sqrt((start[0] - end[0])**2 + (start[1] - end[1])**2)
total_distance += distance
return total_distance
# 全経路の生成と評価
routes = list(permutations(range(num_points)))
min_distance = float('inf')
optimal_route = None
for route in routes:
distance = calculate_total_distance(route, start_points, end_points)
if distance < min_distance:
min_distance = distance
optimal_route = route
# 最適なルートの可視化
plt.figure(figsize=(10, 6))
for i in optimal_route:
plt.plot([start_points[i][0], end_points[i][0]], [start_points[i][1], end_points[i][1]], 'k--')
plt.scatter(*zip(*start_points), c='blue', label='Start Points')
plt.scatter(*zip(*end_points), c='red', label='End Points')
plt.title('Optimized Route for Transport Robot')
plt.xlabel('X Coordinate')
plt.ylabel('Y Coordinate')
plt.legend()
plt.grid(True)
plt.show()
# 最適なルートとその総距離
optimal_route, min_distance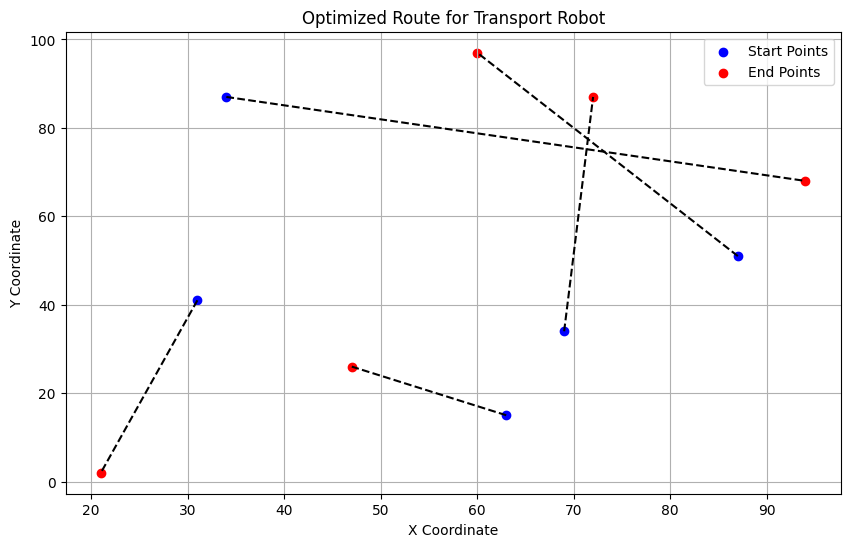
((0, 4, 1, 2, 3), 298.44327533025313)最適なルートが計算され、その結果が可視化されました。このグラフには、配送ロボットがたどるべきルートが黒い点線で示されています。アイテムの初期位置(青い点)から目的地(赤い点)への各経路が描画されています。
計算された最適なルートは (0, 4, 1, 2, 3) で、これはアイテムをこの順番で運ぶことを意味します。このルートの合計距離は約 298.44 単位です。
このシンプルな方法では、アイテムの数が多くなると計算量がとても大きくなります。実際のアプリケーションでは、より効率的なアルゴリズム(例えば巡回セールスマン問題の解法など)を検討する必要があります。
配送ロボットのルートを最適化
配送ロボットのルートを最適化するために、人工知能(AI)モデルを使用する一般的なアプローチは、強化学習(Reinforcement Learning, RL)です。強化学習では、エージェント(この場合はロボット)が環境からフィードバック(報酬)を受け取り、最適な行動を学習します。
- 環境: ロボットが動作する空間(アイテムの位置、目的地など)
- エージェント: ルートを決定する配送ロボット
- 状態: 現在のロボットの位置と未運搬のアイテム
- 行動: 次に運搬するアイテムを選択する
- 報酬: 短いルートでアイテムを運搬した場合に高い報酬を与える
強化学習アルゴリズムの例
- Q-Learning: 単純で効果的なオフポリシー(Off-policy)強化学習アルゴリズム。Qテーブルを用いて最適な行動を学習します。
- Deep Q-Network (DQN): Q-Learningにニューラルネットワークを組み合わせたもの。複雑な状態空間に対応できます。
Q-Learningに基づくルート最適化
以下は、Q-Learningを使用した基本的なルート最適化のサンプルコードです。このコードはシンプルな例であり、実際の実装ではより複雑な状況を考慮する必要があります。
注意点
- 実際の実装では、環境の設定や状態遷移のロジックが重要ですが、ここでは簡易版を紹介します。
- 強化学習モデルの訓練には時間がかかるため、この例では実際の訓練プロセスを省略します。
コードの記述に先立ち、必要なライブラリ(numpy など)をインポートします。また、環境を模擬するクラスとQ-Learningエージェントを定義します。
import numpy as np
class RouteEnvironment:
""" ルート最適化環境のクラス """
def __init__(self, start_points, end_points):
self.start_points = start_points
self.end_points = end_points
self.num_points = len(start_points)
self.state = None
self.reset()
def reset(self):
""" 環境をリセットする """
self.state = np.zeros(self.num_points, dtype=int) # 未運搬のアイテムを示す
return self.state
def step(self, action):
""" 行動を実行し、次の状態と報酬を返す """
if self.state[action] == 1:
# すでに運搬されているアイテムを選んだ場合
return self.state, -10 # ペナルティ
self.state[action] = 1 # アイテムを運搬済みにする
reward = -np.linalg.norm(np.array(self.start_points[action]) - np.array(self.end_points[action]))
done = np.all(self.state) # すべてのアイテムが運搬されたか
return self.state, reward, done
class QLearningAgent:
""" Q-Learningエージェントのクラス """
def __init__(self, num_states, num_actions, learning_rate=0.1, discount_factor=0.9, epsilon=0.1):
self.q_table = np.zeros((num_states, num_actions))
self.learning_rate = learning_rate
self.discount_factor = discount_factor
self.epsilon = epsilon
self.num_actions = num_actions
def choose_action(self, state):
""" ε-greedyに基づいて行動を選択する """
if np.random.rand() < self.epsilon:
return np.random.randint(self.num_actions)
else:
return np.argmax(self.q_table[state])
def learn(self, state, action, reward, next_state):
""" Qテーブルを更新する """
predict = self.q_table[state, action]
target = reward + self.discount_factor * np.max(self.q_table[next_state])
self.q_table[state, action] += self.learning_rate * (target - predict)
# 環境とエージェントのインスタンス化(サンプルデータを使用)
env = RouteEnvironment(start_points, end_points)
agent = QLearningAgent(num_states=2**num_points, num_actions=num_points)
# エージェントのQテーブル(初期状態)
agent.q_table[:10] # 最初の10行を表示array([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])上記のコードは、Q-Learningを使用した配送ロボットのルート最適化のための環境と、エージェントの基本的なセットアップの部分です。
コードの解説
- RouteEnvironment: ルート最適化のための環境をシミュレートします。各状態は、運搬されたアイテムを表すバイナリ配列で表現されます。行動(action)は次に運搬するアイテムを指定し、状態を更新し、報酬を計算します。
- QLearningAgent: Q-Learningに基づくエージェントです。Qテーブルは各状態と行動のペアに対する価値を保持します。エージェントはε-greedy方策に従い行動を選択し、Qテーブルを学習します。
訓練プロセス
実際の訓練では、以下のステップを繰り返します。
- 状態の初期化: 環境をリセットし、初期状態を取得します。
- 行動の選択: エージェントが現在の状態に基づいて行動を選択します。
- 環境の更新: 選択された行動を環境に適用し、新しい状態と報酬を取得します。
- 学習: エージェントがQテーブルを更新します。
このプロセスは、エージェントが十分に学習するまで繰り返されます。ただし、このコードは実際の訓練プロセスを省略しています。
配送ロボットのルート最適化問題に強化学習、特にQ-Learningモデルを選択した理由は複数あります。以下に主な理由を詳細に説明します。
実際の応用では、環境のモデリング、状態遷移のロジック、報酬関数の設計が重要です。また、より複雑な問題ではDeep Q-Network(DQN)などの高度な強化学習アルゴリズムの使用を検討する必要があります。
Q-Learningモデルを選択した理由
強化学習は、ルート最適化だけでなく、多くの意思決定問題に応用できます。特に動的な環境や不確実性の高い状況において有効です。
1. 強化学習の適合性
強化学習(RL)は、エージェントが環境との相互作用を通じて最適な方策を学習する問題に特に適しています。ルート最適化は、エージェント(ロボット)が一連の決定(どのアイテムをいつ運ぶか)を通じて目標(全アイテムの効率的な運搬)を達成する問題です。これは、強化学習が解決する典型的なシナリオです。
2. 環境の不確実性と動的な状況
実際の工場や倉庫では、環境は常に変化し、予測不可能な要素が存在します。例えば、障害物の出現、他のロボットや作業員の動き、緊急のタスクなどです。強化学習は、このような動的かつ不確実な環境での意思決定に強いです。学習された方策は、未知の状況や変化に適応する能力を持ちます。
3. Q-Learningのシンプルさと効果性
Q-Learningは、強化学習のアルゴリズムの中でも比較的理解しやすく、実装が容易です。このアルゴリズムは、各状態と行動のペアに価値(Q値)を割り当て、最適な行動選択を学習します。基本的なルート最適化問題に対しては、Q-Learningだけで十分な効果が得られる場合が多いです。
4. 拡張性と柔軟性
Q-Learningとその派生形(例えばDeep Q-Networks)は、問題の複雑性が増すにつれて拡張可能です。ニューラルネットワークを組み込むことで、より高次元の状態空間や複雑な意思決定プロセスを扱うことができます。したがって、基本的なQ-Learningから始めて、必要に応じてモデルを拡張できます。
5. 実用性と産業応用
強化学習は、物流、製造、倉庫管理など多くの産業分野で実用的な応用が見られます。ロボットのルート最適化は、これらの分野における典型的な応用例であり、強化学習を用いることで、実際の動作環境に近い条件下での学習と評価が可能になります。
結論
これらの理由から、強化学習、特にQ-Learningは、配送ロボットのルート最適化問題に適した選択肢と言えます。シンプルでありながら、不確実性や動的な環境下での意思決定能力を備えており、実際の産業応用に向けた強力なツールを提供します。
ChatGPTとの連携
ChatGPTを配送ロボットのルート最適化と連携することは、ユーザーインターフェースの強化や意思決定に役立つ可能性があります。具体的には、以下のような機能を実装できます。
1. ユーザーインタラクションの追加
ChatGPTを利用して、ユーザーからの指示や情報を受け取り、その情報に基づいてルート最適化のパラメータを調整します。例えば、緊急の配送要求や特定のアイテムの優先順位の変更などです。
2. 動的なフィードバックの統合
環境やロボットの状態に関するリアルタイムのフィードバックを受け取り、その情報を基にルートを動的に再計算できます。例えば、特定のエリアでの障害物の発生や他のロボットとの衝突回避などです。
具体的なコードの例
以下は、ChatGPTを使ったユーザーインターフェースとルート最適化の基本的な統合例です。この例では、ユーザーからの簡単な指示を受け取り、ルート最適化のパラメータを変更します。
# ChatGPTとのインターフェースを模擬する関数
def chat_with_user():
# ここでは単純なテキストベースの入力を想定
user_input = input("Enter your command (e.g., 'change priority', 'add obstacle'): ")
return user_input
# ユーザーからの指示に応じてルート最適化を調整する関数
def adjust_route_based_on_input(user_input, route_optimizer):
if "change priority" in user_input:
# アイテムの優先順位を変更するなどの処理
pass
elif "add obstacle" in user_input:
# 環境に障害物を追加するなどの処理
pass
# その他の調整をここで行う
# ユーザーとの対話を開始
user_input = chat_with_user()
# ユーザーの入力に基づいてルート最適化を調整
adjust_route_based_on_input(user_input, route_optimizer)注意点
- これはあくまで概念的な例であり、実際にはChatGPTのAPIを介してより高度な自然言語処理との統合が必要です。
- ユーザーの指示を処理するロジックは、具体的なアプリケーションや要件に応じて大幅に異なる可能性があります。
- 実際の環境では、ユーザーの入力を安全かつ効果的に処理するための追加のチェックやバリデーションが必要になるでしょう。
ビジネスアイデア
配送ロボットのルート最適化に使用されるアプローチ、分析、および最適化技術は、多岐にわたる分野で応用できます。以下は、これらの技術を同分野や他分野のビジネスに応用するいくつかのアイデアです。
同分野における応用
- 倉庫管理と物流: 強化学習を用いて、倉庫内の商品のピッキングや配送ルートの最適化を行う。これにより、時間と労力を削減し、全体的な効率を向上させる。
- スマート工場: 製造ラインにおける機械の動きや資材の運搬を最適化し、生産効率を高める。動的な環境に対応するため、リアルタイムのデータと組み合わせる。
- 在庫管理: データ駆動型のアプローチを用いて在庫レベルを最適化し、過剰在庫や品切れを防ぐ。
他分野への応用
- 交通システムの最適化: 都市の交通流を最適化するために、これらの技術を応用。交通渋滞を減らし、環境への影響を最小限に抑える。
- ヘルスケアにおけるリソース配分: 病院やクリニックでの患者のフローと医療リソースの配分を最適化。待ち時間を減らし、患者の満足度を向上させる。
- スマートシティの開発: エネルギー利用、廃棄物管理、公共サービスの配布など、都市インフラのさまざまな側面を最適化。
- 金融サービス: 投資ポートフォリオの管理、リスク評価、市場の動向予測など、金融分野における意思決定を支援。
- 小売業の顧客体験向上: 顧客データと購買パターンを分析し、パーソナライズされたショッピング体験を提供。
これらのアイデアは、最新のテクノロジーとビジネスを統合することで、効率化、コスト削減、顧客満足度を向上させます。Pythonと機械学習、人工知能(AI)、ChatGPTなどを組み合わせることで、競争上の優位性を確保できます。

▼AIを使った副業・起業アイデアを紹介♪

