
AIエンジニアやプログラマーに転職して、偏頭痛の治療法を開発しましょう。最近の研究によると、脳のリンパ系が片頭痛の痛みに関与していることがわかりました。
具体的なPythonコードやAI技術の解説も行うので、AIエンジニアやプログラマーに転職したい方には必読の内容です。
また、この技術を応用したビジネスやアイデアも紹介しますので、新しい視点や発想を得られますよ。
片頭痛は脳のリンパ系が関与?

UNCの研究者は、脳のリンパ系が片頭痛の痛みに与える影響を発見しました。この結果、片頭痛が引き起こされるメカニズムの一部が解明されたということです。
今後、片頭痛および脳のリンパ系の関係をさらに詳しく研究する予定です。片頭痛が女性に多い理由の研究も進むそうです。
AIで偏頭痛の治療法を開発:利用されるIT技術
偏頭痛の治療法開発に利用される主なIT技術を挙げてみましょう。
- プログラム言語
Python: AIや機械学習のモデル作成に広く使用される言語。ライブラリが豊富で、特にデータサイエンス分野での利用が多い。
R: 統計分析やデータ解析に特化した言語。医療データの解析にも使用される。 - AI技術
機械学習: 偏頭痛の発生パターンを予測し、適切な治療方法を提案するために使用される。
ディープラーニング: 脳波や神経活動のデータを分析し、偏頭痛の原因を特定する高度な解析に使用される。 - データベース技術
SQL: データの保存、検索、管理に使用される標準的なデータベース言語。大規模な医療データの処理に適している。
NoSQL: 大量の非構造化データの処理に適したデータベース。リアルタイムデータの処理や分散データベースに使用される。 - クラウド技術
AWS(Amazon Web Services): データストレージ、コンピューティングリソース、AIサービスの提供に利用されるクラウドプラットフォーム。
Google Cloud Platform (GCP): 機械学習モデルのトレーニングとデプロイメントに使用されるクラウドサービス。特にGoogle AIツールキットを利用可能。 - セキュリティ対策
データ暗号化: 医療データの安全性を確保するために、データの保存および転送時に暗号化技術が使用される。
アクセス制御: データへのアクセスを厳密に管理し、認可されたユーザーのみがデータにアクセスできるようにするセキュリティ手法。
各IT技術を駆使して、偏頭痛の研究が効果的かつ安全に行われています。
PythonとAIで偏頭痛の治療法を開発
PythonとAIで、偏頭痛の治療法を開発するコードを書いてみましょう。
- データ生成:
numpyを使ってサンプルデータを生成します。偏頭痛の発生頻度といくつかの関連変数(例:睡眠時間、ストレスレベル)を含むデータを作成します。 - データの前処理:
pandasを使ってデータフレームを作成し、データの基本的な確認と前処理を行います。 - 機械学習モデルのトレーニング:
scikit-learnのtrain_test_splitを使ってデータをトレーニングセットとテストセットに分割します。
ランダムフォレストモデルを使って予測モデルを構築します。 - モデルの評価:
モデルの精度を確認し、結果をプロットします。
以下がPythonコードです。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# Generate sample data
np.random.seed(42)
data_size = 100
data = {
'Migraine_Frequency': np.random.randint(0, 10, data_size), # 0 to 9 times per month
'Sleep_Hours': np.random.normal(7, 1.5, data_size), # Average sleep hours per night
'Stress_Level': np.random.randint(1, 10, data_size), # Stress level from 1 to 10
'Age': np.random.randint(20, 60, data_size), # Age of the participant
'Exercise_Frequency': np.random.randint(0, 7, data_size) # Exercise frequency per week
}
# Create DataFrame
df = pd.DataFrame(data)
# Define target variable and features
X = df.drop('Migraine_Frequency', axis=1)
y = df['Migraine_Frequency']
# Split data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train Random Forest model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print('Confusion Matrix:')
print(conf_matrix)
# Plotting the confusion matrix
plt.figure(figsize=(10, 7))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
# Feature importance
feature_importances = pd.Series(model.feature_importances_, index=X.columns)
feature_importances.sort_values().plot(kind='barh')
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.title('Feature Importances in Random Forest Model')
plt.show()Accuracy: 0.2
Confusion Matrix:
[[0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 0 0 1 0 0]
[1 1 0 0 0 0 0 0 0 1]
[1 0 0 0 0 0 0 0 0 1]
[0 1 0 0 1 0 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 1 0 0 0 1 0 1 0]
[0 0 0 1 0 0 0 1 0 0]
[1 0 0 0 0 0 1 0 0 1]
[0 0 0 0 1 0 0 1 0 0]]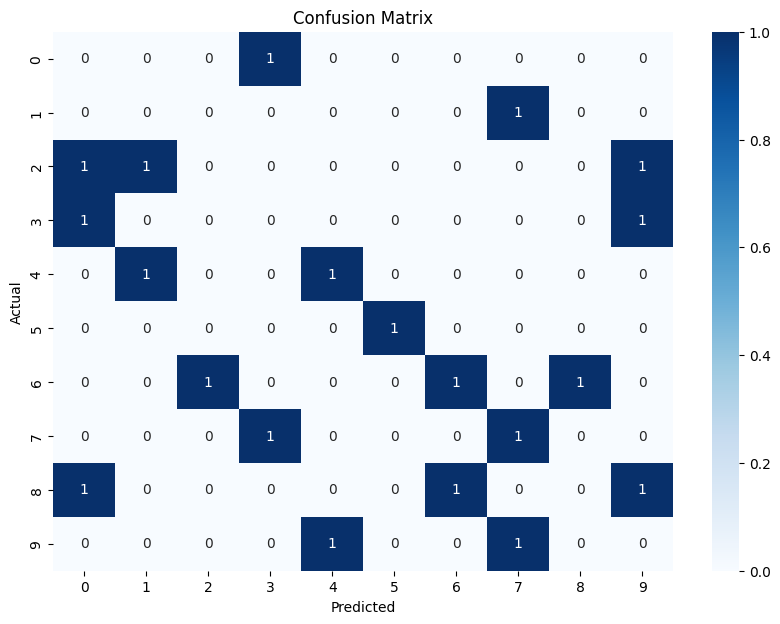
コードの解説
- データ生成:
np.random.seed(42)で乱数生成のシードを設定し、再現性を確保しています。
サンプルデータとして、偏頭痛の発生頻度(Migraine_Frequency)、睡眠時間(Sleep_Hours)、ストレスレベル(Stress_Level)、年齢(Age)、運動頻度(Exercise_Frequency)を生成しています。 - データの前処理:
pandasを使ってデータフレームを作成し、目標変数(Migraine_Frequency)と特徴量(他の変数)に分けています。 - 機械学習モデルのトレーニング:
データをトレーニングセットとテストセットに分割し、ランダムフォレストモデルをトレーニングしています。 - モデルの評価:
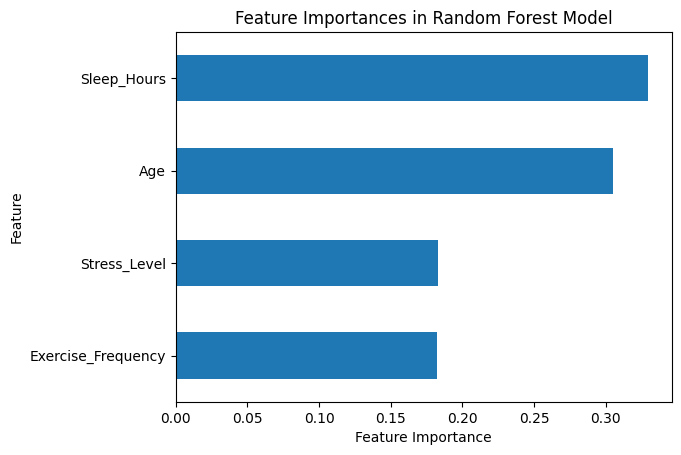
モデルの精度を評価し、混同行列を表示しています。seabornを使って混同行列のヒートマップをプロットし、特徴量の重要度をプロットしています。
上記のようなPythonコードは、偏頭痛の予測と治療法の開発に役立ちます。
AIで偏頭痛の治療法を開発:応用アイデア
AIで偏頭痛の治療法を開発する技術の、応用アイデアを考えてみましょう。
同業種への応用アイデア
- 他の慢性疾患の予測と治療:
偏頭痛だけでなく、糖尿病や心疾患など他の慢性疾患の予測と治療にAIを応用する。
患者データを用いた個別化医療の提供。 - 薬の効果と副作用の予測:
新薬の効果や副作用の事前に予測するために、AIを利用してデータを分析する。
臨床試験データの解析による迅速な薬の評価。 - 患者モニタリングシステム:
ウェアラブルデバイスを用いて、患者の健康状態をリアルタイムでモニタリングし、異常の早期に検知するシステムの開発。
他業種への応用アイデア
- 金融業界でのリスク管理:
AIを活用して市場の動向を予測し、リスクを最小限に抑える投資戦略を立てる。
顧客の信用リスクの評価と詐欺検出システムの強化。 - 小売業での需要予測:
顧客の購買データを解析して、商品の需要を予測し、在庫管理を最適化する。
個別顧客に合わせたマーケティング戦略の立案。 - 製造業での品質管理:
製造プロセスのデータをリアルタイムで解析し、品質の問題を早期に検出して改善するシステムの導入。
生産ラインの効率化と故障予測によるメンテナンスコストの削減。 - 物流業界でのルート最適化:
AIを用いて配送ルートを最適化し、コスト削減と配達時間の短縮を実現する。
物流センターの効率的な管理と自動化。 - エネルギー業界での消費予測:
エネルギー消費データを解析して、供給と需要のバランスを最適化し、エネルギー効率を向上させる。
再生可能エネルギーの利用促進とコスト削減。
AIで偏頭痛を治療する技術は、さまざまな分野に応用できそうですね。まさに、早い者勝ちのビジネスチャンスです。
AIで偏頭痛の治療法を開発:まとめ
AIで、偏頭痛を研究する方法について解説しました。AIエンジニアやプログラマーに転職を考えている方の参考になったと思います。
また、同業種や他業種への応用アイデアも紹介しました。
あなたもAIエンジニアやプログラマーに転職して、偏頭痛の治療法を開発しましょう。これからの時代、病気を治すのは医者ではなく、AIエンジニアです。

IT起業家
▼AIを使った副業・起業アイデアを紹介♪

