
はじめに
IoT技術と農業の結びつき
近年、IoT(Internet of Things)技術は多くの産業に大きな変化をもたらしています。IoTデバイスは、土壌の湿度、気温、日照時間など、畑や農地のさまざまな要因をリアルタイムで監視できるようになりました。IoTデバイスにより、農家は適切な時期に適切な量の水を提供することで、作物の成長を最適化できます。また、IoTセンサーは病気や害虫の発生を早期に検出できるので、農作物の収穫量や品質の向上が期待されています。
本記事の目的
Pythonを使用して農業IoTデータを可視化し、分析する方法について説明します。具体的には、IoTセンサーから収集されたデータの前処理、可視化、そして予測モデルの構築までの一連の流れをマスターできます。さらに、実際の農業現場でのIoT技術の応用例や、AI技術との組み合わせによる可能性についても解説します。
農業IoTデータの収集と前処理
必要なライブラリのインポートと解説
IoTデータの分析や可視化のためには、Pythonでいくつかのライブラリを使用することが一般的です。以下は、この記事で使用する主なライブラリのインポートと、それぞれの概要です。
import pandas as pd # データの操作や分析を助けるライブラリ
import numpy as np # 数学的な計算のためのライブラリ
import matplotlib.pyplot as plt # データの可視化ライブラリIoTデータのサンプルデータの作成
実際のIoTデータの収集や保存の詳細は様々ですが、ここではシンプルなサンプルデータを作成して、分析の基本的な流れを解説します。
# サンプルデータの作成
date_rng = pd.date_range(start='2020-01-01', end='2020-01-10', freq='H')
df = pd.DataFrame(date_rng, columns=['date'])
df['temp'] = np.random.randint(0,35,size=(len(date_rng)))
df['humidity'] = np.random.randint(20,100,size=(len(date_rng)))上記のコードでは、2020年1月1日から10日間の1時間ごとの気温と湿度のデータをランダムに生成しています。
IoTデータの前処理と解説
IoTデータはリアルタイムで大量に収集されるため、欠損値や外れ値が含まれることがあります。不要なデータを除外する前処理は、分析の正確性を高めるためにとても重要です。
- 欠損値の処理:
df.dropna(inplace=True)- 外れ値の検出と処理:
外れ値の定義や検出方法は多岐にわたりますが、ここではIQR(四分位範囲)を使用して表示します。
Q1 = df['temp'].quantile(0.25)
Q3 = df['temp'].quantile(0.75)
IQR = Q3 - Q1
filter = (df['temp'] >= Q1 - 1.5 * IQR) & (df['temp'] <= Q3 + 1.5 *IQR)
df = df[filter]前処理によってデータの品質を確保することで、後続の分析やモデルの精度を向上させます。
IoTデータの可視化
時系列データの可視化
IoTデータ、特に農業センサーからのデータは、時間の経過とともに収集されるため、時系列データとしての性質を持ちます。ここでは、Pythonを使用して時系列データをどのように可視化するかを解説します。
- ライブラリのインポート:
import pandas as pd
import matplotlib.pyplot as plt- サンプルデータの読み込み:
ここでは、気温や湿度などの時系列データを持つサンプルデータフレームを使用します。
# サンプルデータの作成
date_rng = pd.date_range(start='2020-01-01', end='2020-01-10', freq='H')
df = pd.DataFrame(date_rng, columns=['date'])
df['temp'] = np.random.randint(0,35,size=(len(date_rng)))
df['humidity'] = np.random.randint(20,100,size=(len(date_rng)))- データのプロット:
Matplotlibを使用してデータをプロットします。以下は気温の時間変動を示す例です。
plt.figure(figsize=(15,7))
plt.plot(df['date'], df['temp'], label='Temperature', color='blue')
plt.xlabel('Date')
plt.ylabel('Temperature (°C)')
plt.title('Temperature Over Time')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
上記のコードを実行すると、10日間の気温の変動を示すグラフが表示されます。同様に、他のセンサーデータも可視化できます。これにより、データの変動やトレンドを簡単に把握できます。
センサーデータの地理的分布の可視化
IoTセンサーデータは、異なる地理的位置から収集されることが一般的です。農業のコンテキストでは、これらのセンサーは異なる畑やエリアに配置される可能性があります。データの地理的分布を可視化することで、特定の地域の気温、湿度、土の水分量などの変動を確認できます。ここでは、Pythonのライブラリを使用して、IoTセンサーデータの地理的分布をどのように可視化するかを解説します。
- ライブラリのインポート:
import pandas as pd
import matplotlib.pyplot as plt
import geopandas as gpd- サンプルデータの読み込み:
サンプルデータには、各センサーの地理的位置(緯度と経度)とその位置でのセンサーデータが含まれていると仮定します。
# サンプルデータの作成
data = {
'Latitude': [35.6895, 35.6804, 35.6722],
'Longitude': [139.6917, 139.7601, 139.7766],
'Temperature': [25, 27, 26],
'Humidity': [60, 65, 63]
}
df = pd.DataFrame(data)- データの地理的分布のプロット:
GeopandasとMatplotlibを使用して、センサーデータの地理的分布をプロットします。
gdf = gpd.GeoDataFrame(df, geometry=gpd.points_from_xy(df.Longitude, df.Latitude))
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
ax = world[world.name == "Japan"].plot(color='white', edgecolor='black')
gdf.plot(ax=ax, color='blue', markersize=df['Temperature']*50)
plt.title('Geographical Distribution of Sensors in Japan')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.show()
上記のコードを実行すると、センサーの地理的位置に基づいて点がプロットされ、点のサイズは気温に応じて変動します。これにより、特定の地域での気温の変動を視覚的に把握できます。同様のアプローチを使用して、湿度や他のセンサーデータも可視化できます。
データの変動と傾向の解析
IoTセンサーデータは、時間の経過とともに変動することが多いものです。これらの変動を正確に理解することは、農業の意思決定や作物の健康管理に役立ちます。ここでは、Pythonを使用して、IoTセンサーデータの変動と傾向を分析する方法を解説します。
- ライブラリのインポート:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import zscore- データの変動の確認:
まず、基本的な統計を使用してデータの変動を確認します。
# サンプルデータの作成
np.random.seed(0)
dates = pd.date_range("20230101", periods=100)
data = np.random.randn(100).cumsum()
df = pd.DataFrame(data, columns=['Value'], index=dates)
# 基本統計の表示
print(df.describe()) Value
count 100.000000
mean 5.522806
std 4.994065
min -3.778287
25% 0.799339
50% 5.788951
75% 10.094254
max 13.818803- データの変動の可視化:
次に、データの変動を時間の経過とともにプロットします。
plt.figure(figsize=(10,6))
df['Value'].plot(title='Sensor Data Over Time')
plt.xlabel('Date')
plt.ylabel('Value')
plt.grid(True)
plt.show()
- データの傾向の分析:
データの傾向を分析するために、移動平均やz-scoreなどの手法を使用します。
# 移動平均の計算
df['Rolling_Mean'] = df['Value'].rolling(window=5).mean()
# z-scoreの計算
df['Z_Score'] = zscore(df['Value'])
# 移動平均とz-scoreのプロット
plt.figure(figsize=(10,6))
df['Rolling_Mean'].plot(title='Sensor Data Trend Analysis')
plt.axhline(0, color='red', linestyle='--', label='Mean')
plt.fill_between(df.index, -2, 2, color='yellow', alpha=0.2, label='Normal Range')
plt.xlabel('Date')
plt.ylabel('Value')
plt.legend()
plt.grid(True)
plt.show()
上記のコードを実行すると、移動平均によるデータの傾向と、z-scoreを使用してデータの変動を視覚的に確認できます。これにより、異常な変動や期待外れの動きを検出できます。
IoTデータを用いた予測モデルの構築
分析モデルの選択理由
IoTデータの特性に合わせて、適切な分析モデルを選択することが重要です。時間の経過とともに収集される時系列データや、センサーからの多次元データなど、IoTデータは多様です。線形回帰、決定木、ランダムフォレスト、ニューラルネットワークなど、さまざまなモデルが考えられますが、以下の要因を考慮してモデルを選択します。
- データの量: 大量のデータが利用可能な場合、深層学習のような複雑なモデルが適しています。
- データの種類: 時系列データの場合、LSTMやGRUのようなリカレントニューラルネットワークが有効です。
- 解析の目的: 分類問題なのか、回帰問題なのか、クラスタリングが目的なのかによって選択するモデルも変わります。
モデルの訓練と評価
モデルの訓練には、データの前処理後、適切なライブラリと関数を使用します。以下は、ランダムフォレストを使用した例です。
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# モデルの訓練
model = RandomForestRegressor(n_estimators=100, random_state=0)
model.fit(X_train, y_train)
# モデルの評価
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")予測結果の解釈と活用
モデルの予測結果を解釈し、それを実際の農業活動にどのように活用できるかを考えることは、データ分析の最終目的です。ランダムフォレストの場合、特徴量の重要度を確認することで、どのセンサーデータが予測に影響を与えているかを把握できます。
importances = model.feature_importances_
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(10,6))
plt.title('Feature Importances')
plt.bar(range(X_train.shape[1]), importances[indices], align='center')
plt.xticks(range(X_train.shape[1]), X_train.columns[indices], rotation=90)
plt.tight_layout()
plt.show()結果として表示されるグラフを解釈することで、最も影響力のあるセンサーや環境変数を特定できます。これにより、特定のセンサーのデータ収集を強化したり、農業活動の最適化の方針を決定するための参考になります。
実際の農業への応用
IoT技術を活用した農業の事例
IoT技術は、農業分野で大きな変化をもたらしています。以下は、IoT技術が農業に実際に応用されている事例の一部です。
- 精密灌漑: 土壌の湿度センサーを使用して、作物の水分需要に応じて正確な量の水を供給するシステム。
- 病害虫監視: カメラやセンサーを使用して、病害虫の発生を検知し、早期に対策する。
- 自動収穫: ドローンやロボットを使用して、熟した作物を自動的に収穫する。
- 環境モニタリング: 天候や気温、湿度などの環境条件をリアルタイムで監視し、最適な栽培条件を維持する。
IoTデータによる作物生産量の向上効果
IoTデータの活用により、農業の生産性と効率性が大幅に向上しています。具体的な効果には以下のようなものがあります。
- 生産量の最適化: センサーからのデータを基に、水や肥料の供給を最適化することで、作物の生産量を増加させる。
- リソースの節約: 土壌の状態や作物の成長を監視することで、必要なリソースだけを供給し、無駄を削減する。
- 早期の問題検出: 病気や害虫の発生を早期に検出することで、被害を最小限に抑える。
- 品質の向上: 環境条件を最適に保つことで、作物の品質を一貫して高めることが可能になる。
以下は、IoTデータの活用による作物生産量の向上を示すシンプルなグラフです。
import matplotlib.pyplot as plt
years = ['2018', '2019', '2020', '2021', '2022']
production_without_iot = [100, 105, 110, 112, 115]
production_with_iot = [100, 110, 125, 135, 150]
plt.figure(figsize=(10,6))
plt.plot(years, production_without_iot, label='Without IoT', marker='o')
plt.plot(years, production_with_iot, label='With IoT', marker='o')
plt.title('Crop Production Over Years')
plt.xlabel('Year')
plt.ylabel('Production (in tons)')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()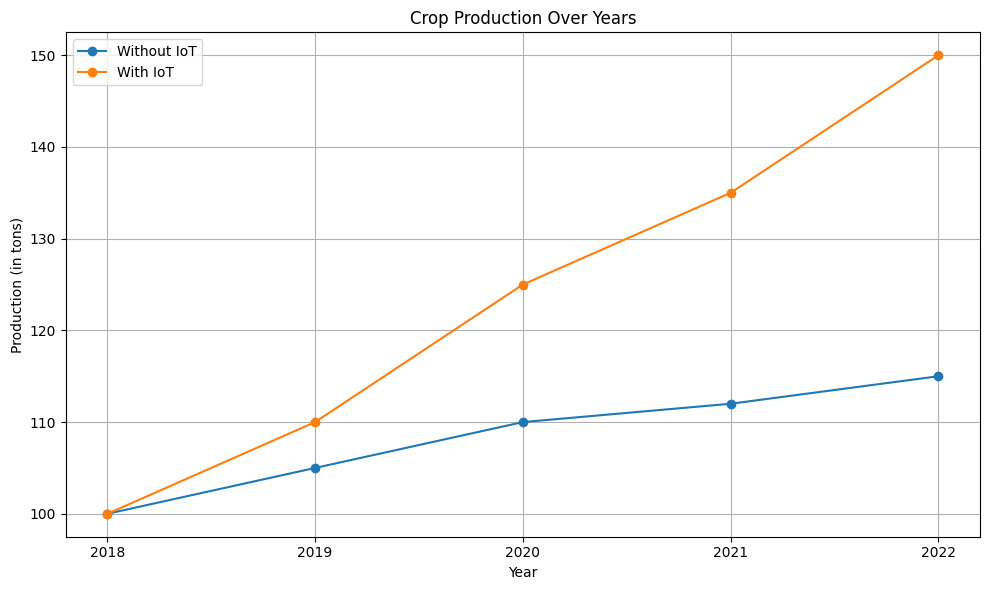
上記のグラフは、IoT技術の導入により、作物の生産量がどのように変化したかを示しています。IoT技術の導入により、生産量が大幅に向上していることが確認できます。
AIと農業IoTデータ分析のさらなる組み合わせ例
深層学習を用いた異常検知
深層学習は大量のデータから複雑なパターンを学習する能力を持っており、IoTデータの異常検知にも効果的に応用されています。異常検知は、センサーからのデータにおいて予期しない変動やパターンを検出する技術であり、病気や害虫の発生、機器の故障などの早期発見に役立ちます。
- Autoencoders: Autoencoderは、入力データを圧縮し、再度元の形に復元するニューラルネットワークです。正常なデータで訓練されたAutoencoderは、異常なデータを入力として受け取った際に再構築誤差が増大するため、この誤差を基に異常を検出します。
- LSTM: LSTM (Long Short-Term Memory) は、時系列データのパターンを学習するための再帰型ニューラルネットワークです。センサーデータの時間的な変動を学習し、異常なパターンを検出できます。
IoTセンサーデータとドローン画像データの統合分析
IoTセンサーデータとドローンからの画像データを統合することで、農地のより詳細な分析が可能になります。この組み合わせにより、以下のような応用が考えられます。
- 成長のモニタリング: センサーデータが示す土壌の状態や気象条件と、ドローン画像に映る作物の状態を組み合わせることで、作物の成長状態をより正確に把握できます。
- 収穫の最適化: ドローン画像を用いて作物の熟度を判断し、センサーデータと組み合わせて最適な収穫タイミングを予測します。
- 病害虫の検出: ドローン画像から病害の兆候を検出し、センサーデータとの組み合わせて病害の原因や拡大を予防するための対策を考えることができます。
以下は、IoTセンサーデータとドローン画像データの統合分析の一例です。土壌の湿度と作物の緑度(NDVI: Normalized Difference Vegetation Index)の関係を示すシンプルなグラフです。
import matplotlib.pyplot as plt
soil_moisture = [20, 25, 30, 35, 40, 45, 50]
ndvi_values = [0.2, 0.4, 0.6, 0.7, 0.6, 0.5, 0.3]
plt.figure(figsize=(10,6))
plt.scatter(soil_moisture, ndvi_values, color='green')
plt.title('Relationship between Soil Moisture and NDVI')
plt.xlabel('Soil Moisture (%)')
plt.ylabel('NDVI')
plt.grid(True)
plt.tight_layout()
plt.show()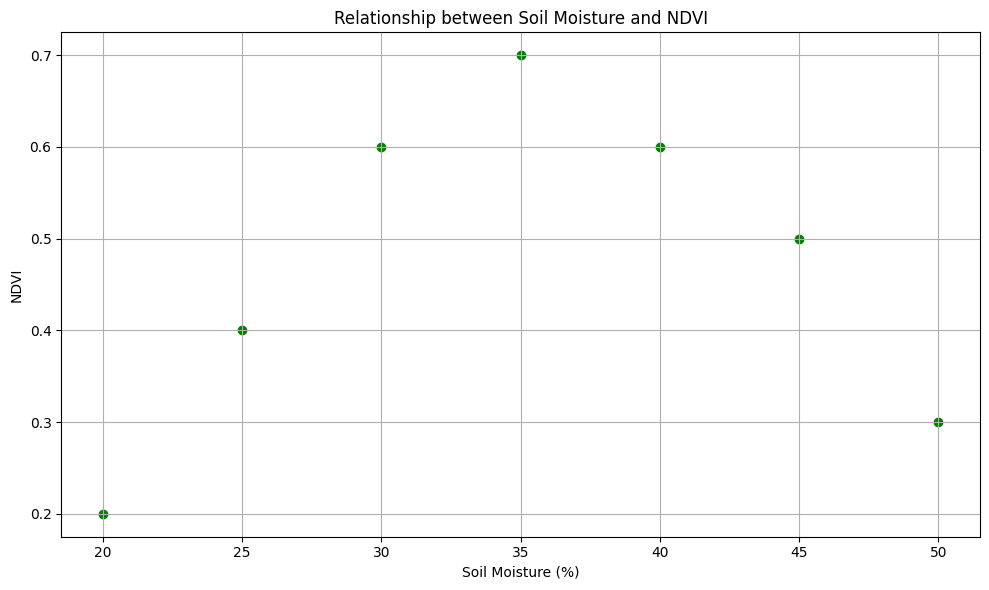
上記のグラフは、土壌の湿度が一定の範囲で最適なときに作物の緑度が最大になることを示しています。これにより、灌漑の最適化などの農業管理の参考になります。
ChatGPTとの連携
自動レポート生成の実現
ChatGPTのテキスト生成能力を活用することで、IoTデータの分析結果を元に自動的にレポートを生成できます。例えば、異常検知やデータの傾向、予測結果などを、わかりやすい文章として自動生成し、農家や関連ステークホルダーに報告できます。
具体的な手順は以下の通りです。
- IoTデータを分析し、必要な情報や統計を取得。
- ChatGPT APIを利用して、取得した結果を元にレポートの文章を生成。
- 生成されたレポートを保存または関連ステークホルダーに送信。
import openai
# OpenAIのAPIを使用して、IoTデータの分析結果を元にレポートを生成
def generate_report(summary):
openai.api_key = 'YOUR_OPENAI_API_KEY'
response = openai.Completion.create(
engine="davinci",
prompt=f"Generate a report based on the following analysis summary: {summary}",
max_tokens=150
)
return response.choices[0].text.strip()
# 例: 異常検知の結果を元にレポートを生成
summary = "Anomalies detected in soil moisture levels on June 5th, likely due to malfunctioning sensors."
report = generate_report(summary)
print(report)リアルタイムの質問応答システムの構築
ChatGPTを利用して、リアルタイムにIoTデータに関する質問を受け付け、即座に回答するシステムを構築できます。これにより、農家がIoTデータに関する疑問や懸念を持った際に、迅速に情報を提供できます。
具体的な手順は以下の通りです。
- Webインターフェースまたはモバイルアプリを作成。
- ユーザーからの質問を受け取り、ChatGPT APIを利用して回答を生成。
- 生成された回答をユーザーに表示。
import openai
# OpenAIのAPIを使用して、ユーザーからの質問に回答を生成
def get_answer(question):
openai.api_key = 'YOUR_OPENAI_API_KEY'
response = openai.Completion.create(
engine="davinci",
prompt=f"Answer the following question related to IoT data in agriculture: {question}",
max_tokens=150
)
return response.choices[0].text.strip()
# 例: ユーザーからの質問に回答を生成
question = "How can I improve crop yield using IoT data?"
answer = get_answer(question)
print(answer)ChatGPTの連携を通じて、農業IoTデータの分析と活用をより効果的に進めることができます。
まとめ
Pythonによる農業IoTデータ分析の振り返り
Pythonを用いて農業IoTデータの収集、前処理、可視化、そして予測モデルの構築までの一連の流れを紹介しました。具体的には、必要なライブラリのインポートからサンプルデータの作成、そして実際のデータ解析に至るまでの手順を解説しました。また、AI技術やChatGPTとの連携を通じて、データ分析のさらなる応用例も紹介しました。
今後の展望
IoT技術とデータ分析の組み合わせは、農業分野においても可能性があります。今後は、さらに高度な分析手法や新しい技術の導入により、より精度の高い予測や最適化が期待されます。特に、ドローンや衛星画像データとの統合分析による精密農業の実現や、深層学習を用いた異常検知の向上が注目されています。また、ChatGPTやその他のAI技術との連携を強化することで、リアルタイムの質問応答システムの構築や自動レポート生成など、農業分野における情報提供の質と速度の向上も期待されます。これらの技術の進化とともに、農業IoTデータ分析のフィールドはさらに広がりを見せるでしょう。

▼AIを使った副業・起業アイデアを紹介♪

