
Pythonで、阪神タイガースが再びリーグ優勝する日を予想しましょう。
(データ引用元:npb.jp https://npb.jp)
Pythonによるサンプルデータの生成と分析
Pythonを使用して、阪神タイガースが次にリーグ優勝する年を予測します。野球の試合結果を予測するには複雑な要因があるため、簡単なデータセットを用いたサンプルコードを紹介します。実際の予測にはより詳細なデータと高度なモデルが必要です。
まず、データは阪神タイガースの過去の優勝年度を基にします。その後でデータの可視化を行います。ここでは、簡単な確率とランダムサンプリングを使って未来の優勝年を予測しますが、実際の予測にはより複雑なアプローチが必要です。
基本的なPythonコード
基本的なPythonコードを紹介します。このコードは、阪神タイガースの過去の順位データを利用し、視覚化します。
コードの実行にはPython環境とMatplotlibライブラリが必要です。
import matplotlib.pyplot as plt
import pandas as pd
# Data provided
data = {
"Year": [1939, 1940, 1941, 1942, 1943, 1944, 1946, 1947, 1948, 1949, 1950, 1951, 1952, 1953, 1954, 1955, 1956,
1957, 1958, 1959, 1960, 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969, 1970, 1971, 1972, 1973,
1974, 1975, 1976, 1977, 1978, 1979, 1980, 1981, 1982, 1983, 1984, 1985, 1986, 1987, 1988, 1989, 1990,
1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007,
2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023],
"Rank": [2, 2, 5, 3, 3, 1, 3, 1, 3, 6, 4, 3, 2, 2, 3, 3, 2, 2, 2, 2, 3, 4, 1, 3, 1, 3, 3, 3, 2, 2, 2, 5, 2,
2, 4, 3, 2, 4, 6, 4, 5, 3, 3, 4, 4, 1, 3, 6, 6, 5, 6, 6, 2, 4, 4, 6, 6, 5, 6, 6, 6, 6, 4, 1, 4, 1, 2,
3, 2, 4, 2, 4, 5, 2, 2, 3, 4, 2, 6, 3, 2, 2, 3, 1]
}
df = pd.DataFrame(data)
# 移動平均の計算(ここでは5年間の移動平均を使用)
df['Moving Average'] = df['Rank'].rolling(window=5).mean()
# プロット
plt.figure(figsize=(12, 6))
plt.plot(df["Year"], df["Rank"], marker='o', linestyle='-', label="Actual Rank")
plt.plot(df["Year"], df['Moving Average'], marker='', linestyle='--', label="Moving Average")
plt.title("Ranking by Year with Moving Average")
plt.xlabel("Year")
plt.ylabel("Rank")
plt.gca().invert_yaxis()
plt.grid(True)
plt.legend()
plt.show()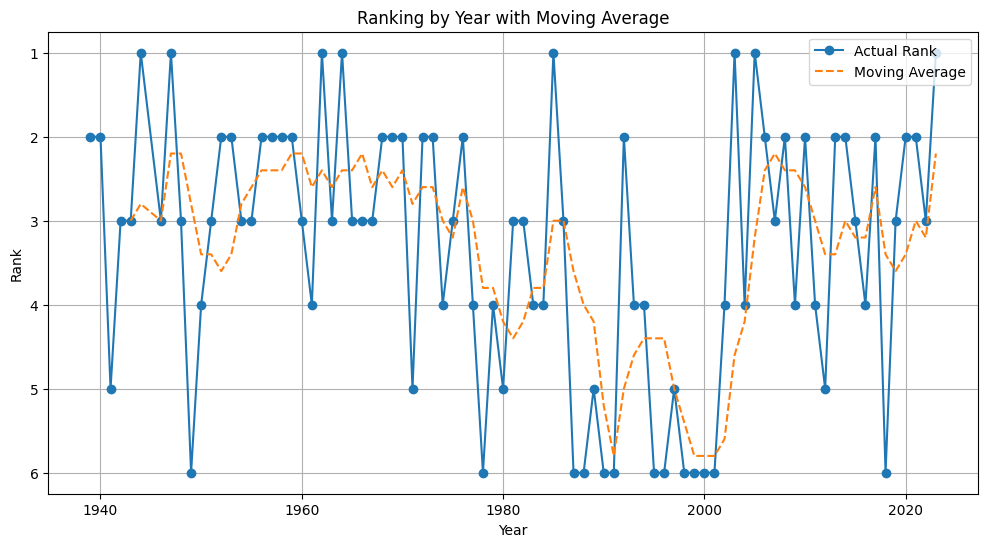
Pythonによる最適化コードとその解説
阪神タイガースの優勝年度のデータフレームを使用して1位になる確率を計算し、将来の年度で1位になる確率を予測するPythonコードを書きます。
Pythonコード
以下のPythonコードは、阪神タイガースの過去の優勝年度を基に、確率とランダムサンプリングを使用して、未来の優勝年度を予測します。
import pandas as pd
import numpy as np
df = pd.DataFrame(data)
# 1位になる確率の計算
probability_of_rank_1 = (df['Rank'] == 1).sum() / len(df)
# 未来の年度(2024年から2050年まで)に1位になる確率を計算
future_years = np.arange(2024, 2051)
probabilities = np.full(len(future_years), probability_of_rank_1)
# 確率の正規化
probabilities /= probabilities.sum()
# 未来の各年において1位になる年を予測
predicted_year = np.random.choice(future_years, p=probabilities)
# 結果の表示
print(f"Probability of being rank 1 in any given year: {probability_of_rank_1:.2f}")
print(f"Predicted year to be rank 1 based on probability: {predicted_year}")
Probability of being rank 1 in any given year: 0.10
Predicted year to be rank 1 based on probability: 2028阪神タイガースが次にリーグ優勝する年は、「2028年」と予測できました。
解説
上記のコードは、阪神タイガースの過去の順位をデータフレームとして使用して、将来的に1位になる確率を予測するPythonコードです。
- ライブラリのインポート:
pandasおよびnumpyライブラリをインポートしています。これらのライブラリはデータ操作と数学的計算のために使用されます。
- データフレームの作成:
pd.DataFrame(data)を使用して、dataというデータを含むPandasデータフレーム(df)を作成しています。データフレームには、阪神タイガースの過去の順位が記載されています。
- 1位になる確率の計算:
df['Rank'] == 1を使用して、データフレーム内で1位になるイベントの行を抽出し、.sum()を使用してその数をカウントします。これにより、1位になる確率が計算され、probability_of_rank_1という変数に格納されます。
- 未来の年度での確率の計算:
np.arange(2024, 2051)を使用して、2024年から2050年までの未来の年度を表す配列future_yearsを作成します。np.full(len(future_years), probability_of_rank_1)を使用して、すべての未来の年度における1位になる確率をprobabilitiesという配列に格納します。すべての年度で同じ確率を持つと仮定しています。
- 確率の正規化:
probabilitiesの合計を1に正規化するため、probabilitiesをprobabilities.sum()で割っています。
- 未来の各年での1位予測:
np.random.choice(future_years, p=probabilities)を使用して、future_yearsからランダムに1つの年を選択します。この選択は、各年度がprobabilitiesに基づいて確率的に行われ、1位になる予測の年がpredicted_yearに格納されます。
- 結果の表示:
- 最後に、計算された確率と予測された1位の年が表示されます。
阪神タイガースの過去のランキングデータから1位になる確率を計算し、将来の年度で1位になる確率を予測する簡単なシミュレーションです。データや確率の仮定によって、予測される結果が変化します。
ビジネス・アイデア
上記の確率モデルやアプローチ、分析、最適化の手法は、さまざまなビジネス領域に応用できます。ここでは、いくつかの例とアイデアを紹介します。
- マーケティング戦略の予測:
顧客の購買行動や市場シェアの変化など、さまざまな要因に基づいて将来の市場での成功確率を予測できます。新製品の導入戦略や販売プロモーションを計画できます。 - リスク管理:
金融機関や保険会社は、顧客の信用リスクや保険イベントの発生確率を予測きます。リスク予測は適切な価格設定やリソースの最適な割り当てに役立ちます。 - 在庫最適化:
供給チェーン管理では、需要の予測に基づいて在庫を最適化する必要があります。将来の需要を予測し、適切な在庫を確保できます。 - 医療分野:
患者の健康リスクや疾患の進行を予測するために使用できます。治療計画を最適化できます。 - 天候予測:
気象データを使用して将来の天候パターンを予測し、農業、エネルギー供給、災害管理などに活用できます。 - スポーツ分析:
スポーツの結果を予測するために、選手の成績データやチームの統計情報を使用できます。 - 人事予測:
人事部門は、将来の人事動向を予測するために使用できます。適切な採用計画やトレーニングプログラムの設計に役立ちます。
確率とランダムサンプリングを使用して将来の出来事を予測する方法は、さまざまな分野に応用できます。ただし、適切なデータとモデルの構築が必要です。

▼AIを使った副業・起業アイデアを紹介♪

