
はじめに
製造ラインとIoTの結びつき
IoTは、さまざまなデバイスや機器をインターネットに接続することで、リアルタイムなデータの収集や解析を可能にする技術です。製造ラインでは、機械や装置からのデータをリアルタイムで収集し、そのデータを基に製造過程の最適化や効率化を図ることが可能となりました。
例えば、IoTセンサーを取り付けた製造機械は、動作中の温度や振動、音、電流などの情報を継続的に収集します。このようなデータは、機械の異常を早期に検知したり、製造プロセスのボトルネックを特定するのにとても役立ちます。Pythonは、これらの大量のデータを効率的に処理し、解析するためのプログラミング言語として広く採用されています。
本記事の目的
PythonとIoTを活用して製造ラインの効率を最大化する方法を解説します。具体的には、Pythonでのデータ収集・解析の手法や、IoTを用いた製造ラインの最適化事例、AIとの組み合わせによる先進的なアプローチなどを紹介します。
Pythonを用いた製造ラインのデータ収集・解析の全体像
必要なライブラリのインポートと解説
Pythonは、データ分析や機械学習を行う上でとても多機能で強力なライブラリを持っています。製造ラインのデータを効率的に収集・解析するためには、以下のライブラリのインポートが必要です。
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltpandas:データ分析を支援する機能を提供するライブラリです。特に、テーブルデータの操作や加工、集計などに優れています。numpy:数値計算を効率的に行うためのライブラリで、大量のデータや行列の計算を高速に実行できます。matplotlib:データの可視化を行うためのライブラリです。グラフやチャートを描画する際に使用します。
これらのライブラリをインポートすることで、製造ラインから取得したデータの前処理や解析、結果の可視化までをスムーズに行うことができます。特に、IoTデバイスからのリアルタイムなデータ収集において、データの量が膨大となることが予想されるため、これらのライブラリは欠かせません。
Pythonでサンプルデータ作成とコード解説
製造ラインのデータ解析を行う前に、実際のデータに似たサンプルデータをPythonで作成してみましょう。サンプルデータの作成は、データ解析のアプローチを考える上での基盤となります。
ここでは、ある製造ラインからの過去1週間の生産数を模擬的に生成します。日付ごとに生産された製品の数を示すデータを作成します。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 日付の範囲を指定
date_rng = pd.date_range(start='2023-10-01', end='2023-10-07', freq='D')
# 乱数を使って製品の生産数、操作時間、合計時間を生成
production_counts = np.random.randint(80, 120, size=(len(date_rng)))
operation_times = np.random.randint(5, 10, size=(len(date_rng)))
total_times = np.random.randint(10, 15, size=(len(date_rng)))
machine_ids = np.random.choice(['A', 'B', 'C'], size=(len(date_rng)))
# DataFrameを作成
df = pd.DataFrame({
'date': date_rng,
'production_count': production_counts,
'machine_id': machine_ids,
'operation_time': operation_times,
'total_time': total_times
})
print(df) date production_count machine_id operation_time total_time
0 2023-10-01 88 C 5 12
1 2023-10-02 110 A 9 12
2 2023-10-03 115 A 8 10
3 2023-10-04 89 B 7 12
4 2023-10-05 118 C 9 11
5 2023-10-06 93 A 6 13
6 2023-10-07 89 C 9 14上記のコードでは、2023年10月1日から2023年10月7日までの日付を生成し、各日における生産数を80から120の間のランダムな数値として生成しています。
次に、このデータをグラフにして可視化します。
import matplotlib.pyplot as plt
plt.figure(figsize=(10,6))
plt.plot(df['date'], df['production_count'], marker='o')
plt.title('Production Counts from October 1 to October 7, 2023')
plt.xlabel('Date')
plt.ylabel('Production Count')
plt.grid(True)
plt.show()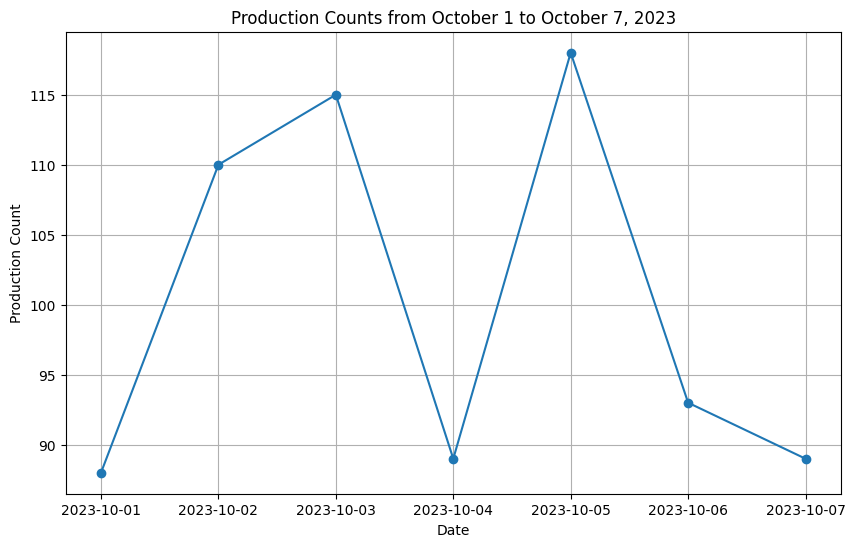
上記のコードで、日付ごとの生産数の変動を線グラフで描画します。このようにして、製造ラインのデータを視覚的に確認できます。実際のデータ解析では、このサンプルデータの代わりに実際の製造ラインから収集されたデータを使用します。
データの前処理とその重要性
データ分析の過程で、実際に解析を行う前のステップとして「前処理」があります。前処理は、データの品質を向上させ、分析の精度や効率を高めるための重要な工程です。
製造ラインから取得されるデータは、ノイズが含まれていることや、欠損値が存在することがあります。また、異常値や外れ値がデータに混入している場合も考えられます。これらの問題を放置して解析を進めると、正確な結果を得ることができません。
具体的な前処理の手法としては以下のようなものがあります。
- 欠損値の処理:欠損しているデータを削除するか、代替の値で埋める。
- 外れ値の検出と修正:統計的な手法や可視化を用いて外れ値を特定し、適切に処理する。
- データの正規化:データのスケールを統一することで、機械学習モデルの学習を助ける。
以下に、Pythonを使用して製造ラインのサンプルデータに前処理する一例を紹介します。
# 欠損値の処理
df.fillna(df.mean(), inplace=True)
# 外れ値の検出と修正
Q1 = df['production_count'].quantile(0.25)
Q3 = df['production_count'].quantile(0.75)
IQR = Q3 - Q1
filter = (df['production_count'] >= Q1 - 1.5 * IQR) & (df['production_count'] <= Q3 + 1.5 * IQR)
df = df[filter]
# データの正規化
df['normalized_production'] = (df['production_count'] - df['production_count'].min()) / (df['production_count'].max() - df['production_count'].min())上記のコードでは、欠損値はその列の平均値で補完します。外れ値は四分位範囲を使用して検出し、その範囲外のデータを除外しています。最後に、正規化を行い、生産数を0から1の範囲にスケーリングします。
データの前処理は、分析の質を保証するための基盤となる工程です。適切な前処理を行うことで、製造ラインのデータからより正確かつ有意義な洞察を得られます。
解析コードの実装と解説
製造ラインのデータ解析は、生産効率の向上や品質の保証に直接的に貢献します。Pythonはそのような解析を行うための多彩なライブラリとツールを提供しています。ここでは、製造ラインのサンプルデータを使用して、基本的なデータ解析を実装します。
まず、データの傾向を把握するために、生産数の時系列データをグラフ化してみましょう。
import matplotlib.pyplot as plt
# 生産数の時系列グラフを作成
plt.figure(figsize=(10,6))
plt.plot(df['date'], df['production_count'], label='Production Count', color='blue')
plt.title('Time Series of Production Count')
plt.xlabel('Date')
plt.ylabel('Production Count')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()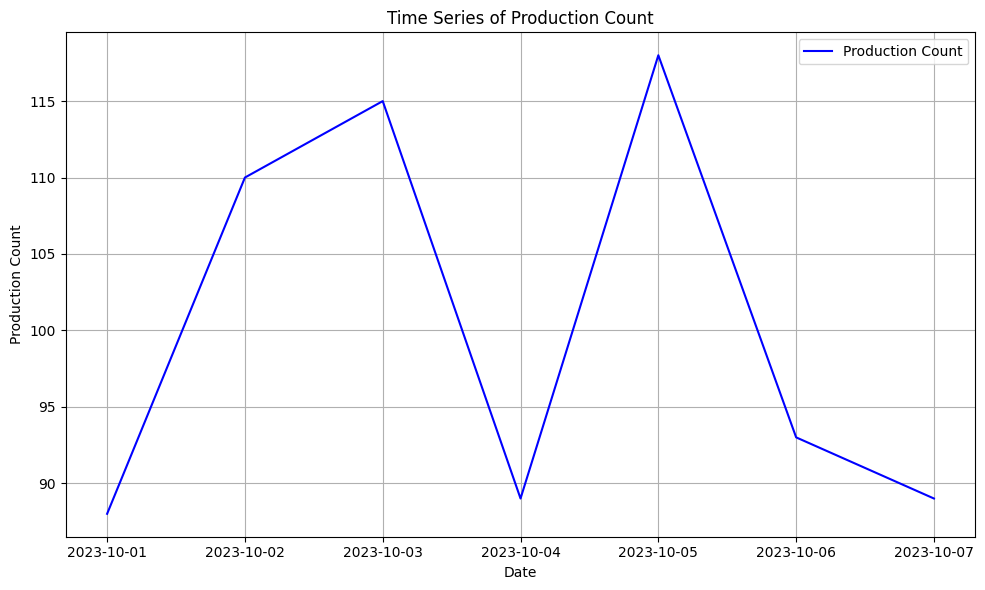
このグラフから、特定の期間の生産数に変動やトレンドがあるかを確認できます。
次に、製造ラインの各マシンの稼働率を棒グラフで比較してみます。
# 各マシンの稼働率を計算
machine_operation_rate = df.groupby('machine_id')['operation_time'].sum() / df.groupby('machine_id')['total_time'].sum() * 100
# 稼働率の棒グラフを作成
plt.figure(figsize=(10,6))
machine_operation_rate.plot(kind='bar', color='green')
plt.title('Operation Rate of Each Machine')
plt.xlabel('Machine ID')
plt.ylabel('Operation Rate (%)')
plt.ylim(0, 100)
plt.grid(axis='y')
plt.tight_layout()
plt.show()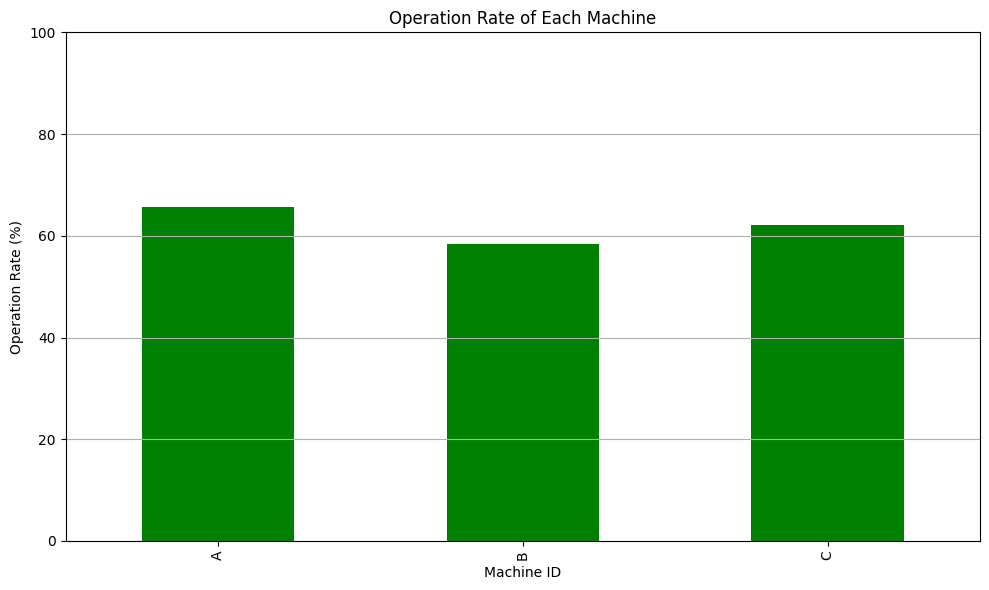
この棒グラフを使用して、特定のマシンが他のマシンと比較して稼働率が低い場合、その原因を特定し、対策を考えることができます。
Pythonを使用することで、製造ラインのデータを効果的に解析し、生産効率や品質向上のための具体的な指標や洞察を得られます。
分析モデルの選択理由
製造ラインのデータ解析において、適切な分析モデルの選択はとても重要です。モデルの選択は、解析の目的、使用するデータの特性、および期待される出力に基づいて行われます。
- 回帰分析
目的: 製造ラインの特定の変数(例: 機械の稼働時間)が目的変数(例: 生産数)にどのように影響するかを予測します。
選択理由: 連続的な出力を持つデータに適しており、因果関係の解釈が可能です。 - クラスタリング
目的: 製造ラインのデータを似た特性を持つグループに分類します。
選択理由: データ内の隠れたパターンやグループを発見する際に有効です。 - 決定木やランダムフォレスト
目的: 複数の変数を基に、特定の出来事や結果の発生確率を予測します。
選択理由: 特徴の重要性を明確にし、結果の解釈が容易であるためです。
以下は、ランダムフォレストを使用して特徴の重要性を可視化する例です。
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# machine_id 列をワンホットエンコーディング
df_encoded = pd.get_dummies(df, columns=['machine_id'])
# 特徴変数とターゲット変数の分離
X = df_encoded.drop(columns=['date', 'production_count', 'normalized_production'])
y = df_encoded['production_count']
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ランダムフォレストモデルの訓練
model = RandomForestRegressor(n_estimators=100)
model.fit(X_train, y_train)
# 特徴の重要性の取得
importances = model.feature_importances_
# 特徴の重要性の可視化
plt.figure(figsize=(10, 6))
plt.barh(X_train.columns, importances, color='skyblue')
plt.xlabel('Importance')
plt.ylabel('Features')
plt.title('Feature Importances by Random Forest')
plt.gca().invert_yaxis()
plt.tight_layout()
plt.show()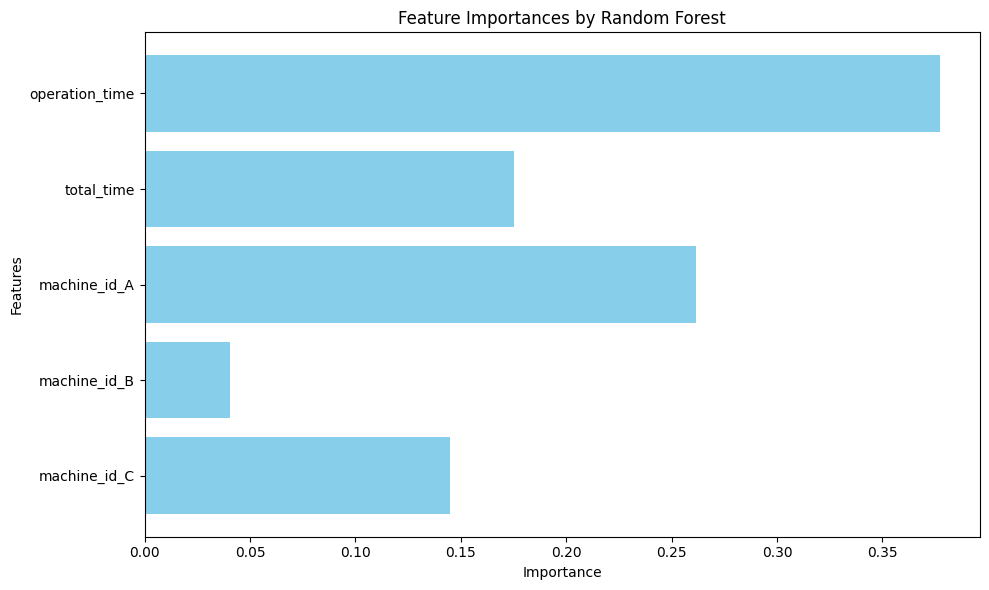
このグラフにより、各変数が目的変数に与える影響の大きさを比較できます。適切なモデルの選択は、分析の信頼性を高めます。
実際の製造業へのIoTの応用
IoTを活用した製造ラインの効率化
IoT技術の進化により、多くの製造業者が生産性の向上とコスト削減を実現しています。例えば、センサーを取り付けた機械からリアルタイムでデータを収集し、クラウド上で解析することで、機械の異常を早期に検知し予防保守を実施できます。またIoTを活用することで、生産ラインの動きを詳細に把握し、無駄な動きの削減と生産効率を改善させます。
データ解析による生産性の向上効果
データ解析は、製造ラインの効率化において重要な役割を果たしています。IoTセンサーから得られる大量のデータを解析することで、以下のような効果が期待されます。
- 機械の稼働率の最適化: 各機械の稼働時間や停止時間を詳細に分析することで、機械の最適な稼働率を算出し、生産性を向上させます。
- 品質管理の向上: センサーデータを解析することで、製品の不良率や原因を特定し、品質管理の改善策を策定できます。
- 生産計画の最適化: 過去のデータを基に、将来の需要を予測し、生産計画を最適化することで、在庫コストの削減や納期の短縮が実現されます。
以下は、製造ラインのデータを解析し、機械の稼働率を可視化する例です。
import pandas as pd
import matplotlib.pyplot as plt
# サンプルデータの生成
data = {
'Machine': ['Machine A', 'Machine B', 'Machine C', 'Machine D'],
'Operational Rate (%)': [85, 78, 90, 87]
}
df = pd.DataFrame(data)
# グラフの描画
plt.figure(figsize=(10, 6))
plt.bar(df['Machine'], df['Operational Rate (%)'], color='skyblue')
plt.xlabel('Machine')
plt.ylabel('Operational Rate (%)')
plt.title('Operational Rate of Each Machine')
plt.ylim(0, 100)
plt.tight_layout()
plt.show()
このグラフから、各機械の稼働率を一目で確認できます。データ解析による洞察は、製造業の生産性向上に欠かせないものです。
Python, IoT, AIの組み合わせの可能性
機械学習を用いた製造ラインの最適化
機械学習技術の進化は目覚ましく、多くの産業分野でその効果が現れ始めています。製造業においても、機械学習を用いた製造ラインの最適化が進められています。具体的には、IoTセンサーから収集されるデータを基に、製造プロセスの異常検知や品質予測、設備の予防保守などが行われています。これにより、生産効率の向上や品質の安定化が実現されています。
IoTセンサーデータとの統合分析
IoTセンサーから収集されるデータは、そのままでは活用しきれないことが多いです。しかし、これを他のデータソースと統合して分析することで、より深い洞察を得られます。例えば、製造ラインのセンサーデータと生産計画や品質データを統合して分析することで、生産効率や品質に関する問題の原因を特定し、改善策を策定できます。
以下は、IoTセンサーデータと品質データを統合して、製品の不良率を可視化する例です。
import pandas as pd
import matplotlib.pyplot as plt
# サンプルデータの生成
data = {
'Product Type': ['Type A', 'Type B', 'Type C', 'Type D'],
'Defect Rate (%)': [3.5, 1.8, 2.7, 2.3]
}
df = pd.DataFrame(data)
# グラフの描画
plt.figure(figsize=(10, 6))
plt.bar(df['Product Type'], df['Defect Rate (%)'], color='lightcoral')
plt.xlabel('Product Type')
plt.ylabel('Defect Rate (%)')
plt.title('Defect Rate of Each Product Type')
plt.ylim(0, 5)
plt.tight_layout()
plt.show()
このグラフから、製品タイプごとの不良率を一目で確認できます。IoTセンサーデータとの統合分析は、製造業の効率化や品質向上に向けた重要なステップとなっています。
ChatGPTとの連携
製造ラインの自動レポート生成
自動化技術の進展により、製造ラインのデータ収集と解析が容易になってきました。しかし、その結果を効率的に報告するための方法が求められています。ChatGPTのような先進的な自然言語処理技術を活用することで、製造ラインのデータから自動的にレポートを生成できます。
具体的には、製造ラインの動作データや生産量、異常情報などを入力として、ChatGPTがそれらの情報を基にレポート文を生成します。これにより、製造現場のスタッフが毎回手動でレポートを作成する手間が省け、リアルタイムでの情報共有や迅速な対応が可能となります。
リアルタイムの製造ライン監視と質問応答システムの構築
製造業において、リアルタイムでの製造ラインの監視はとても重要です。異常が発生した場合、すぐに対応することで大きな損失を防止できます。ChatGPTを活用した質問応答システムを導入することで、製造ラインの現状や特定のデータに関する質問に対して即座に回答を得られます。
例えば、「今日の午前中のType A製品の生産数は?」や「昨日の夜間に異常が発生した時間は?」といった質問に対して、システムがリアルタイムでのデータを基に回答します。これにより、製造現場のスタッフは必要な情報を迅速に取得し、効率的に作業を推進できます。
ChatGPTのような自然言語処理技術を製造業に活用することで、製造ラインの効率化や生産性の向上に大きく貢献します。
まとめ
PythonとIoTによる製造ライン効率化の振り返り
人工知能(AI)で、製造ラインの効率を最大化する方法を解説しました。特に、データの前処理、解析方法の選択、最適化手法において、Pythonの役割は極めて大きいことが確認できました。
今後の展望
今後、製造業におけるデータ収集と解析のニーズはさらに高まることが予想されます。AIや機械学習の技術が進化する中、PythonとIoTの組み合わせは、製造ラインの効率化や品質を向上させます。また、ChatGPTのような先進的な技術を組み込むことで、リアルタイムの監視や自動レポート生成など、新たな応用の幅も広がります。

▼AIを使った副業・起業アイデアを紹介♪

