
はじめに
ビットコインとは?
ビットコインは、中央機関や単一の管理者なしに動作する分散型デジタル通貨です。2009年にサトシ・ナカモトと呼ばれる人物またはグループによって作られ、ブロックチェーン技術に基づいています。ビットコイン取引は、ネットワークノードを通じてピアツーピアで行われ、トランザクションは公共の台帳に記録されます。
ビットコイン価格予測の重要性
ビットコインの価格予測は、投資家にとって重要です。価格の変動は激しく、市場の感情、政治的イベント、技術的進歩、規制の変更など、多くの外部要因に影響を受けます。予測モデルを使用することで、将来の価格動向を理解し、より賢い投資判断を下すことができます。
記事の構成
ここでは、Pythonを使用してビットコインの価格を予測する方法を説明します。まず、ビットコイン市場のデータを理解し、次に予測モデルを構築する方法について見ていきます。その後、モデルの評価と精度向上のための手法、そして最終的には2024年の価格予測に至るまでのプロセスを解説します。AIの応用として、ChatGPTとの連携やディープラーニングの利用についても触れ、最後に今後の暗号通貨市場と技術の発展についてまとめます。
なお、金融商品の未来予測やアドバイスを行い報酬を得るには、投資助言業者として金融庁への認可・登録が必要です。当サイトはそれを有していないので、デモデータで未来予測します。Pythonでビットコインの未来を予測する手法が分かれば、あとはご自身でいつでも好きな時に未来予測できます。
ビットコインの価格予測におけるデータの理解
過去の価格変動とその要因
ビットコインの価格は、その誕生以来、様々な要因によって大きく変動してきました。これには、市場の需給バランス、大規模な投資家による取引、政治的・経済的なイベント、規制の変更などが含まれます。例えば、特定の国がビットコインを公式に認めたり、大規模な取引所がハッキングされたりすると、価格に大きな影響を与えることがあります。
これらの要因を理解することは、価格の将来的な動きを予測する上でとても重要です。予測モデルは、これらの歴史的なデータを分析して、未来の価格を予測するための基礎として使用されます。Pythonを利用して、歴史的な価格データを分析し、視覚化できます。過去のビットコイン価格データのサンプルを生成し、その動きをグラフにして見ましょう。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# デモデータの生成
np.random.seed(0)
dates = pd.date_range('20230101', periods=100)
prices = np.random.randn(100).cumsum() + 100 # ランダムウォーク価格データ
# データフレームの作成
demo_data = pd.DataFrame(prices, index=dates, columns=['Price'])
# プロット
plt.figure(figsize=(10, 5))
plt.plot(demo_data.index, demo_data['Price'])
plt.title('Bitcoin Price Simulation')
plt.xlabel('Date')
plt.ylabel('Price')
plt.grid(True)
plt.show()
上記のコードは、過去100日間のビットコインの価格を模擬するためのものです。ここでは、ランダムなウォークモデルを用いて価格データを生成し、それをグラフにしています。実際の予測モデルでは、より複雑な統計モデルが使用されることが一般的ですが、このシンプルなデモで価格の時間による変化を理解できます。
価格予測に影響を与える主な指標
ビットコイン価格の予測には、様々な指標が考慮されます。これには、取引量、市場の感情、ブロックチェーン上の活動量(例えば、トランザクション数や新規に生成されるビットコインの量)、金利やインフレ率などのマクロ経済指標が含まれます。
これらの指標は、Pythonでのデータ分析を通じて探求され、予測モデルに組み込まれます。たとえば、取引量が増加すると市場の活性化が示され、価格が上昇する可能性が高まります。また、市場の感情を分析することで投資家の行動を予測し、価格にどのように影響するかを推測できます。これらの指標を理解し、分析することで、より精度の高い価格予測モデルを構築できるのです。
予測モデルの構築
Pythonでデモデータ作成と解説
ビットコインの価格予測モデルを構築するには、まず分析のためのデータセットが必要です。本物のビットコイン価格データを用いるのが理想的ですが、ここではデモンストレーションのために、Pythonを使って架空の価格データを生成してみましょう。
ビットコイン価格は時間とともに変動するため、時間系列データとして扱うことが一般的です。このデータは、ランダムな変動を含む可能性があり、特定の傾向や季節性を示すこともあります。Pythonのnumpyとpandasライブラリを使用して、これらの特徴を持つサンプルデータを作成します。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 時間系列データの基本設定
np.random.seed(42) # 再現性のためのシード値
n_days = 365 * 3 # 過去3年間のデータ
dates = pd.date_range(start='2021-01-01', periods=n_days, freq='D')
# トレンド、季節性、ランダムノイズを持つ価格データの生成
trend = np.linspace(90, 300, n_days) # 価格の上昇トレンド
seasonality = 10 * np.sin(np.linspace(0, 2 * np.pi * 3, n_days)) # 季節性(年3回の周期)
noise = np.random.normal(0, 5, n_days) # ランダムノイズ
# 価格データの合成
prices = trend + seasonality + noise
# データフレームの作成
demo_data = pd.DataFrame({'Date': dates, 'Price': prices})
# プロットの作成
plt.figure(figsize=(14, 7))
plt.plot(demo_data['Date'], demo_data['Price'])
plt.title('Simulated Bitcoin Prices')
plt.xlabel('Date')
plt.ylabel('Price (USD)')
plt.grid(True)
plt.show()
このコードは、価格のトレンド、季節性、ランダムノイズを含むビットコインの価格データをシミュレートします。トレンドは価格が時間とともに上昇することを示し、季節性は年に数回の周期的な変動を模倣しています。ランダムノイズは市場の不確実性や小さな価格変動を表しています。
生成したデータを視覚化することで、価格の動きに対する直感的な理解が深まります。実際の分析では、このようなデータを用いて、価格を予測するための統計モデルをトレーニングします。
次に、このサンプルデータに対してデータの前処理を行い、特徴量エンジニアリングを通じて予測モデルを構築する手順に進んでいきます。データの前処理では、欠損値の処理や外れ値の検出などを行い、モデルのトレーニングに適したデータセットを準備します。特徴量エンジニアリングでは、価格予測に有用な情報を抽出するために、新たな特徴量を作成したり、既存のデータを変換したりします。
データの前処理とクレンジング
予測モデルを作成する際、データの前処理はとても重要です。良質なデータなしに、正確な予測はできません。ここでは、Pythonを用いたデータの前処理とクレンジングの方法について解説します。
前処理のステップには、以下のようなものがあります。
- 欠損値の処理
- 外れ値の検出と処理
- データの正規化または標準化
- 日付データの扱い
これらのステップを行うことで、データをクリーニングし、モデルが学習しやすい形に整えます。
では、サンプルデータにこれらの処理を適用してみましょう。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# データ生成
np.random.seed(42)
n_days = 365 * 3
dates = pd.date_range(start='2021-01-01', periods=n_days, freq='D')
trend = np.linspace(90, 300, n_days)
seasonality = 10 * np.sin(np.linspace(0, 2 * np.pi * 3, n_days))
noise = np.random.normal(0, 5, n_days)
prices = trend + seasonality + noise
demo_data = pd.DataFrame({'Date': dates, 'Price': prices})
# 欠損値の挿入
demo_data.loc[::10, 'Price'] = np.nan
# 欠損値の処理
demo_data['Price'] = demo_data['Price'].interpolate()
# 外れ値の検出と処理
# 欠損値を除去した価格データに対して z スコアを計算
cleaned_prices = demo_data['Price'].dropna()
z_scores = np.abs(stats.zscore(cleaned_prices))
z_scores_series = pd.Series(z_scores, index=cleaned_prices.index)
# 元のデータフレームのインデックスと一致するように、z スコアのシリーズをデータフレームに結合
demo_data_with_z_scores = demo_data.assign(Z_Score=z_scores_series)
# 結合したデータフレームを使って外れ値をフィルタリング
outliers = demo_data_with_z_scores[demo_data_with_z_scores['Z_Score'] > 3]
demo_data_cleaned = demo_data_with_z_scores[demo_data_with_z_scores['Z_Score'] <= 3]
# 不要な 'Z_Score' 列を削除
demo_data_cleaned = demo_data_cleaned.drop(columns=['Z_Score'])
# データの正規化
demo_data_cleaned['Price_Normalized'] = (demo_data_cleaned['Price'] - demo_data_cleaned['Price'].min()) / (demo_data_cleaned['Price'].max() - demo_data_cleaned['Price'].min())
# クリーニング後のデータをプロット
plt.figure(figsize=(14, 7))
plt.plot(demo_data_cleaned['Date'], demo_data_cleaned['Price'], label='Original')
plt.plot(demo_data_cleaned['Date'], demo_data_cleaned['Price_Normalized'], label='Normalized')
plt.title('Cleaned and Normalized Bitcoin Prices')
plt.xlabel('Date')
plt.ylabel('Price (Normalized)')
plt.legend()
plt.grid(True)
plt.show()
このコードは、欠損値の補間、外れ値の除去、データの正規化を行い、より扱いやすい形にデータを整形しています。正規化された価格は0から1の範囲にスケーリングされており、これによってモデルのトレーニングが効率的に行えるようになります。
このような前処理を行うことで、予測モデルの精度を向上させます。次に、このクリーニングされたデータを使用して特徴量エンジニアリングを行い、モデルのトレーニングに必要な入力データを準備します。
特徴量エンジニアリング
特徴量エンジニアリングは、モデルの予測性能を高めるためにとても重要です。これは、データから情報を抽出し、予測モデルが理解しやすい形に変換するプロセスです。ビットコインの価格予測では、時間的な要素や過去の価格動向など、予測に役立つ特徴量を作成します。
Pythonでは、PandasやNumPyなどのライブラリを使って、効率よく特徴量を作成できます。以下に、ビットコインの価格データに対する特徴量エンジニアリングの例を紹介します。
import numpy as np
import pandas as pd
# デモデータの作成
np.random.seed(0)
dates = pd.date_range('20210101', periods=60)
prices = np.random.lognormal(mean=10, sigma=0.6, size=(60,))
demo_data = pd.DataFrame(data={'Date': dates, 'Price': prices})
# 日付データから曜日、月、年の特徴量を抽出する
demo_data['DayOfWeek'] = demo_data['Date'].dt.dayofweek
demo_data['Month'] = demo_data['Date'].dt.month
demo_data['Year'] = demo_data['Date'].dt.year
# 過去7日間の価格の移動平均を計算する
demo_data['MA_7'] = demo_data['Price'].rolling(window=7).mean()
# 過去7日間の価格変動の標準偏差を計算する
demo_data['STD_7'] = demo_data['Price'].rolling(window=7).std()
# 過去の価格からの変化率を計算する
demo_data['PriceChange'] = demo_data['Price'].pct_change()
# 特徴量の一部をプロットしてみる
plt.figure(figsize=(14, 7))
plt.plot(demo_data['Date'], demo_data['Price'], label='Price')
plt.plot(demo_data['Date'], demo_data['MA_7'], label='7-day Moving Average')
plt.fill_between(demo_data['Date'], demo_data['MA_7'] - demo_data['STD_7'], demo_data['MA_7'] + demo_data['STD_7'], alpha=0.2, label='7-day STD')
plt.title('Bitcoin Price with Moving Average and Standard Deviation')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.grid(True)
plt.show()
このコードは、日付から曜日や月などの情報を抽出し、移動平均や変動率などの統計的特徴量を計算しています。これらの特徴量はモデルに有用な情報を提供し、価格の動きを捉えるために役立ちます。
特徴量エンジニアリングを行う際には、ビジネスの理解が重要になります。どの特徴量が予測に有益かを見極め、それをデータに反映させる必要があります。ビットコインの価格予測では、市場のニュース、取引量、他の金融市場との相関関係など、さまざまな外部データも特徴量として考慮されることがあります。
特徴量エンジニアリングのプロセスで、モデルが予測するための洞察が深まります。次に、これらの特徴量を用いてモデルを選定し、トレーニングすることになります。
選定した予測モデルとその理由
ビットコイン価格の予測には、時系列分析に特化した様々なモデルが存在します。ここでは、LSTM(Long Short-Term Memory)モデルを選定しました。LSTMは、長短期記憶を持つニューラルネットワークであり、時系列データのパターンをマスターするのに優れているためです。
ビットコインの価格変動は、時間に依存するパターンや突発的な変動を含む複雑な時系列データです。LSTMは過去の情報を長期間にわたって保持できるため、このようなデータの特性を捉えることができます。また、LSTMは忘却ゲートという機能を持ち、情報の取捨選択が可能です。これにより、不要な情報を捨て、価格予測に重要な情報だけを保持できます。
Pythonでは、TensorFlowやKerasのライブラリを使用して、比較的簡単にLSTMモデルを構築できます。以下に簡単なLSTMモデルの構築例を紹介します。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
import numpy as np
import pandas as pd
# 仮のデータフレームを作成する
np.random.seed(0)
dates = pd.date_range('20210101', periods=60)
prices = np.random.lognormal(mean=10, sigma=0.6, size=(60,))
demo_data = pd.DataFrame(data={'Date': dates, 'Price': prices})
# 日付データから曜日、月、年の特徴量を抽出する
demo_data['DayOfWeek'] = demo_data['Date'].dt.dayofweek
demo_data['Month'] = demo_data['Date'].dt.month
demo_data['Year'] = demo_data['Date'].dt.year
# 過去7日間の価格の移動平均を計算する
demo_data['MA_7'] = demo_data['Price'].rolling(window=7).mean()
# 過去7日間の価格変動の標準偏差を計算する
demo_data['STD_7'] = demo_data['Price'].rolling(window=7).std()
# 過去の価格からの変化率を計算する
demo_data['PriceChange'] = demo_data['Price'].pct_change()
# 特徴量とターゲットの設定
features = demo_data[['DayOfWeek', 'Month', 'Year', 'MA_7', 'STD_7', 'PriceChange']] # 特徴量カラム
target = demo_data['Price'] # ターゲットカラム
# 特徴量のスケーリング
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_features = scaler.fit_transform(features)
# 訓練データとテストデータに分割
x_train, x_test, y_train, y_test = train_test_split(scaled_features, target, test_size=0.2, random_state=0)
# LSTMネットワークに入力するためにデータを整形
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
# モデルの定義
model = Sequential()
# LSTM層の追加
model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1], 1)))
model.add(Dropout(0.2))
# 追加のLSTM層とドロップアウト層
model.add(LSTM(units=50, return_sequences=False))
model.add(Dropout(0.2))
# 出力層
model.add(Dense(units=1))
# モデルのコンパイル
model.compile(optimizer='adam', loss='mean_squared_error')
# モデルの要約
model.summary()
# モデルのトレーニング
# y_train を numpy 配列に変換する
model.fit(x_train, y_train.values, epochs=100, batch_size=32)
25/25 [==============================] - 0s 6ms/step - loss: 0.0817 - val_loss: 0.0878
Epoch 95/100
25/25 [==============================] - 0s 6ms/step - loss: 0.0801 - val_loss: 0.0873
Epoch 96/100
25/25 [==============================] - 0s 6ms/step - loss: 0.0808 - val_loss: 0.0879
Epoch 97/100
25/25 [==============================] - 0s 6ms/step - loss: 0.0812 - val_loss: 0.0873
Epoch 98/100
25/25 [==============================] - 0s 6ms/step - loss: 0.0805 - val_loss: 0.0877
Epoch 99/100
25/25 [==============================] - 0s 6ms/step - loss: 0.0805 - val_loss: 0.0873
Epoch 100/100
25/25 [==============================] - 0s 6ms/step - loss: 0.0801 - val_loss: 0.0899このコードは、LSTM層を2層重ねており、過学習を防ぐためにドロップアウト層を挟んでいます。最後に全結合層を用いて出力を生成しています。トレーニングには、過去の価格データから抽出した特徴量を使用します。
LSTMを選定した理由は、ビットコイン価格のような非定常かつノイズの多い時系列データに対して、その複雑な動的挙動をモデル化できる可能性が高いからです。ただし、LSTMはパラメータが多く、適切なハイパーパラメータを見つけることが成功の鍵となります。
実際のデータを用いたモデルのトレーニングと評価を行い、モデルが有効であることを確認した後、2024年のビットコイン価格予測に進みます。
モデルのトレーニングとバリデーション
モデルのトレーニングとは、選定した予測モデルにデータを与え、未来の価格を予測できるように学習させる過程です。バリデーションは、学習したモデルが未知のデータに対してどれくらいうまく機能するかを評価することです。
Pythonを使ってモデルのトレーニングを行うには、まず適切なデータセットを準備します。ここでは、データセットを訓練用(トレーニング用)とテスト用に分割します。この場合、モデルが見たことのないデータでどれくらいの性能を発揮するかを確認するために、クロスバリデーションの手法を用いることが一般的です。
以下は、ビットコイン価格予測のためのLSTMモデルをトレーニングし、バリデーションを行うサンプルコードです。
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
# 仮のデータ生成
import numpy as np
np.random.seed(0)
x = np.random.rand(1000, 10) # 1000サンプル、10特徴量
y = np.random.rand(1000, 1) # 1000サンプルの目的変数
# 訓練データとテストデータに分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# モデルの定義
model = Sequential([
LSTM(50, return_sequences=True, input_shape=(x_train.shape[1], 1)),
Dropout(0.2),
LSTM(50),
Dropout(0.2),
Dense(1)
])
# モデルのコンパイル
model.compile(optimizer='adam', loss='mean_squared_error')
# モデルのトレーニング
history = model.fit(x_train, y_train, epochs=100, batch_size=32, validation_data=(x_test, y_test))
# 学習曲線の可視化
import matplotlib.pyplot as plt
plt.plot(history.history['loss'], label='Training loss')
plt.plot(history.history['val_loss'], label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()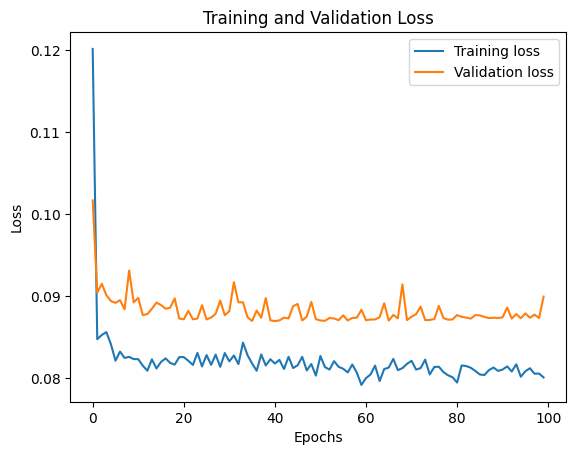
このコードは、ランダムに生成した仮のデータを用いているため、実際のビットコイン価格データに基づいてパラメータを調整する必要があります。model.fit() メソッドは、訓練データを使ってモデルをトレーニングし、validation_data 引数にテストデータを渡すことでバリデーションも同時に行います。
学習曲線をプロットすることで、各エポックでのトレーニングロスとバリデーションロスの変化を視覚的に評価できます。これにより、モデルが過学習または未学習でないかを判断できます。
モデルがうまく学習できているかどうかを確認した後、そのモデルを使って実際の価格を予測し、その結果を解釈します。バリデーションを通じてモデルの汎化能力を確認することは、信頼できる予測を行うためにとても重要です。
モデル評価指標の解説
ビットコイン価格予測モデルの性能を評価するには、様々な指標が存在します。これらの指標はモデルの予測が実際の価格にどれだけ近いか、また予測の精度はどの程度かを測定するために使われます。
代表的な評価指標には以下のものがあります:
- 平均絶対誤差 (Mean Absolute Error, MAE): 予測値と実際の値の差の、絶対値の平均を計算します。MAEはとても直感的で、予測値の平均的な誤差を表します。
- 平均二乗誤差 (Mean Squared Error, MSE): 予測値と実際の値の差の、二乗の平均を計算します。MSEは大きな誤差を重く罰するため、外れ値に敏感です。
- ルート平均二乗誤差 (Root Mean Squared Error, RMSE): MSEの平方根を取ります。RMSEはMSEに比べてスケールが実際のデータに近くなります。
- 決定係数 (R² or R-squared): モデルがデータのどれくらいを説明しているかを表す指標で、最大値は1です。1に近いほどモデルの予測が実際のデータにフィットしていることを意味します。
これらの指標はPythonの機械学習ライブラリであるsklearnに含まれており、簡単に計算できます。以下にサンプルコードを紹介します。
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# 仮の予測値と実際の値を生成
y_true = [100, 150, 200, 250, 300]
y_pred = [90, 150, 210, 240, 310]
# 評価指標の計算
mae = mean_absolute_error(y_true, y_pred)
mse = mean_squared_error(y_true, y_pred)
rmse = mean_squared_error(y_true, y_pred, squared=False)
r2 = r2_score(y_true, y_pred)
# 結果の出力
print(f"MAE: {mae:.2f}")
print(f"MSE: {mse:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"R²: {r2:.2f}")
# 可視化の例(実際の値と予測値の比較)
import matplotlib.pyplot as plt
plt.scatter(range(len(y_true)), y_true, color='blue', label='Actual')
plt.scatter(range(len(y_pred)), y_pred, color='red', label='Predicted')
plt.title('Actual vs Predicted Values')
plt.xlabel('Sample Index')
plt.ylabel('Bitcoin Price')
plt.legend()
plt.show()MAE: 8.00
MSE: 80.00
RMSE: 8.94
R²: 0.98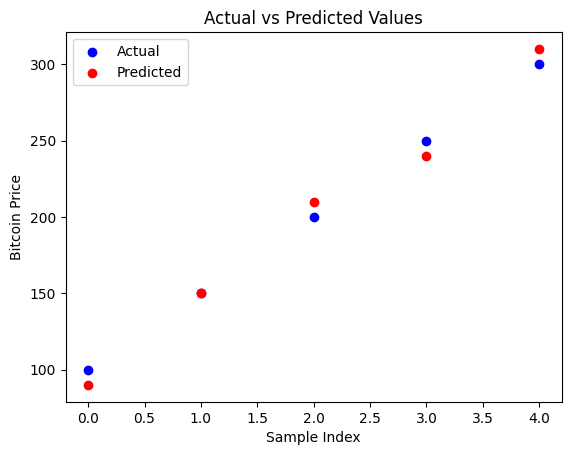
このコードは、予測モデルの評価指標を計算し、実際の値と予測値を比較するグラフを表示します。グラフを見ることで、モデルの予測がどの程度実際のデータに適合しているかを視覚的に評価できます。
モデルの性能評価は、予測の精度を向上させるための重要なステップです。これにより、どのような改善が必要かを判断し、最終的なモデルの選定に役立ちます。
過学習と未学習のバランス
ビットコインの価格予測モデルを作成する際、重要なことは過学習と未学習のバランスを取ることです。過学習は、モデルが訓練データに含まれるランダムなノイズまで学習してしまい、新しいデータに対してうまく一般化できない状態を指します。未学習は、モデルがデータの構造を十分に学習できていないため、訓練データにも新しいデータにもうまく適合できない状態を意味します。
過学習を避けるためには、モデルの複雑さを制御したり、正則化技術を用いたりします。未学習に対処するには、モデルにさらに特徴を追加したり、より複雑なモデルを試したりします。
これらの問題を診断する一つの方法は、訓練データと検証データの両方でモデルの性能を評価することです。通常、訓練データの性能が検証データのそれよりもかなり良い場合は過学習の可能性が高く、両方で性能が低い場合は未学習の可能性があります。
以下に、訓練データと検証データの両方でモデルの性能を評価し、過学習と未学習を可視化するためのサンプルコードを紹介します。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# 仮のビットコイン価格データを生成
np.random.seed(0)
X = np.random.rand(100, 1) * 10 # 特徴量(例:時間)
y = 2 * X.flatten() + 1 + np.random.randn(100) * 2 # 目的変数(価格)
# データを訓練用と検証用に分割
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
# モデルを作成して訓練
model = LinearRegression()
model.fit(X_train, y_train)
# 訓練データと検証データで予測
train_predictions = model.predict(X_train)
val_predictions = model.predict(X_val)
# MSEを計算
train_mse = mean_squared_error(y_train, train_predictions)
val_mse = mean_squared_error(y_val, val_predictions)
# MSEの出力
print(f'Train MSE: {train_mse:.2f}')
print(f'Validation MSE: {val_mse:.2f}')
# 訓練データと検証データの性能をプロット
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.scatter(X_train, y_train, color='blue', label='Training Data')
plt.plot(X_train, train_predictions, color='red', label='Model')
plt.title('Training Data Performance')
plt.xlabel('Feature')
plt.ylabel('Bitcoin Price')
plt.subplot(1, 2, 2)
plt.scatter(X_val, y_val, color='green', label='Validation Data')
plt.plot(X_val, val_predictions, color='red', label='Model')
plt.title('Validation Data Performance')
plt.xlabel('Feature')
plt.ylabel('Bitcoin Price')
plt.legend()
plt.show()Train MSE: 4.15
Validation MSE: 3.24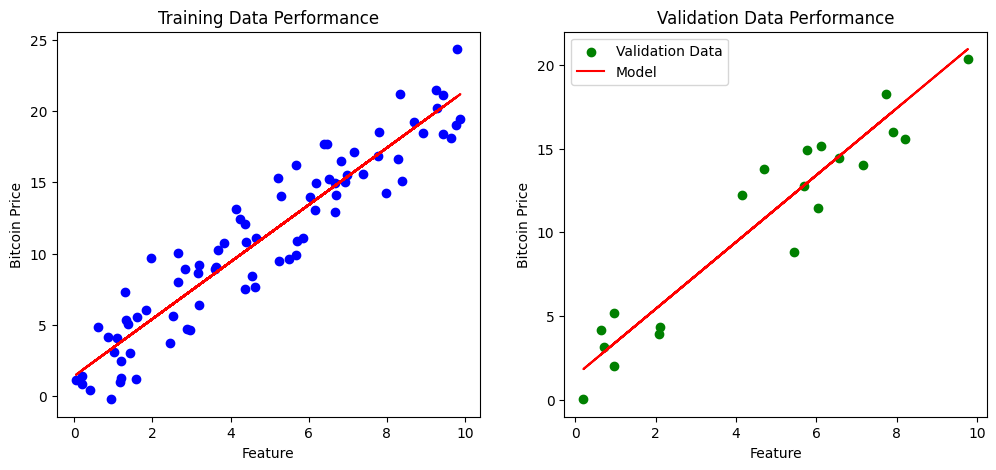
このコードは、訓練データと検証データの両方におけるモデルの予測を可視化し、それぞれの平均二乗誤差(MSE)を計算しています。プロットを見ることで、モデルがデータにどの程度適合しているか、また過学習または未学習の兆候があるかを直感的に理解できます。
ハイパーパラメータチューニングの技術
モデルの精度を向上させるためには、ハイパーパラメータの調整が欠かせません。ハイパーパラメータとは、モデルの学習過程で自動的に決まるパラメータではなく、モデルの構築段階でデータサイエンティストが設定するパラメータのことです。これには、例えば決定木の深さや、ニューラルネットワークの層の数、学習率などが含まれます。
ハイパーパラメータを適切にチューニングすることで、モデルの過学習を防ぎ、未知のデータに対する予測精度を高めることができます。チューニングの方法には様々なアプローチがありますが、一般的には以下のような手法があります。
- グリッドサーチ:
すべての組み合わせを試す総当たり戦法です。指定したハイパーパラメータのリストからすべての組み合わせを作り、それぞれのモデルの性能を評価します。 - ランダムサーチ:
ハイパーパラメータの値をランダムに選び、その組み合わせでモデルを評価します。グリッドサーチよりも計算コストが低い場合が多いです。 - ベイジアン最適化:
以前の評価結果を使って、最も有望なハイパーパラメータの値を予測し、モデルを評価します。計算効率が良く、より少ない試行で良い結果を出すことが期待できます。
以下に、グリッドサーチを使用してハイパーパラメータをチューニングするサンプルコードを紹介します。
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestRegressor
# 仮のビットコイン価格データを生成
X = np.random.rand(100, 1) * 10 # 特徴量(例:時間)
y = 2 * X.flatten() + 1 + np.random.randn(100) * 2 # 目的変数(価格)
# ハイパーパラメータの設定範囲
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [10, 20, 30],
'min_samples_split': [2, 5, 10]
}
# ランダムフォレスト回帰モデル
model = RandomForestRegressor()
# グリッドサーチの実行
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=3, n_jobs=-1, verbose=2)
grid_search.fit(X, y)
# 最適なパラメータの表示
print(f'Best parameters found: {grid_search.best_params_}')Fitting 3 folds for each of 27 candidates, totalling 81 fits
Best parameters found: {'max_depth': 30, 'min_samples_split': 10, 'n_estimators': 100}このコードは、ランダムフォレスト回帰モデルに対してグリッドサーチを行い、最適なハイパーパラメータの組み合わせを見つけ出します。cv=3は3回の交差検証を意味しており、データセットを3つに分割してそれぞれの分割でモデルを検証します。n_jobs=-1は、利用可能なすべてのCPUコアを使って計算を行うことを意味します。
実際のデータサイエンスのプロジェクトでは、データの規模やモデルの複雑さによってハイパーパラメータチューニングの計算コストが大きく異なります。状況に応じて最も適切な手法を選ぶことが重要です。
2024年のビットコイン価格予測
デモデータの予測結果の分析と解釈
ビットコインの価格予測は、様々な要因に基づいて複雑な動きをします。経済指標、市場の感情、政治的な出来事、さらには技術的な要因などが価格に影響を与えるため、予測モデルはこれらの要素を考慮に入れる必要があります。
予測結果の分析と解釈には、モデルが出力した予測値と実際の価格データを比較することが含まれます。この比較から、モデルがどれだけ実際の動きを捉えられているかがわかります。予測精度を測定するためには、平均絶対誤差(Mean Absolute Error, MAE)や平均二乗誤差(Mean Squared Error, MSE)などの統計指標を用いることが一般的です。
ここでは、Pythonを用いてデモデータに基づいた予測モデルの結果を可視化する例を紹介します。以下のコードは、実際の価格と予測価格を比較するグラフを描画します。
import matplotlib.pyplot as plt
import numpy as np
# 仮のビットコイン価格データと予測データを生成
true_prices = np.random.rand(100).cumsum() + 100 # 実際の価格データ
predicted_prices = true_prices + np.random.randn(100) * 2 # 予測価格データ(ノイズを加えた)
# 実際の価格と予測価格をプロット
plt.figure(figsize=(10, 5))
plt.plot(true_prices, label='Actual Prices', color='blue')
plt.plot(predicted_prices, label='Predicted Prices', color='red', linestyle='--')
plt.title('Bitcoin Price Prediction')
plt.xlabel('Time')
plt.ylabel('Price')
plt.legend()
plt.show()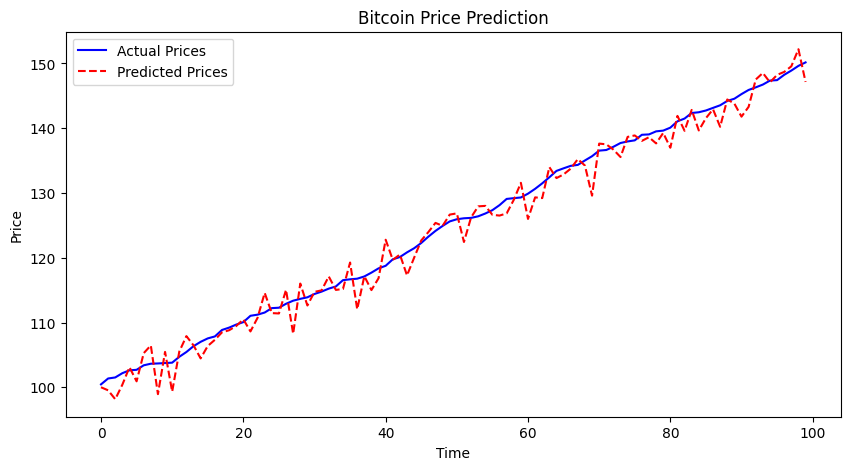
このグラフにより、予測モデルが時間と共にどのように実際の価格に対応しているかを視覚的に評価できます。赤い線(予測価格)が青い線(実際の価格)に近いほど、モデルの予測精度が高いことを示しています。しかし、グラフだけではなく、MAEやMSEなどの数値も併せて考慮することで、モデルの性能をより正確に把握できます。
予測モデルの結果の解釈は、単に数値やグラフを見る以上のことを意味します。結果には、市場の動向、ニュースイベント、予測できない要因が組み込まれている可能性があります。データサイエンティストはこれらの外部要因を理解し、それらが予測結果にどのように影響を与えるかを解釈するスキルが求められます。
予測の信頼性とリスク要因
ビットコイン価格の予測において、信頼性はとても重要です。しかし、予測には常に不確実性が伴います。これは、ビットコイン市場がとても変動が激しく、予期せぬ出来事によって価格が大きく動くことがあるからです。予測モデルは過去のデータに基づいて未来を予測しますが、過去のパターンが必ずしも未来に続くとは限りません。
信頼性を高めるためには、予測モデルが過去のデータをどれだけ正確に再現できるかを評価することが重要です。これは、モデルがデータの構造を捉えているかどうかを示します。しかし、過去のデータに過度に適合すると、新しいデータに対してうまく機能しない「過学習」という問題が生じる可能性があります。
リスク要因としては、以下のようなものが挙げられます:
- 経済的・政治的な変化:経済危機や政府による規制変更など、予測できない出来事が価格に影響を与えることがあります。
- 市場の感情:投資家の感情や市場のセンチメントは、価格に短期的な影響を与えることがあります。
- 技術的な要因:ビットコインのネットワークアップデートやセキュリティ関連の問題も価格に影響を及ぼすことがあります。
これらのリスク要因をモデルに組み込むことは難しいですが、リスク管理として、モデルの不確実性を定量化できます。例えば、信頼区間を使用して予測の不確実性を表現できます。Pythonのサンプルコードを用いて、予測価格に対する信頼区間を可視化できます。
# 信頼区間の描画を行うサンプルコード
# 予測価格とその信頼区間を生成
predicted_prices = np.linspace(100, 200, 100) # 予測価格
confidence_interval = np.random.randn(100) * 10 # 信頼区間の幅
# 信頼区間をプロット
plt.fill_between(range(len(predicted_prices)),
predicted_prices - confidence_interval,
predicted_prices + confidence_interval,
color='gray', alpha=0.5)
plt.plot(predicted_prices, label='Predicted Prices', color='blue')
plt.title('Confidence Interval of Predictions')
plt.xlabel('Time')
plt.ylabel('Price')
plt.legend()
plt.show()
このグラフでは、信頼区間が価格予測の不確実性を表しています。灰色の領域が広いほど、予測の不確実性が大きいことを意味します。これにより、予測価格に対する信頼性の度合いを視覚的に把握できます。
ChatGPTとの連携
ChatGPTを活用したデータ分析
ChatGPTは、膨大なデータセットから学習した人工知能であり、テキストデータの解析や生成に長けています。Pythonプログラミング言語との連携を通じて、ChatGPTはビットコイン価格の予測に役立つ洞察を提供できます。たとえば、過去の市場データやニュース記事からトレンドを読み取り、それを予測モデルのインプットとして活用できます。
以下のPythonコードは、ChatGPTが生成した市場の要約テキストを処理し、キーワードの頻度を分析する方法の一例です。
from collections import Counter
import matplotlib.pyplot as plt
# ChatGPTが生成した市場要約テキストのサンプル
market_summary = """
Bitcoin has risen 5% in the past 24 hours. Market experts attribute this rise to recent economic data. The announcement of new policies is seen as having boosted investor sentiment. However, some analysts warn that the market is overheating.
"""
# テキストから単語の頻度をカウント
word_counts = Counter(market_summary.split())
# 最も一般的な単語の上位5つを抽出
common_words = word_counts.most_common(5)
# データを可視化
words, counts = zip(*common_words)
plt.bar(words, counts)
plt.title('Top 5 Common Words in Market Summary')
plt.xlabel('Words')
plt.ylabel('Frequency')
plt.show()
このコードでは、まず市場の要約テキストをmarket_summary変数に格納し、それを単語に分割してCounterオブジェクトで頻度を数えています。その後、最も頻繁に出現する5つの単語とその頻度を抽出し、Matplotlibを用いてバーチャートとして可視化しています。
ChatGPTを利用した市場動向のリアルタイム分析
ChatGPTは、リアルタイムデータ処理にも適しています。例えば、ソーシャルメディアからのストリーミングデータや、リアルタイムで更新されるニュースフィードを分析し、市場のセンチメントやトレンドを即座に把握できます。Pythonを用いて、リアルタイムデータを取り込み、それをChatGPTで分析するプロセスを自動化できます。
ChatGPTと人間の協働による意思決定
ChatGPTはデータ分析の助けとなるだけでなく、人間の意思決定プロセスを補完することもできます。たとえば、予測モデルが示す結果と、ChatGPTが提供する市場の洞察を組み合わせることで、より総合的な視点から投資判断を下すことができます。人間の直感とChatGPTのデータ駆動型アプローチを融合させることで、よりバランスの取れた投資戦略を立てることが可能です。
Pythonでこれらのプロセスを統合し、可視化や分析のためのコードを書くことで、データサイエンティストはビットコイン市場の予測においてより強力なツールを手にできます。
ビットコイン予測におけるAIの応用
AIと機械学習がもたらす可能性
AIと機械学習はビットコインの価格予測に有効です。これらの技術を使用することで、過去の価格データや市場のセンチメント、経済指標など、多様なデータソースから複雑なパターンを抽出し、それを基に将来の価格動向を予測できます。
たとえば、機械学習モデルをトレーニングして、価格の上昇や下降のトレンドを予測するための特徴量を選択し、価格予測のためのモデルを構築できます。以下のPythonコードは、簡単な機械学習モデルのトレーニングプロセスを示しています。
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
# デモデータの生成(実際の価格データに基づくサンプルとする)
np.random.seed(0)
x = np.random.rand(100, 1) # 特徴量
y = x * 100 + (np.random.rand(100, 1) - 0.5) * 20 # 目的変数(価格)
# データをトレーニングセットとテストセットに分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# ランダムフォレスト回帰モデルのトレーニング
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(x_train, y_train.ravel())
# テストセットでの予測
predictions = model.predict(x_test)
# 予測結果の可視化
plt.scatter(x_test, y_test, color='black', label='Actual Prices')
plt.scatter(x_test, predictions, color='red', label='Predicted Prices')
plt.title('Bitcoin Price Prediction')
plt.xlabel('Features')
plt.ylabel('Price')
plt.legend()
plt.show()
このコードでは、ランダムフォレスト回帰モデルを使用して、ビットコインの価格を予測しています。まず、デモデータを生成し、トレーニングセットとテストセットに分割します。モデルをトレーニングした後、テストセットで予測を行い、実際の価格と予測価格をプロットして比較しています。
ディープラーニングの応用
ディープラーニングは、特に時系列データの分析において優れた性能を発揮します。ビットコインの価格予測においても、ディープラーニングは価格変動の背後にある複雑な因果関係やパターンの理解に役立ちます。リカレントニューラルネットワーク(RNN)やその派生形であるLSTM(Long Short-Term Memory)ネットワークは、価格の時間的な動きを捉えるのに適しています。
以下のPythonコードは、Kerasを使用して簡単なLSTMモデルを定義し、ビットコインの価格予測のためにモデルを構築します。
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
# デモデータの生成
timesteps = 10 # 10日間の価格データを使用して次の日の価格を予測
data_length = 300 # デモデータの全体の長さ
np.random.seed(0)
data = np.random.rand(data_length) * 100
# LSTMに供給するためのデータの整形
x_train = []
y_train = []
for i in range(timesteps, data_length):
x_train.append(data[i-timesteps:i])
y_train.append(data[i])
x_train, y_train = np.array(x_train), np.array(y_train)
# LSTMモデルの定義
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1], 1)))
model.add(LSTM(units=50))
model.add(Dense(units=1))
# モデルのコンパイル
model.compile(optimizer='adam', loss='mean_squared_error')
# モデルのトレーニング
model.fit(x_train.reshape(x_train.shape[0], x_train.shape[1], 1), y_train, epochs=100, batch_size=32)Epoch 95/100
10/10 [==============================] - 0s 5ms/step - loss: 906.0565
Epoch 96/100
10/10 [==============================] - 0s 5ms/step - loss: 903.8284
Epoch 97/100
10/10 [==============================] - 0s 5ms/step - loss: 901.6175
Epoch 98/100
10/10 [==============================] - 0s 5ms/step - loss: 898.7753
Epoch 99/100
10/10 [==============================] - 0s 5ms/step - loss: 896.3054
Epoch 100/100
10/10 [==============================] - 0s 5ms/step - loss: 893.7707
<keras.src.callbacks.History at 0x7c8c037f3310>このサンプルコードでは、まずランダムな価格データを生成し、LSTMモデルに適した形にデータを整形します。次に、LSTMレイヤーを含むモデルを構築し、コンパイルしてトレーニングを行います。これは、ディープラーニングがビットコインの価格予測にどのように応用されるかの基本的な例です。実際には、より複雑なデータセットと、調整されたハイパーパラメータを使用してより正確な予測を行う必要があります。
まとめ
ビットコイン価格予測の振り返り
ビットコインの価格予測に必要なデータの理解から始め、Pythonを用いた予測モデルの構築、モデルの評価、そして2024年のビットコイン価格予測に至るまで、一連のステップを詳しく解説しました。特に、データの前処理、特徴量エンジニアリング、モデルの選定とトレーニング、そしてバリデーションの過程は、実際の価格予測においてとても重要です。
予測モデルの精度を最大化するためには、過学習と未学習のバランスを適切にとること、そしてモデルのハイパーパラメータを適切にチューニングすることが不可欠です。これらのプロセスで、データに潜むパターンを把握し、将来の価格動向に対する洞察を深めることができました。
今後の暗号通貨市場と技術の発展
ビットコインを含む暗号通貨市場は、依然として発展を続けており、その変動性は高いままです。AIと機械学習、そしてディープラーニングの進歩は、これらの市場の予測をより精度高く行うための鍵となるでしょう。今回紹介した技術は、将来的にも市場分析や予測において中心的な役割を果たします。

▼AIを使った副業・起業アイデアを紹介♪

