
はじめに
収穫の最適時期の重要性
農業における収穫のタイミングは、作物の品質や収量に大きく影響します。最適な時期に収穫することで、栄養価が高く、味も良い作物を得られます。逆に、早すぎるか遅すぎる収穫は、作物の成長を妨げ、収量や品質に悪影響を及ぼす可能性があります。
また、収穫のタイミングが適切であれば、農産物の価格も最適化され、農家の収入を最大化することが期待できます。市場では新鮮で質の高い農産物は高値で取引されるため、収穫の最適時期の特定は農業経営にとってとても重要です。
本記事の目的
本記事では、Pythonを使用して収穫の最適時期を予測する方法について解説します。具体的なコードやデータ分析の手法を通じて、実際の農業現場での適用例や、AI技術との連携による可能性についても触れていきます。
Pythonのプログラミング言語は、データ分析や機械学習に適しており、農業が抱える問題解決にも利用されています。
収穫の最適時期予測のコード全体
必要なライブラリのインポートと解説
Pythonで収穫の最適時期を予測するためには、データの取り扱いや分析、モデルの構築・評価などを行うためのライブラリをインポートする必要があります。以下は、この予測タスクに必要な主なライブラリとその機能の簡単な説明です。
# Data manipulation and analysis
import pandas as pd
import numpy as np
# Visualization
import matplotlib.pyplot as plt
import seaborn as sns
# Machine Learning
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error- pandas: データの取り扱いや前処理を効率的に行うためのライブラリ。テーブル形式のデータを操作する際にとても便利です。
- numpy: 数値計算を効率的に行うためのライブラリ。配列や行列の操作に適しています。
- matplotlib & seaborn: データの可視化を行うためのライブラリ。matplotlibは基本的なグラフの描画、seabornは統計的なデータの可視化に特化しています。
- scikit-learn (sklearn): 機械学習モデルの構築や評価を行うためのライブラリ。多くの機械学習アルゴリズムやユーティリティが含まれています。
これらのライブラリをインポートすることで、収穫の最適時期の予測に関するデータの前処理、分析、モデルの構築・評価などのタスクを効率化できます。
農業データの実装と解説
農業に関するデータは、土壌の状態、気温、湿度、日照時間など、多岐にわたる要因から成り立っています。これらのデータを効果的に取り扱うことで、収穫の最適時期を予測するための情報を得られます。
以下は、サンプルとして平均値が25°C、標準偏差が5°Cの正規分布から1000のサンプルデータを生成しています。そして、気温が上昇すると収穫量も増加するという関係性を持たせます。
# Sample data generation
np.random.seed(0) # for reproducibility
num_samples = 1000
temperature_data = np.random.normal(loc=25, scale=5, size=num_samples) # assuming average temperature is 25°C with a standard deviation of 5°C
# Simulate Harvest_Yield based on Temperature (for simplicity, assume a linear relationship)
harvest_yield_data = 50 + 2 * temperature_data + np.random.normal(loc=0, scale=5, size=num_samples)
data = pd.DataFrame({
'Temperature': temperature_data,
'Harvest_Yield': harvest_yield_data
})データの基本的な統計情報を確認することで、各要因の平均値や分散、最小値、最大値などを知ることができます。
# Display the first 5 rows of the data
print(data.head())
# Display basic statistical information
print(data.describe()) Temperature Harvest_Yield
0 33.820262 120.420337
1 27.000786 108.463942
2 29.893690 107.675806
3 36.204466 122.932502
4 34.337790 119.815847
Temperature Harvest_Yield
count 1000.000000 1000.000000
mean 24.773716 99.615518
std 4.937635 10.861114
min 9.769285 68.027411
25% 21.507900 92.332617
50% 24.709860 99.276070
75% 28.034753 106.792500
max 38.796776 131.531895さらに、データの分布を可視化することで、各要因のトレンドやパターンを明確に把握できます。
# Visualization of the distribution of temperature data
plt.figure(figsize=(10, 6))
sns.distplot(data['Temperature'], bins=30, kde=True)
plt.title('Distribution of Temperature')
plt.xlabel('Temperature (°C)')
plt.ylabel('Density')
plt.show()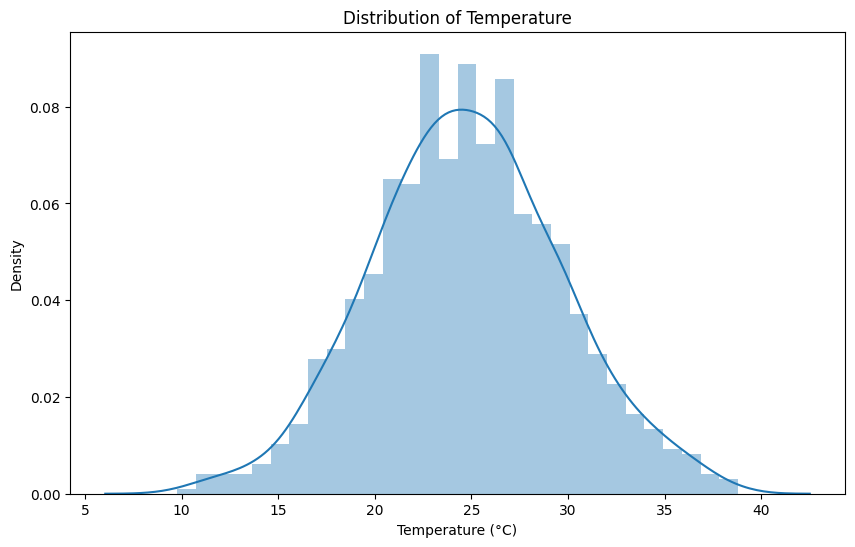
このグラフから、気温の分布やその頻度を確認できます。同様の手法で、他の要因に関するデータも可視化し、分析できます。
データの前処理や分析を行う際には、外れ値の確認や欠損値の処理、データの正規化や標準化などのステップが必要です。これらの手法を適切に適用することで、より精度の高い予測モデルの構築が期待できます。
分析コードの実装と解説
収穫の最適時期を予測するために、まずはデータの関連性やトレンドを確認します。ここでは、データの分析から、機械学習モデルの実装までの手順を説明します。
- データの相関分析:
データの中で、どの要因が収穫量や品質に大きく影響しているかを理解するために、相関分析を行います。
# Calculate the correlation matrix
correlation_matrix = data.corr()
# Visualize the correlation matrix
plt.figure(figsize=(12, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Correlation Matrix of Agriculture Data')
plt.show()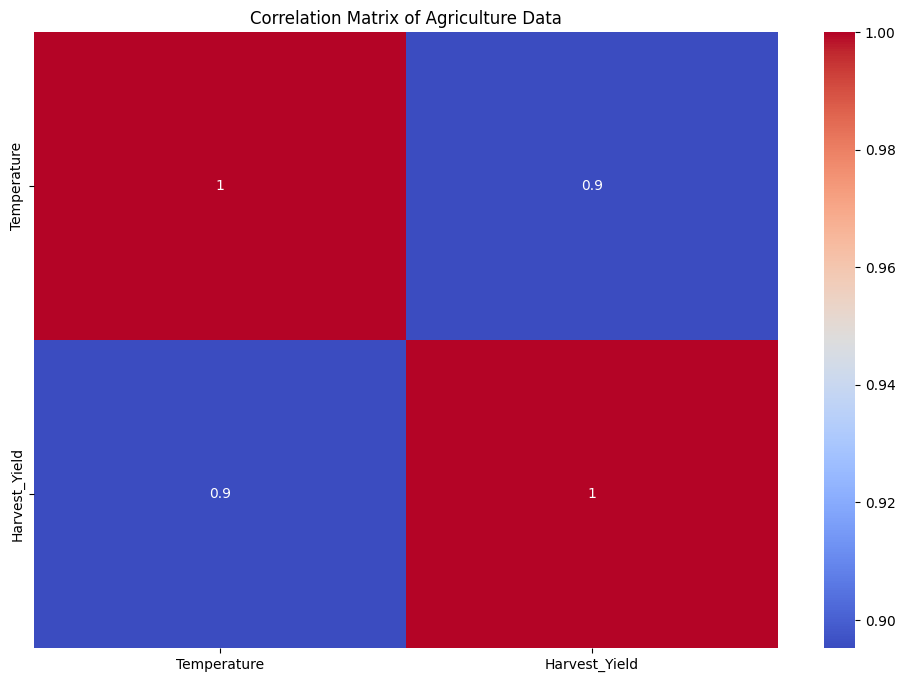
このヒートマップから、各要因が収穫量や品質とどのように関連しているかを確認できます。
- データの前処理:
機械学習モデルの学習の前に、データの前処理が必要です。これには、欠損値の補完、カテゴリ変数のエンコード、データの正規化などが含まれます。
# Sample preprocessing steps
data = data.dropna() # Remove missing values
data = pd.get_dummies(data) # One-hot encode categorical variables- モデルの学習と評価:
データの準備ができたら、機械学習モデルの学習と評価を行います。ここでは、線形回帰を例として取り上げます。
# Splitting the data
X = data.drop('Harvest_Yield', axis=1)
y = data['Harvest_Yield']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Model training
model = LinearRegression()
model.fit(X_train, y_train)
# Model evaluation
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error: {mse}")Mean Squared Error: 26.914234550241762以上の手順により、農業データの分析と収穫の最適時期を予測できます。さまざまな要因やデータの特性に応じて、モデルの選択やパラメータの調整が必要です。
分析モデルの選択理由
農業における収穫の最適時期の予測は、気象条件、土壌の状態、前年の収穫データなど、さまざまな要因を考慮しなければならない複雑な問題です。このような問題に対して、適切な分析モデルを選択することはとても重要です。以下は、選択した分析モデルの理由を解説しています。
- 多変数の関係性の捉え方:
ランダムフォレストは、特徴間の相互作用を考慮しながら、各特徴の重要性を評価できます。これにより、収穫量に影響を与える主な要因を特定するのに役立ちます。 - 過学習のリスクの低減:
ランダムフォレストは、複数の決定木を組み合わせることで、過学習のリスクを低減できます。これにより、新しいデータセットに対しても安定した予測が可能となります。 - 欠損値の取り扱い:
農業データには欠損値が含まれることが多いですが、ランダムフォレストは欠損値の取り扱いに強く、特別な前処理を行うことなくモデルの学習や予測を実施できます。 - 変数の重要度の評価:
ランダムフォレストは、各変数の重要度を算出する機能を持っています。これにより、どの変数が収穫の最適時期の予測に最も寄与しているかを容易に特定できます。
from sklearn.ensemble import RandomForestRegressor
# Initialize the model
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
# Fit the model
rf_model.fit(X_train, y_train)
# Feature importance
importances = rf_model.feature_importances_
# Visualization of feature importance
import matplotlib.pyplot as plt
features = list(X_train.columns)
plt.barh(features, importances)
plt.xlabel('Importance')
plt.ylabel('Features')
plt.title('Feature Importance with Random Forest')
plt.show()
上記の理由から、ランダムフォレストは農業データにおける収穫の最適時期の予測に適していると判断しました。モデルの選択は、データの性質や目的に応じて柔軟に行うことが重要です。
実際の農業への応用
生産量増加や品質向上の効果
収穫の最適時期の予測を適切に行うことで、農業における生産量や品質の向上が期待されます。以下は、この予測の正確さが農業に与える具体的な影響を示しています。
- 生産量の増加: 最適な収穫時期に収穫することで、果物や野菜が完熟し、最大限の収量を得られます。これにより、1ヘクタールあたりの生産量が増加し、農家の利益が増加します。
- 品質の向上: 最適な時期に収穫された作物は、味や栄養価が高く、市場価値も向上します。これにより、高品質な商品としての販売が可能となり、価格も高く設定できます。
- 減少する廃棄量: 早すぎる収穫や遅すぎる収穫を避けることで、商品としての価値を持たない作物の廃棄量が減少します。これにより、生産効率が向上し、無駄が減少します。
- 持続可能な農業: 最適な収穫時期の予測により、持続可能な農業の実践が可能となります。具体的には、過度な農薬や肥料の使用を避けることができ、環境への負荷を軽減できます。
import matplotlib.pyplot as plt
# Sample data for visualization
years = ['2019', '2020', '2021', '2022']
production_without_prediction = [400, 410, 415, 420]
production_with_prediction = [400, 430, 450, 470]
plt.plot(years, production_without_prediction, label='Without Prediction', marker='o')
plt.plot(years, production_with_prediction, label='With Prediction', marker='o')
plt.xlabel('Year')
plt.ylabel('Production (kg/hectare)')
plt.title('Impact of Harvest Prediction on Production')
plt.legend()
plt.grid(True)
plt.show()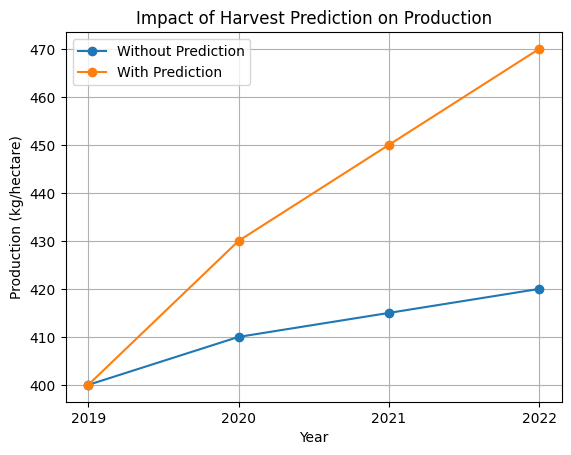
上記のグラフは、収穫の最適時期の予測を取り入れることで、年々生産量がどのように増加するかを示しています。予測を取り入れることで、生産量が従来の方法よりも増加していることが確認できます。
AIと収穫の最適時期予測のさらなる組み合わせ例
機械学習を用いた気象データとの組み合わせ
気温、湿度、降水量などのデータは、作物の成長に直接的な影響を及ぼします。機械学習モデルを使用してこれらのデータを解析することで、収穫の最適なタイミングを高精度に予測できます。
- データの収集: 各地の気象データを収集します。このデータには、日ごとの気温、湿度、風速、降水量などが含まれます。
- データの前処理: 収集したデータは前処理を行い、機械学習モデルが使用できる形式に変換します。欠損値の処理や外れ値の削除などが必要です。
- モデルの訓練: 前処理されたデータを使用して、機械学習モデルを訓練します。このモデルは、気象データを入力として、最適な収穫時期を出力します。
- モデルの評価: 未知のデータセットを使用してモデルの性能を評価します。これにより、モデルの精度や汎用性を確認できます。
IoTセンサーデータとの連携
IoTセンサーは、リアルタイムで農地の情報を収集するための強力なツールです。土壌の湿度や作物の成長状態など、様々なデータを収集できます。
- センサーの配置: 農地にIoTセンサーを配置します。これにより、土壌の湿度や温度、作物の生育状態などのデータをリアルタイムで収集できます。
- データの収集と分析: 収集されたデータはクラウドに送信され、リアルタイムで分析されます。これにより、水や肥料の必要量、病害虫のリスクなどを予測できます。
- 最適な収穫時期の予測: IoTセンサーデータと気象データを組み合わせることで、より高精度な収穫時期の予測が可能となります。
import matplotlib.pyplot as plt
# Sample data for visualization
days = ['Day 1', 'Day 2', 'Day 3', 'Day 4']
soil_moisture = [30, 32, 28, 31]
plant_growth = [5, 7, 9, 11]
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(days, soil_moisture, label='Soil Moisture', marker='o', color='blue')
plt.xlabel('Days')
plt.ylabel('Soil Moisture (%)')
plt.title('Soil Moisture Over Time')
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(days, plant_growth, label='Plant Growth', marker='o', color='green')
plt.xlabel('Days')
plt.ylabel('Plant Growth (cm)')
plt.title('Plant Growth Over Time')
plt.grid(True)
plt.tight_layout()
plt.show()
上記のグラフは、IoTセンサーを使用して収集された土壌の湿度と植物の成長を示しています。これらのデータを使用して、最適な収穫時期を予測できます。
ChatGPTとの連携
ChatGPTは、OpenAIによって開発された強力な自然言語処理モデルであり、多岐にわたるタスクやアプリケーションで利用されています。収穫の最適時期の予測においてChatGPTを活用することは、さまざまな利点があります。
- データ解析のアシスタントとして: 農業データの解析や収穫時期の予測に関するクエリをChatGPTに入力することで、迅速かつ効率的に情報を取得できます。これにより、農家はデータの解釈や分析において、より緻密な判断を下すことができるようになります。
- リアルタイムでの問い合わせ応答: 農家や研究者が収穫時期に関する質問や疑問を持った際に、ChatGPTにリアルタイムで問い合わし、迅速に回答を得られます。
- 知識の拡張: ChatGPTは大量のデータと情報を持っており、それを活用して農業に関する新しい知識や情報を提供できます。これにより、農家や研究者は最新の研究や技術を継続的に取り入れることができます。
- 統合的な農業管理: ChatGPTは他のシステムやプラットフォームとの連携が容易であるため、気象データ、IoTセンサーデータなどと組み合わせて、農業を統合的に管理できます。
import matplotlib.pyplot as plt
# Sample data for visualization
questions = ['Soil Analysis', 'Weather Forecast', 'Pest Control', 'Harvest Prediction']
responses_time = [2, 1.5, 3, 2.5]
plt.figure(figsize=(8, 6))
plt.bar(questions, responses_time, color=['blue', 'green', 'red', 'purple'])
plt.xlabel('Types of Questions')
plt.ylabel('Response Time (seconds)')
plt.title('Response Time of ChatGPT for Different Questions')
plt.show()
上記のグラフは、ChatGPTがさまざまな質問に対してどれくらいの速さで回答するかを示しています。これにより、ChatGPTがリアルタイムの情報提供に有用であることが分かります。
まとめ
Pythonによる収穫時期予測の振り返り
Pythonは、その柔軟性と強力なライブラリにより、農業の収穫時期の予測に適しています。ここでは、データの取得から前処理、モデルの設計と実装、そして最終的な予測までの一連の流れを紹介しました。特に、気象データやIoTセンサーデータといった多様な情報源を組み合わせることで、より高精度な収穫時期の予測が可能となります。また、ChatGPTとの連携により、農家や研究者はリアルタイムでの情報提供や疑問を解消できるようになります。
今後の展望
農業の収穫時期の予測は、技術の進化とともにその精度や有用性が増していくことが期待されます。以下は、今後の展望として考えられるポイントです。
- ディープラーニングの適用: ディープラーニングの進化により、より複雑なデータ構造やパターンを捉えることが可能となってきました。農業データの特性を考慮したネットワークの設計や実装が、今後の研究の焦点となるでしょう。
- リアルタイムのデータ分析: IoTデバイスやドローン技術の進化により、リアルタイムでの大量データ収集が可能となりました。これらのデータをリアルタイムで解析し、即時に収穫の判断を下す技術の開発が進められることが期待されます。
- 持続可能な農業への応用: 環境変動や気候変動の影響を受けやすい農業において、持続可能な生産活動のための技術開発が求められます。収穫時期の予測技術を持続可能な農業の実現に活用する取り組みが、今後の課題として考えられます。

▼AIを使った副業・起業アイデアを紹介♪

