
AIエンジニアやプログラマーに転職して、ガン細胞を破壊する技術を開発しましょう。
最近の研究で、がん細胞を乗っ取って自滅させる革新的な方法が開発されました。
ここでは、がん細胞を破壊する技術に使用されるIT技術や具体的なPythonコードを解説しますので、AIエンジニアやプログラマーに転職したい方には必読の内容です。
また、この技術を応用したビジネスやアイデアも紹介しますので、新しい視点や発想を得られますよ。
ガン細胞を乗っ取り自滅させる新技術
科学者たちは、新しい研究で、ガン細胞を乗っ取り、自滅させる方法を開発しました。ガン細胞自体を改変して隣接する腫瘍細胞を攻撃できるそうです。
この研究は、ガン治療の新たな可能性を示すものであり、将来的により多くのガン患者に恩恵をもたらすことが期待されています。
AIでがん細胞を破壊する技術の開発:利用されるIT技術
がん細胞を破壊する技術の開発に利用される、主なIT技術を挙げてみましょう。
- プログラム言語:
Python: 機械学習やデータ処理に広く使用される言語で、豊富なライブラリ(例:TensorFlow、PyTorch)を活用してAIモデルを構築します。
R: データ解析や統計分析に特化しており、特に生物医学研究でよく使用されます。 - AI技術:
機械学習(Machine Learning): データからパターンを学習し、予測や分類を行います。がん細胞の特徴を学習して、特定の治療法を適用するモデルを構築します。
深層学習(Deep Learning): ニューラルネットワークを使用して複雑なデータを処理し、高度な画像認識や予測を可能にします。
強化学習(Reinforcement Learning): エージェントが環境との相互作用によって最適な行動を学習します。がん治療の最適な戦略を見つけるのに使用されます。 - データベース技術:
SQLデータベース: 大規模な患者データや研究データの管理に使用されます。例:MySQL、PostgreSQL。
NoSQLデータベース: 非構造化データの管理に適しており、大量のバイオメディカルデータを効率的に処理できます。例:MongoDB、Cassandra。 - クラウド技術:
AWS(Amazon Web Services): 大規模なデータ処理とAIモデルのトレーニングに使用されるクラウドプラットフォーム。計算リソースとストレージを提供します。
Google Cloud Platform(GCP): AI/MLのツールを含むクラウドサービスを提供し、データ解析やモデルのデプロイに使用されます。
Microsoft Azure: AI開発者向けのツールやサービスを提供し、スケーラブルなクラウドインフラをサポートします。 - セキュリティ対策:
データ暗号化: 患者データの機密性を保護するため、データの保存と転送時に暗号化技術を使用します。
アクセス制御: データベースやシステムへのアクセスを制限し、認証と認可を強化します。
監視とログ管理: システムの異常検知とトラブルシューティングのために、活動ログの監視と管理を行います。
各IT技術を活用することで、がん細胞の破壊技術の研究と開発が進められています。
PythonとAIでがん細胞を破壊する技術を開発
PythonとAIで、がん細胞を破壊する技術を開発するコードを書いてみましょう。
以下は、がん細胞の識別と治療効果を予測する機械学習モデルです。がん細胞と健康な細胞のデータを用いて機械学習モデルを訓練し、分類します。
コード解説
- データ生成:
サンプルデータをPythonコード内で生成します。 - データの可視化:
サンプルデータを可視化します。 - 機械学習モデルの訓練:
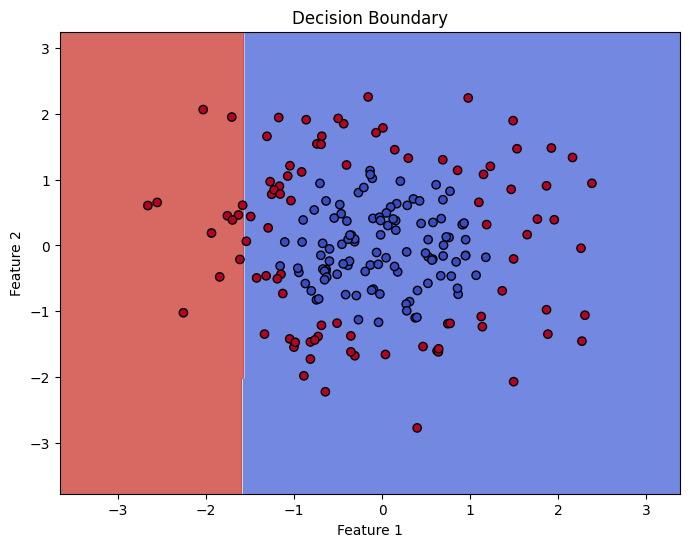
ロジスティック回帰モデルを用いて訓練します。 - 結果の可視化:
訓練結果をグラフで表示します。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# Generate sample data
np.random.seed(0)
num_samples = 200
features = np.random.randn(num_samples, 2)
labels = (np.sum(features**2, axis=1) > 1.5).astype(int)
# Convert to DataFrame for better handling
data = pd.DataFrame(features, columns=['Feature1', 'Feature2'])
data['Label'] = labels
# Visualize the data
plt.figure(figsize=(8, 6))
plt.scatter(data['Feature1'], data['Feature2'], c=data['Label'], cmap='coolwarm', marker='o')
plt.title('Sample Data for Cancer Cells')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.3, random_state=0)
# Train a logistic regression model
model = LogisticRegression()
model.fit(X_train, y_train)
# Predict the test set
y_pred = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
print(f'Accuracy: {accuracy * 100:.2f}%')
print('Confusion Matrix:')
print(conf_matrix)
print('Classification Report:')
print(class_report)
# Plot decision boundary
def plot_decision_boundary(model, X, y):
h = .02 # step size in the mesh
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, cmap='coolwarm', alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='coolwarm', edgecolors='k', marker='o')
plt.title('Decision Boundary')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
plot_decision_boundary(model, features, labels)Accuracy: 58.33%
Confusion Matrix:
[[31 0]
[25 4]]
Classification Report:
precision recall f1-score support
0 0.55 1.00 0.71 31
1 1.00 0.14 0.24 29
accuracy 0.58 60
macro avg 0.78 0.57 0.48 60
weighted avg 0.77 0.58 0.49 60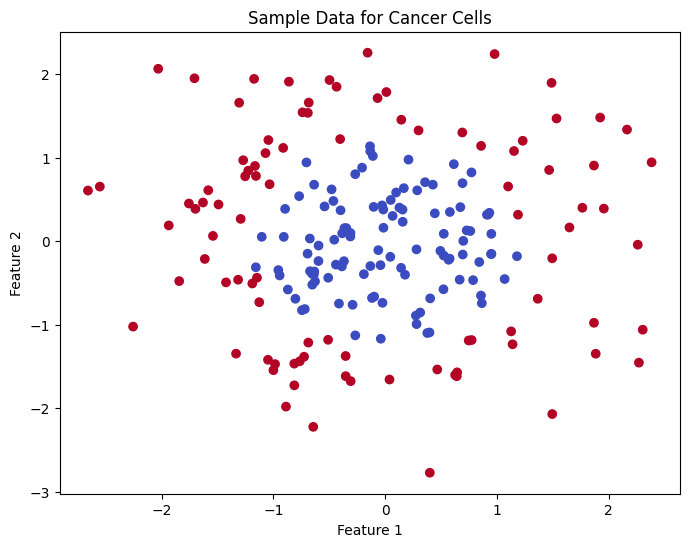
コード解説
- データ生成:
np.random.seed(0)で乱数シードを固定し、再現性を確保。featuresにランダムなデータを生成し、labelsでがん細胞かどうかをラベル付け。 - データの可視化:
plt.scatterを用いて、特徴量を2次元平面上にプロットし、がん細胞と健康な細胞を色分け。 - データの分割:
train_test_splitを使用して、データを訓練セットとテストセットに分割。 - 機械学習モデルの訓練:
ロジスティック回帰モデルを訓練データで訓練し、model.fitでモデルをフィット。 - 結果の評価:
accuracy_score、confusion_matrix、classification_reportを使用してモデルの性能を評価し、結果を出力。 - 決定境界のプロット:
plot_decision_boundary関数を定義し、訓練したモデルの決定境界を可視化。
AIでがん細胞を破壊する技術の開発:応用アイデア
AIでがん細胞を破壊する技術の、応用アイデアを考えてみましょう。
同業種への応用アイデア
- 他のガン治療:
乳ガンや肝ガンなど、他の種類のガンに対して同様のAI技術を応用し、効果的な治療法を開発。 - 遺伝子治療:
遺伝子編集技術を用いて、他の遺伝子異常による病気の治療に応用。 - 個別化医療:
患者の遺伝子情報を元に、最適な治療法をAIが提案するシステムの開発。 - 薬剤開発の効率化:
新しい抗ガン剤の開発プロセスにAIを導入し、薬剤の効果と副作用を予測する。 - 治療効果のモニタリング:
AIを使って、治療の進行状況をリアルタイムでモニタリングし、治療計画の最適化を図る。
他業種への応用アイデア
- 製造業の品質管理:
製造工程の欠陥や不良品を自動的に検出し、改善するAIシステムの開発。 - 農業の病害虫管理:
農作物に対する病害虫の発生をAIで予測し、効果的な対策を自動的に実施するシステムの開発。 - 金融業のリスク管理:
金融取引データを分析し、詐欺やリスクを予測するAIシステムの導入。 - 物流業の最適化:
配送ルートや在庫管理を最適化するAIアルゴリズムの開発。 - 教育分野の個別化学習:
各生徒の学習進度や理解度をAIが分析し、最適な学習プランを提案するシステムの開発。
AIでがん細胞を破壊する技術は、さまざまな分野に応用できそうですね。まさに、早い者勝ちのビジネスチャンスです。
AIでがん細胞を破壊する技術の開発:まとめ
AIでがん細胞を破壊する技術の開発について解説しました。この技術は、がん細胞を乗っ取り自滅させる方法を用いています。
がん細胞を破壊するために必要なIT技術や、具体的なPythonコードを紹介したので、AIエンジニアやプログラマーに転職を考えている方の参考になったと思います。
また、この技術を応用した新しいビジネスアイデアも紹介しました。
あなたもAIエンジニアやプログラマーに転職して、がん細胞を破壊する技術を開発しましょう。これからの時代、病気を治すのは医者ではなく、AIエンジニアです。

▼AIを使った副業・起業アイデアを紹介♪

