AIエンジニアやプログラマーに転職して、AIで被リンクを分析しましょう。
最近のニュースによると、被リンクの重要性は低下しているものの、いまでもSEOにおいて重要な役割を果たしています。
AIで被リンクの分析に使用されるIT技術や具体的なPythonコードも解説しますので、AIエンジニアやプログラマーに転職したい方には必読の内容です。
また、被リンク分析の技術を応用したビジネスやアイデアも紹介しますので、新しい視点や発想を得られますよ。
2024年のSEOで被リンクはどれほど重要か?
https://searchengineland.com/backlinks-seo-importance-442529
2024年においても、被リンクはSEOにおいて重要ということです。
被リンクの量と質は検索順位に影響しますが、Googleは被リンクの重要性を過大評価しないよう注意を促しています。
Gary IllyesとJohn Muellerの発言によると、被リンクは上位3つのランキング要素には含まれず、ページをランク付けするために必要な被リンクは少なくなっています。
しかし、リンクとPageRankは依然としてGoogleのアルゴリズムの一部だそうです。
AhrefsやBacklinko、Monster Insightsの研究では、被リンクの多様性と質がランキングに強く関連しているとされています。
特に高品質のウェブサイトからの被リンクが重要です。リンクビルディングは効果が減少しているため、被リンクを「構築」するのではなく、「獲得」する手法が求められます。
AIで被リンクの分析:利用されるIT技術
SEOにおいて、被リンクの重要性は低下しているものの、いまだに重要と言うことですね。
被リンクのSEO効果は過大評価されています。重要なのはさまざまなところからの被リンクで、「自作自演の被リンク」や「購入した被リンク」などは効果なし、ということです。
AIで被リンク分析に使用される主なIT技術は、下記のとおりです。
- プログラム言語
Python:AIとデータ分析に広く使用される言語で、多くのライブラリが豊富に揃っています。
R:統計分析やデータ可視化に強みがあり、データサイエンスに適しています。 - AI技術
機械学習:被リンクのパターンを分析し、重要なリンクを特定するために使用されます。
自然言語処理(NLP):リンク元のテキストデータを解析し、リンクの質や関連性を評価します。 - データベース技術
SQLデータベース:リンクデータの保存とクエリに使用されます。たとえば、MySQLやPostgreSQL。
NoSQLデータベース:大規模データの処理に適しており、MongoDBやCassandraなどがあります。 - クラウド技術
AWS(Amazon Web Services):データの保存、計算リソースの提供、AIモデルのデプロイに使用されます。
Google Cloud Platform(GCP):ビッグデータ処理や機械学習モデルのトレーニングに利用されます。
Microsoft Azure:AIサービスやデータ分析ツールを提供します。 - セキュリティ対策
データ暗号化:リンクデータの保存時や転送時に、情報を保護するために暗号化を施します。
アクセス制御:データベースやクラウドリソースへのアクセスを制限し、不正アクセスを防ぎます。
監視とログ管理:システムの動作を監視し、異常なアクセスや動作を検知するログを管理します。
上記のようなIT技術を駆使することで、被リンクの効果的な分析が可能となり、SEO対策の精度を高めます。
PythonとAIで被リンクの分析
PythonとAIで、被リンクを分析するコードを書いてみましょう。
以下は、Pythonを使って被リンクを分析するサンプルコードです。機械学習を用いてリンクの質を評価します。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
# Create sample backlink data
data = {
'Domain Authority': [45, 67, 89, 56, 34, 90, 23, 78, 80, 55],
'Link Count': [300, 500, 800, 450, 200, 900, 150, 650, 700, 400],
'Is Quality Link': [1, 1, 1, 1, 0, 1, 0, 1, 1, 0] # 1 means high quality, 0 means low quality
}
# Convert to DataFrame
df = pd.DataFrame(data)
# Display the first few rows of the DataFrame
print("Sample Backlink Data:")
print(df.head())
# Split the data into features and target variable
X = df[['Domain Authority', 'Link Count']]
y = df['Is Quality Link']
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Initialize and train the RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict the test set results
y_pred = model.predict(X_test)
# Evaluate the model
print("\nConfusion Matrix:")
print(confusion_matrix(y_test, y_pred))
print("\nClassification Report:")
print(classification_report(y_test, y_pred))
# Feature Importance
feature_importances = model.feature_importances_
features = X.columns
indices = np.argsort(feature_importances)
# Plot feature importances
plt.figure(figsize=(10, 5))
plt.title("Feature Importances")
plt.barh(range(len(indices)), feature_importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel("Relative Importance")
plt.show()Sample Backlink Data:
Domain Authority Link Count Is Quality Link
0 45 300 1
1 67 500 1
2 89 800 1
3 56 450 1
4 34 200 0
Confusion Matrix:
[[3]]
Classification Report:
precision recall f1-score support
1 1.00 1.00 1.00 3
accuracy 1.00 3
macro avg 1.00 1.00 1.00 3
weighted avg 1.00 1.00 1.00 3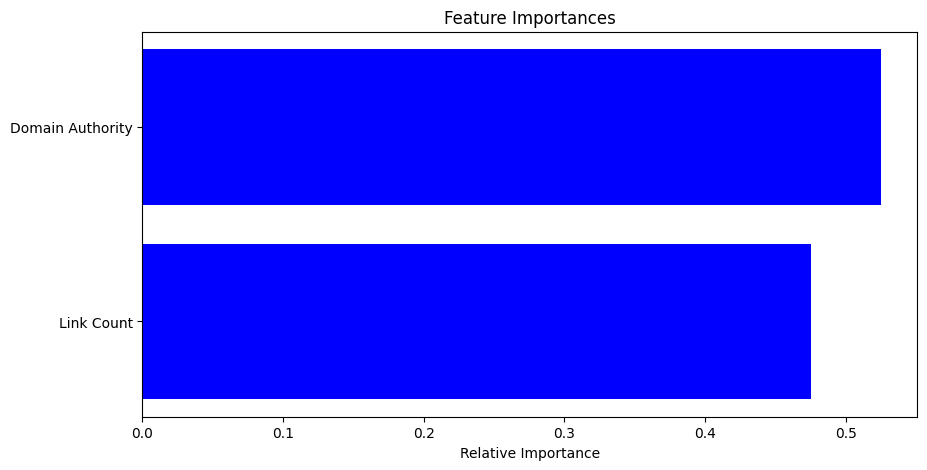
- データの作成:
サンプルデータを辞書形式で作成し、ドメインオーソリティ、リンク数、およびリンクの質(1が高品質、0が低品質)を含みます。pandasを使用してデータフレームに変換します。 - データの表示:
作成したサンプルデータの最初の数行を表示します。 - データの分割:
特徴量(ドメインオーソリティとリンク数)と目的変数(リンクの質)に分割します。
データセットをトレーニングセットとテストセットに分割します。 - モデルのトレーニング:
RandomForestClassifierを使用してモデルを初期化し、トレーニングデータでモデルを訓練します。 - 予測と評価:
テストセットを使用して予測を行います。
混同行列と分類レポートを表示してモデルの評価を行います。 - 特徴量の重要度:
特徴量の重要度を取得し、可視化します。
棒グラフで各特徴量の相対的な重要度を表示します。
AIで被リンクの分析:応用アイデア
AIで被リンクを分析する技術の、応用アイデアを考えてみましょう。
同業種への応用アイデア
- SEO最適化
サイトの被リンクを分析して、高品質なリンクを獲得する戦略を立てる。
被リンクデータをもとに、競合サイトとの比較分析を行う。 - コンテンツマーケティング
高品質なリンクを提供しているサイトを特定し、効果的なコンテンツ提携を行う。
人気のあるコンテンツやキーワードを特定し、それに基づいたコンテンツを作成。 - リンク監視
自社サイトへのリンクの質を定期的に監視し、スパムリンクを除去する。
新しいリンクの獲得状況をリアルタイムで追跡。
他業種への応用アイデア
- Eコマース
製品ページのリンク分析を通じて、マーケティングキャンペーンの効果を測定。
高品質なリンクを持つサイトと提携し、製品の認知度を向上。 - 不動産
不動産物件の紹介ページへのリンクを分析し、人気のある物件やエリアを特定。
物件紹介サイトとのリンク提携を強化し、集客を向上。 - 教育
教育機関のウェブサイトへのリンクを分析し、優れた教育コンテンツを提供しているサイトを特定。
教育リソースのリンクを通じて、学生や教員へのアクセスを増やす。 - ヘルスケア
医療情報サイトへのリンクを分析し、信頼性の高い医療情報を提供する。
健康関連のコンテンツを持つサイトと提携し、患者教育を強化。 - 観光
観光地や宿泊施設のページへのリンクを分析し、観光客の興味を引くエリアを特定。
観光ガイドやレビューサイトとのリンク提携を強化し、集客を向上。
AIで被リンクを分析する技術は、さまざまな分野に応用できそうですね。まさに、早い者勝ちのビジネスチャンスです。
AIで被リンクの分析:まとめ
AIを使った被リンクの分析について解説しました。
被リンク分析に使われる主なIT技術や、具体的なPythonコードの実装方法を紹介したので、AIエンジニアやプログラマーに転職を考えている方には参考になったと思います。
また、AIで被リンク分析する技術の応用アイデアも解説しました。
AIエンジニアやプログラマーに転職して、被リンク分析を活用し、SEO戦略を強化しましょう。
これからの時代、SEOでビジネスの成長を支えるのはAIエンジニアです。

▼AIを使った副業・起業アイデアを紹介♪