
「AIスポーツトレーナー」エージェントを、PythonとChatGPTで開発しましょう。AIを活用し、誰でもスポーツのトレーニング理論やトレーニング方法などに関する助言を得られるAIアプリの作り方を解説します。
AIスポーツトレーナーの主な特徴と機能
最新のAI技術を活用してAIスポーツトレーナーを開発し、スポーツトレーニング業界に革命を起こしましょう!ここでは、AIスポーツトレーナーの主な特徴と機能を解説します。
パーソナライズされたトレーニングプランの作成
AIスポーツトレーナーは、個々のアスリートのニーズに合わせたトレーニングプランを作成したり、適切なアドバイスなどを行います。AIスポーツトレーナーは、過去のパフォーマンスデータ、健康状態、そして個々の目標がインプットされます。Pythonで生成されたサンプルデータを用いて、AIスポーツトレーナーが情報を分析し、カスタマイズされたトレーニングプランを提案するかの例を紹介します。
下記のデモコードでは、異なるアスリートの基本的な属性(年齢、性別、スポーツの種類)とパフォーマンスデータ(走行距離、持久力、スプリント回数)を明示します。簡単なデータセットを作成し、分析して、個々のニーズに応じたトレーニングを提案します。
まず、サンプルデータを生成し、それを基に簡単な分析を行いましょう。このコードは、実際のAIスポーツトレーナー開発の際により複雑なデータとアルゴリズムに置き換えられることを想定しています。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# サンプルデータの生成
np.random.seed(0)
data = {
'Age': np.random.randint(18, 35, 20),
'Gender': np.random.choice(['Male', 'Female'], 20),
'Sport': np.random.choice(['Running', 'Cycling', 'Swimming'], 20),
'Distance_km': np.random.uniform(5, 40, 20),
'Endurance': np.random.uniform(30, 90, 20), # 持久力(分)
'Sprint_Count': np.random.randint(0, 15, 20) # スプリント回数
}
df = pd.DataFrame(data)
# サンプルデータの基本統計情報
basic_stats = df.describe()
# データの分布をグラフで表示
plt.figure(figsize=(12, 6))
sns.pairplot(df, hue='Sport')
plt.suptitle('Performance Data by Sport Type', y=1.02)
plt.show()
basic_stats, df.head() # 基本統計情報とデータの最初の5行を表示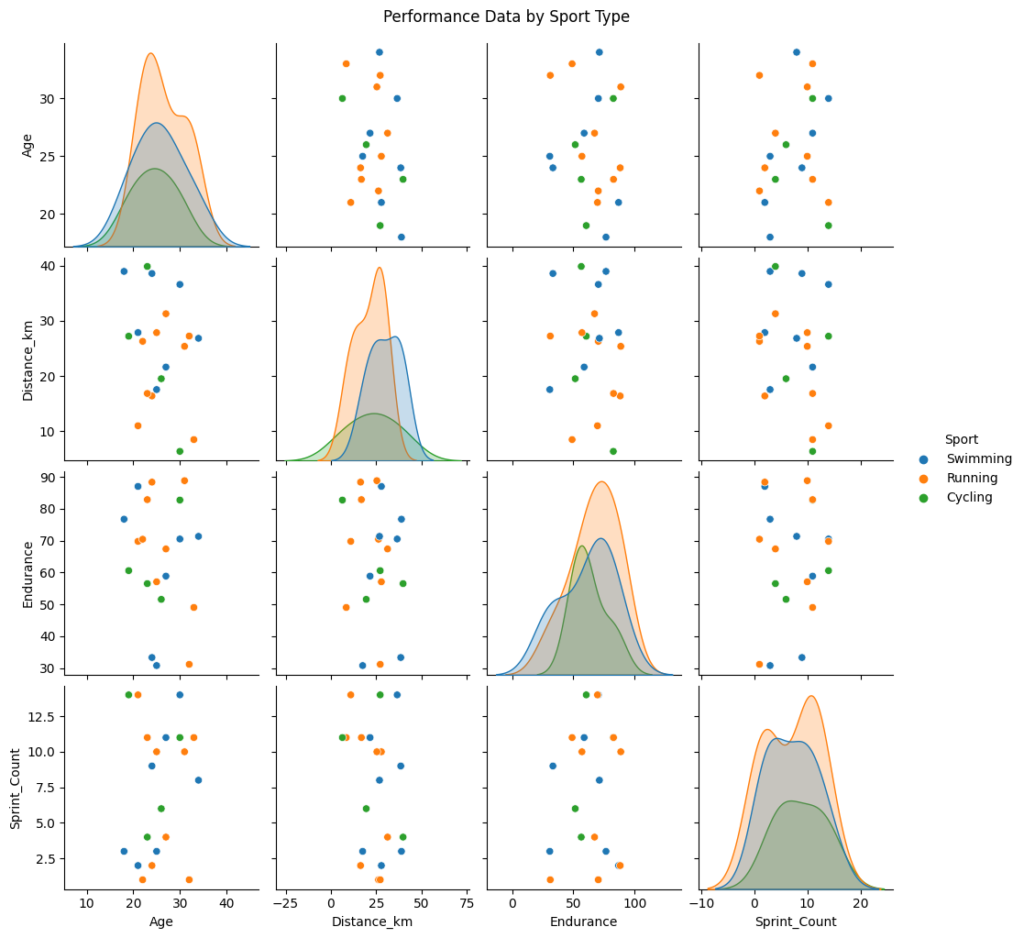
( Age Distance_km Endurance Sprint_Count
count 20.00000 20.000000 20.000000 20.000000
mean 25.75000 24.572762 64.229616 7.450000
std 4.66651 9.882484 18.376855 4.605203
min 18.00000 6.344890 30.814298 1.000000
25% 22.75000 17.359061 55.268658 3.000000
50% 25.00000 26.548463 68.561189 8.500000
75% 30.00000 28.713430 78.198449 11.000000
max 34.00000 39.835485 88.775204 14.000000,
Age Gender Sport Distance_km Endurance Sprint_Count
0 30 Male Swimming 36.582200 70.485139 14
1 33 Female Running 8.474812 49.032105 11
2 18 Female Swimming 38.943317 76.700729 3
3 21 Male Swimming 27.859901 86.974263 2
4 21 Male Running 10.981835 69.751612 14)このコードでは、20人のアスリートのサンプルデータを生成しました。データには年齢、性別、スポーツの種類(走り、自転車、水泳)、走行距離、持久力、スプリント回数などの情報が含まれています。次に、データの基本統計情報を表示し、スポーツの種類によって異なるパフォーマンス指標の分布をグラフで視覚化しました。
このサンプルデータと分析は、個々のアスリートの特性とパフォーマンスを理解し、それに基づいてパーソナライズされたトレーニングプランを作成するための基盤となります。実際のAIスポーツトレーナー開発では、より複雑なデータセットと高度な分析手法が用いられます。
パフォーマンス分析とフィードバック
AIスポーツトレーナーは、アスリートのパフォーマンスをリアルタイムで分析し、適時フィードバックを提供できます。AIスポーツトレーナーにより、アスリートはトレーニングの質を向上させ、効率的に目標に近づくことができます。
以下の例では、ランダムな値を生成してトレーニングセッションのデータを模擬します。このデータには、距離、時間、心拍数、日付などの情報が含まれています。
サンプルデータの生成
- 距離(キロメートル)
- 時間(分)
- 心拍数(拍/分)
- 日付(年月日)
分析の手順
- サンプルデータの生成
- 基本統計の計算
- 心拍数の傾向分析
- 分析結果の表示
サンプルコード
import pandas as pd
import numpy as np
from datetime import timedelta, datetime
# サンプルデータの生成
np.random.seed(0) # 乱数の再現性のため
num_sessions = 50 # セッション数
dates = pd.date_range(start="2023-01-01", periods=num_sessions, freq='D')
distances = np.random.uniform(5, 15, num_sessions) # 5kmから15kmの間でランダム
times = np.random.uniform(30, 120, num_sessions) # 30分から120分の間でランダム
heart_rates = np.random.randint(60, 180, num_sessions) # 60から180拍/分の間でランダム
# DataFrameの作成
data = pd.DataFrame({
'date': dates,
'distance': distances,
'time': times,
'heart_rate': heart_rates
})
# 基本統計の計算
mean_distance = data['distance'].mean()
max_heart_rate = data['heart_rate'].max()
min_heart_rate = data['heart_rate'].min()
standard_deviation_time = data['time'].std()
# パフォーマンスの傾向分析
heart_rate_trend = data.groupby(data['date'].dt.to_period('M'))['heart_rate'].mean()
# 結果の表示
print("平均距離:", mean_distance)
print("最大心拍数:", max_heart_rate)
print("最小心拍数:", min_heart_rate)
print("トレーニング時間の標準偏差:", standard_deviation_time)
print("月ごとの心拍数の傾向:\n", heart_rate_trend)平均距離: 10.37965118275541
最大心拍数: 178
最小心拍数: 62
トレーニング時間の標準偏差: 26.288434012112504
月ごとの心拍数の傾向:
date
2023-01 119.709677
2023-02 125.421053
Freq: M, Name: heart_rate, dtype: float64このコードは、ランダムに生成されたトレーニングデータに基づいて基本的な分析を行います。実際のアプリケーションでは、実際のトレーニングデータを用いてより詳細に分析します。
怪我のリスク管理と予防
AIスポーツトレーナーは、運動のパターンや身体の反応を分析し、怪我のリスクを評価します。AIスポーツトレーナーによって、アスリートは怪我のリスクを最小限に抑えながらトレーニングできます。Pythonを使用して、怪我のリスク評価の例を紹介します。
怪我のリスクを評価するためのPythonコードサンプルを作成します。このコードでは、アスリートのトレーニングデータ(例えば、トレーニング強度、持続時間、回復時間など)を分析して、怪我のリスクを推定します。実際には、より複雑なデータと分析が必要ですが、ここでは基本的な手順を紹介します。
以下のコードでは、サンプルデータを作成し、それを用いて怪我のリスクを評価する基本的なロジックです。この例では、トレーニングの過剰な強度や不十分な回復が怪我のリスクを高めると仮定します。
# 怪我のリスク評価のためのサンプルデータと分析コード
# サンプルデータ生成
# トレーニング強度、持続時間、回復時間
data_injury_risk = {
'Training_Intensity': np.random.uniform(1, 10, 20), # トレーニング強度 (1-10)
'Duration_hours': np.random.uniform(1, 5, 20), # 持続時間 (時間)
'Recovery_hours': np.random.uniform(0, 48, 20) # 回復時間 (時間)
}
df_injury_risk = pd.DataFrame(data_injury_risk)
# 怪我のリスクを計算する関数
def calculate_injury_risk(row):
# 高いトレーニング強度と長い持続時間は怪我のリスクを増加させる
risk_score = (row['Training_Intensity'] * row['Duration_hours']) / row['Recovery_hours']
# リスクスコアに基づいて、低リスク、中リスク、高リスクを分類
if risk_score < 2:
return 'Low Risk'
elif 2 <= risk_score < 5:
return 'Medium Risk'
else:
return 'High Risk'
# 各アスリートの怪我のリスクを計算
df_injury_risk['Injury_Risk'] = df_injury_risk.apply(calculate_injury_risk, axis=1)
df_injury_risk.head() # サンプルデータと怪我のリスクを表示
Training_Intensity Duration_hours Recovery_hours Injury_Risk
0 3.610698 4.995388 8.238225 Medium Risk
1 6.562139 1.597793 25.009757 Low Risk
2 4.858918 4.472504 2.608223 High Risk
3 2.219267 1.649972 9.599833 Low Risk
4 3.684541 3.462238 0.889046 High Riskこのコードでは、まずトレーニング強度、持続時間、回復時間という3つの指標を持つサンプルデータを生成しました。その後、これらのデータを基にして怪我のリスクを計算する関数を定義しています。この関数では、トレーニング強度と持続時間を乗算し、それを回復時間で割ることでリスクスコアを計算します。そして、そのスコアに基づいて怪我のリスクを「低リスク」「中リスク」「高リスク」のいずれかに分類しています。
このような分析は、アスリートがトレーニングプログラムを適切に調整し、怪我のリスクを最小限に抑えます。実際のAIスポーツトレーナーアプリでは、より詳細なデータと分析手法が使用されます。
統合された健康管理
AIスポーツトレーナーは、アスリートの健康管理もサポートします。栄養、睡眠、ストレスレベルなど、パフォーマンスに影響を与えるさまざまな要因を分析します。
健康管理に関連するデータ分析のためのPythonコード例を紹介します。この例では、アスリートの睡眠時間、栄養摂取(例えばカロリー摂取量)、ストレスレベルなどのデータを分析し、アスリートの全体的な健康状態を評価します。
以下のコードでは、それぞれの指標を含むサンプルデータを生成し、健康状態に関連する統計情報と視覚化を行います。これは、アスリートが健康的なライフスタイルを維持し、トレーニングの効果を最大限に引き出すのに役立ちます。
# 健康管理に関するデータ分析のサンプルコード
# サンプルデータ生成
# 睡眠時間、カロリー摂取量、ストレスレベル
data_health = {
'Sleep_Hours': np.random.uniform(5, 9, 20), # 睡眠時間 (時間)
'Calorie_Intake': np.random.uniform(1500, 3000, 20), # カロリー摂取量
'Stress_Level': np.random.uniform(1, 10, 20) # ストレスレベル (1-10)
}
df_health = pd.DataFrame(data_health)
# 健康データの基本統計情報
health_stats = df_health.describe()
# データの分布をグラフで表示
plt.figure(figsize=(12, 6))
sns.pairplot(df_health)
plt.suptitle('Health Data Analysis', y=1.02)
plt.show()
health_stats, df_health.head() # 基本統計情報とデータの最初の5行を表示
( Sleep_Hours Calorie_Intake Stress_Level
count 20.000000 20.000000 20.000000
mean 6.516379 2362.064969 4.471115
std 0.990774 464.822022 2.093718
min 5.098715 1530.976499 1.230964
25% 5.815724 1906.480680 2.812803
50% 6.379394 2469.045035 4.466034
75% 7.007956 2762.173508 5.770053
max 8.777490 2985.508421 8.774700,
Sleep_Hours Calorie_Intake Stress_Level
0 6.247780 2845.006940 7.577702
1 6.592884 2985.508421 3.285475
2 5.839375 1825.345477 2.919808
3 5.744772 2494.617305 5.663806
4 8.777490 1894.983565 1.230964)まず睡眠時間、カロリー摂取量、ストレスレベルという3つの健康指標を持つサンプルデータを生成しました。その後、データの基本統計情報を表示し、ペアプロットを用いて各指標間の関係を視覚化しています。
健康管理の分析は、アスリートが十分な休息を取っているか、適切な栄養を摂取しているか、ストレスレベルが適切に管理されているかなどを理解するのに役立ちます。健康管理はアスリートのパフォーマンスに重要であり、データ分析はトレーニングと健康管理のバランスを取るのに役立ちます。実際のアプリケーションでは、より詳細なデータと分析が必要です。
グラフと表によるデータの視覚化
AIスポーツトレーナーは、データの視覚化にも優れています。アスリートは自身の進捗を直感的に理解し、トレーニングを調整できます。
以下のコードは、先ほど作成した健康管理データ(睡眠時間、カロリー摂取量、ストレスレベル)をさらに詳細に視覚化します。ここでは、ヒートマップとヒストグラムを使用して、データの分布と相関を示します。アスリートやトレーナーは、異なる健康指標がどのように関連しているかをより深く理解できます。
# データ視覚化のためのサンプルコード
# 相関行列の計算
correlation_matrix = df_health.corr()
# ヒートマップで相関を表示
plt.figure(figsize=(8, 6))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('Correlation Matrix of Health Data')
plt.show()
# ヒストグラムで各指標の分布を表示
df_health.hist(bins=15, figsize=(12, 6), layout=(1, 3))
plt.suptitle('Histograms of Health Indicators')
plt.show()
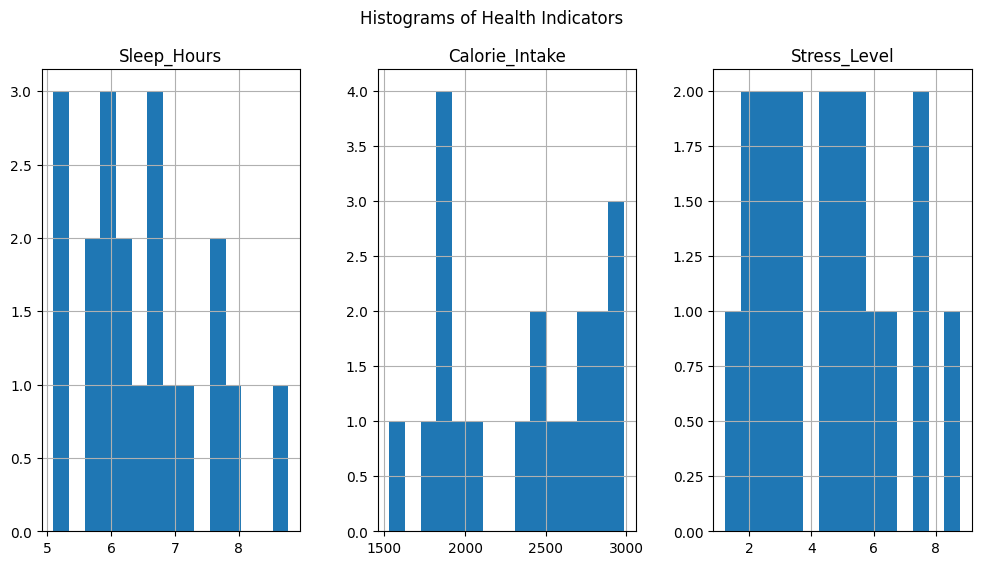
まず健康管理データの相関行列を計算し、ヒートマップを用いてその相関関係を視覚化します。ヒートマップは、睡眠時間、カロリー摂取量、ストレスレベルといった健康指標の間の関連性を示しています。色が暖かいほど相関が強いことを意味します。
次に、各健康指標の分布をヒストグラムで表示します。アスリートやトレーナーは、これらの健康指標がどのように分布しているかを一目で確認できます。
AIスポーツトレーナーの開発プロセス
AIスポーツトレーナーの開発プロセスについて解説します。ここでは、開発の初期段階から、必要な技術の選定に至るまでのプロセスを紹介します。
AIスポーツトレーナー開発の計画と設計
開発の計画と設計段階では、AIスポーツトレーナーの目的、対象ユーザー、主機能などが定義されます。この段階で、AIスポーツトレーナーの範囲と期待される成果を明確にしましょう。また、AIスポーツトレーナー開発のタイムラインとリソース割り当てもこの段階で行われます。
AIスポーツトレーナー開発プロジェクトの主なフェーズと、それに割り当てられるリソース(人員や時間)を示すシンプルな表を作成しましょう。
以下の表は、AIスポーツトレーナー開発の進行状況を追跡し、必要なリソースを効果的に割り当てるために利用されます。以下のコードでは、プロジェクトの各フェーズとその期間、関与するチームメンバーの数を表現します。
# 開発計画のサンプルタイムラインとリソース割り当ての表生成
# サンプルデータ
project_phases = ['Requirement Analysis', 'Design', 'Development', 'Testing', 'Deployment', 'Maintenance']
duration_weeks = [4, 6, 12, 8, 4, 12] # 各フェーズの期間(週)
team_members = [3, 5, 10, 6, 4, 2] # 各フェーズに割り当てられるチームメンバーの数
# データフレームの作成
df_timeline = pd.DataFrame({
'Phase': project_phases,
'Duration (Weeks)': duration_weeks,
'Team Members': team_members
})
df_timeline # タイムラインとリソース割り当ての表を表示
Phase Duration (Weeks) Team Members
0 Requirement Analysis 4 3
1 Design 6 5
2 Development 12 10
3 Testing 8 6
4 Deployment 4 4
5 Maintenance 12 2この表には、AIスポーツトレーナー開発プロジェクトの主なフェーズが示されています。それぞれのフェーズには、必要な期間(週単位)とそのフェーズに割り当てられるチームメンバーの数が記載されています。たとえば、「Requirement Analysis」フェーズは4週間で3人のチームメンバーが必要、「Development」フェーズは12週間で10人のチームメンバーが必要です。
AIスポーツトレーナー開発の管理表は、効果的なプロジェクト管理に役立ちます。実際のプロジェクトでは、これらの数値はプロジェクトの規模や複雑さに応じて調整されます。
必要な技術とツールの選定
AIスポーツトレーナーの開発には、データ収集・処理、機械学習モデルの開発、フロントエンドとバックエンドの実装など、多様な技術とツールが必要です。ここでは、各技術とツールの選定基準と重要性について説明します。
以下の表では、AIスポーツトレーナー開発のさまざまな技術とツール(例えば、データ処理、機械学習、フロントエンド開発など)の選定基準を示します。
開発チームが適切な技術とツールを選択する際の指針となり、AIスポーツトレーナー開発に不可欠です。基準には、性能、拡張性、コスト、ユーザーインターフェイスの品質、サポートやコミュニティの活動などが含まれることがあります。以下のコードでは、これらの基準を含むサンプル表を生成します。
# 技術とツールの選定に関する基準の表生成
# サンプルデータ
tech_tools = ['Data Processing', 'Machine Learning', 'Frontend Development', 'Backend Development', 'Database Management']
criteria = ['Performance', 'Scalability', 'Cost', 'Ease of Use', 'Community Support']
# ランダムな評価値を生成(1から5のスケール)
evaluation_values = np.random.randint(1, 6, (len(tech_tools), len(criteria)))
# データフレームの作成
df_tool_selection = pd.DataFrame(evaluation_values, columns=criteria, index=tech_tools)
df_tool_selection # 技術とツールの選定基準の表を表示
Performance Scalability Cost Ease of Use Community Support
Data Processing 3 4 5 5 3
Machine Learning 2 3 1 4 1
Frontend Development 3 5 4 3 2
Backend Development 3 2 5 2 1
Database Management 1 1 1 1 2この表には、AIスポーツトレーナー開発において考慮すべき技術とツール(データ処理、機械学習、フロントエンド開発、バックエンド開発、データベース管理)が列挙されています。各技術・ツールに対して「パフォーマンス」「拡張性」「コスト」「使いやすさ」「コミュニティサポート」という5つの基準に基づいた評価が行われています。
技術とツールの選定基準表は、AIスポーツトレーナー開発チームが適切な技術を選定する際に重要な情報を提供します。たとえば、高いパフォーマンスとコミュニティサポートを重視する場合、それに応じた技術やツールを選択できます。実際のプロジェクトでは、これらの評価は特定のニーズや目標に基づいてさらに細かく調整されます。
AIスポーツトレーナーをPythonで開発
Python環境をセットアップしましょう。通常、Pythonの開発環境をセットアップする際には、Pythonのインストール、関連ライブラリのインストール、および開発用のIDE(統合開発環境)を設定します。実際のセットアップは、使用するオペレーティングシステムや個々のニーズによって異なる場合があります。
Pythonのインストール
- Pythonの公式ウェブサイト(https://www.python.org/)から最新バージョンのPythonをダウンロードします。
- ダウンロードしたインストーラーを実行し、指示に従ってPythonをインストールします。
必要なライブラリのインストール
Pythonのプロジェクトでは通常、特定のライブラリが必要です。これらはpipコマンドを使用してインストールできます。例えば、データ分析にはpandasやnumpy、データ視覚化にはmatplotlibやseabornがよく使用されます。
pip install pandas numpy matplotlib seaborn開発環境のセットアップ
Pythonの開発には、Visual Studio Code、PyCharm、Jupyter NotebookなどのIDEがよく使用されます。これらはそれぞれの公式ウェブサイトからダウンロードしてインストールできます。
Visual Studio Code: https://code.visualstudio.com/
PyCharm: https://www.jetbrains.com/pycharm/
Jupyter Notebook: Jupyterはpipを使用してインストールできます。
pip install notebookこれらのステップにより、Python開発の基本的な環境が整います。AIスポーツトレーナー開発の具体的な要件に応じて、追加のツールやライブラリが必要になる場合があります。
Pythonによる基本的なコーディング
Pythonを使用した基本的なコーディングには、データ構造の操作、関数の定義、クラスの作成などが含まれます。これらは、より複雑なAI機能を実装するために必要です。
# リストと辞書の操作
# リストの作成と操作
numbers = [1, 2, 3, 4, 5]
squared_numbers = [x ** 2 for x in numbers] # リスト内包表記を使用して各要素を二乗
# 辞書の作成と操作
athlete_performance = {"name": "John Doe", "age": 30, "sport": "Running"}
athlete_performance["performance"] = 95 # 辞書への新しいキーと値の追加
# 基本的な関数の定義と使用
# 与えられたリストの平均値を計算する関数
def calculate_average(values):
return sum(values) / len(values)
average_score = calculate_average(squared_numbers) # 平均値の計算
# 結果の表示
print("Squared Numbers:", squared_numbers)
print("Athlete Performance:", athlete_performance)
print("Average Score:", average_score)Squared Numbers: [1, 4, 9, 16, 25]
Athlete Performance: {'name': 'John Doe', 'age': 30, 'sport': 'Running', 'performance': 95}
Average Score: 11.0このコードでは、まずリスト内包表記を使ってリストの各要素を二乗し、次に辞書に新しいキーと値を追加します。また、簡単な関数を定義してリストの平均値を計算し、その結果を表示しています。
これらの基本的な概念は、Pythonでのデータ操作の基礎です。実際のアプリケーションでは、Pythonの技術を組み合わせて、より複雑なデータ構造の操作やアルゴリズムの実装が行われます。
ChatGPTを活用した機能の統合
ChatGPT APIの活用方法
ChatGPT APIを活用することで、AIスポーツトレーナーアプリはユーザーの質問や疑問に対してリアルタイムで応答する能力を持ちます。ChatGPT APIにより、トレーニングプログラムの個別化やトレーニングに関するアドバイスを提供できます。
- ChatGPT APIへのアクセス: まず、OpenAIの公式サイトでChatGPT APIへのアクセス権を取得します。アクセスキーが必要になるので、APIキーを安全に管理することが重要です。
- APIリクエストの構築: Pythonを使用してAPIリクエストを構築します。これには、ユーザーからの入力を受け取り、それをChatGPT APIに送信するコードが含まれます。
- 応答の処理: APIからの応答を適切に処理し、ユーザーにわかりやすい形で表示します。これには、テキストの整形や、必要に応じて追加の情報を提供することが含まれます。
- 連続的な対話の管理: トレーニングのアドバイスを提供するためには、連続的な対話の管理が重要です。ユーザーの進捗や過去の質問に基づいて、カスタマイズされたアドバイスを提供できます。
対話型エージェントの実装
対話型エージェントは、個別化されたトレーニング計画やフィードバックを提供します。Pythonを使用してAIスポーツトレーナーエージェントを実装する際には、以下のステップで進めます。
- ユーザーインタフェースの作成: 対話型エージェントのためのユーザーインタフェースを作成します。テキスト入力やボタンなどが含まれ、ユーザーが質問やフィードバックを簡単に提供できるようにします。
- 対話管理のロジック: ユーザーからの入力に基づいて適切な応答を生成するロジックを開発します。このロジックは、ユーザーの質問の意図を理解し、関連する情報やアドバイスを提供します。
- パーソナライゼーション: ユーザーの過去のデータや好みに基づいて、対話をパーソナライズします。例えば、過去のトレーニング記録に基づいてアドバイスをカスタマイズできます。
- 対話の継続性の維持: ユーザーとの対話を通じて継続性を保ちます。これには、過去の会話のコンテキストを維持し、ユーザーの進捗に応じてアドバイスを更新することなどが含まれます。
Pythonのコードサンプルやコマンド、表やグラフの表示などを紹介します。
事前準備
- OpenAI APIキーの取得: OpenAIのWebサイトでAPIキーを取得します。
- 適切なライブラリのインストール:
requestsライブラリが必要です。これはpip install requestsでインストールできます。
Pythonコードサンプル
以下のコードは、ユーザーからの入力を受け取り、それをChatGPT APIに送信し、応答を処理する例です。
import requests
def send_to_chatgpt(prompt, api_key):
headers = {
"Authorization": f"Bearer {api_key}"
}
data = {
"model": "gpt-3.5-turbo", # または使用したいモデルを指定
"prompt": prompt,
"max_tokens": 150 # 応答の最大長
}
response = requests.post("https://api.openai.com/v1/engines/gpt-3.5-turbo/completions", headers=headers, json=data)
return response.json()
# 例: APIキーとユーザーの質問
api_key = "YOUR_API_KEY_HERE" # ここにあなたのAPIキーを設定
user_input = "どのようにしてマラソンのタイムを改善できますか?"
# APIへのリクエスト送信
response = send_to_chatgpt(user_input, api_key)
# 応答の表示
print(response["choices"][0]["text"])このコードは、基本的なAPIリクエストと応答の処理を示しています。実際のアプリケーションでは、これをユーザーインタフェースと統合し、継続的な対話を管理するロジックを実装します。
対話型エージェントの実装
対話型エージェントを実装する際には、以下の点を考慮します。
- ユーザーインタフェース: ウェブアプリケーションやモバイルアプリでユーザーの入力を受け取る。
- 対話管理: ユーザーの入力に基づいて適切なAPIリクエストを構築し、応答を処理する。
- パーソナライゼーション: ユーザーの過去のトレーニングデータや好みに基づいて対話をカスタマイズする。
- 継続的な対話: 会話のコンテキストを維持し、ユーザーの進捗に応じたアドバイスを提供する。
AIスポーツトレーナーのデプロイ方法
デプロイメントは、開発されたAIスポーツトレーナーを実際のユーザーが利用できる状態にするプロセスです。デプロイメントは、アプリケーションのアクセシビリティ、パフォーマンス、スケーラビリティを確保するために不可欠です。以下では、デプロイメントの主なステップについて説明します。
デプロイメント環境の選定
デプロイメントの最初のステップは、適切な環境を選定することです。一般的な選択肢には、クラウドベースのプラットフォーム(例:AWS, Google Cloud, Azure)、専用サーバー、またはPaaS(プラットフォーム・アズ・ア・サービス)ソリューションがあります。各環境の特性を検討し、コスト、パフォーマンス、拡張性の要件に基づいて選択します。
アプリケーションのコンテナ化
アプリケーションをコンテナ化することで、さまざまな環境での一貫性とポータビリティが保証されます。Dockerは、アプリケーションをコンテナ化する人気ツールです。以下は、PythonアプリケーションをDockerコンテナにパッケージングする基本的な手順です。
- Dockerfileの作成: アプリケーションの依存関係と実行コマンドを定義するDockerfileを作成します。
- イメージのビルド: DockerfileからDockerイメージをビルドします。
- コンテナの起動: ビルドされたイメージからコンテナを起動し、ローカルでテストします。
コンテナオーケストレーション
大規模なデプロイメントや複数のコンテナを管理する場合、オーケストレーションツール(例:Kubernetes)の使用が推奨されます。オーケストレーションツールにより、コンテナのスケーリング、ロードバランシング、自己修復などが自動化されます。
継続的インテグレーション/デプロイメント (CI/CD)
CI/CDパイプラインを設定することで、アプリケーションのアップデートを効率的にデプロイできます。これは、コード変更が自動的にテストされ、本番環境に安全にデプロイされるプロセスです。
監視とメンテナンス
デプロイメント後は、アプリケーションのパフォーマンスを監視し、必要に応じてメンテナンスを行います。ログ収集、エラートラッキング、リソース使用状況の監視などが含まれます。
Pythonによるデプロイメントのサンプル
以下では、Pythonで記述されたAIスポーツトレーナーのサンプルデプロイメントスクリプトです。このスクリプトは、Dockerを使用してアプリケーションをコンテナ化し、基本的なテストを行います。
# Dockerfileのサンプル
# 使用するPythonイメージを指定
FROM python:3.8
# 作業ディレクトリを設定
WORKDIR /app
# 必要なパッケージをインストール
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
# アプリケーションのコードをコピー
COPY . .
# アプリケーションの起動コマンドを指定
CMD ["python", "./your_app.py"]このDockerfileは、Python 3.8をベースにしており、必要な依存関係をインストールし、アプリケーションのコードをコピーした後、アプリケーションを起動します。
AIスポーツトレーナーの実践的な活用
スポーツトレーニングと健康管理における、AIの新しい活用方法を紹介します。ここでは、実際のシナリオでのAIスポーツトレーナーの活用方法と、Pythonを用いたデータ分析の例を解説します。
パーソナライズされたトレーニングプランの提供
AIスポーツトレーナーは、ユーザーの身体的特徴、健康状態、トレーニング目標に基づいてパーソナライズされたトレーニングプランを提供します。これには、運動の種類、強度、頻度の推奨が含まれます。
パフォーマンスデータの分析
トレーニング中のパフォーマンスデータを収集し分析することで、トレーニングの効果を評価し、改善のための具体的な提案を行います。以下は、パフォーマンスデータを分析するためのPythonコードの例です。
import pandas as pd
import matplotlib.pyplot as plt
# サンプルデータの生成
data = {
'Date': pd.date_range(start='2023-01-01', periods=30, freq='D'),
'Distance': np.random.uniform(5, 10, 30), # 走行距離 (km)
'HeartRate': np.random.randint(60, 180, 30) # 心拍数 (bpm)
}
df = pd.DataFrame(data)
# データの可視化
plt.figure(figsize=(10, 5))
plt.plot(df['Date'], df['Distance'], label='Distance (km)')
plt.plot(df['Date'], df['HeartRate'], label='Heart Rate (bpm)', linestyle='--')
plt.xlabel('Date')
plt.ylabel('Value')
plt.title('Training Performance Over Time')
plt.legend()
plt.show()
このコードは、ランニングの距離と心拍数のデータを日付ごとにプロットし、トレーニングのパフォーマンスを視覚化します。
健康とウェルネスのアドバイス
AIスポーツトレーナーは、トレーニングのアドバイスに加えて、栄養摂取、睡眠の質、ストレス管理など、全般的な健康とウェルネスに関するアドバイスも提供します。
リアルタイムのフィードバックとサポート
AIスポーツトレーナーは、リアルタイムでユーザーにフィードバックを提供し、トレーニング中のフォームの改善や安全な運動方法に関するサポートを行います。
進捗の追跡とモチベーションの向上
AIスポーツトレーナーは、達成感や成功体験を通じてユーザーをサポートします。ユーザーのトレーニング進捗を追跡し、目標達成に向けてモチベーションを維持するための戦略を提供します。
AIスポーツトレーナーは、ユーザーに対してより質の高いトレーニング体験を提供します。AIスポーツトレーナーは、個々のニーズに応じたカスタマイズされたトレーニング法を提供し、健康で活動的な生活スタイルを実現します。
まとめと今後の展望
PythonとChatGPTを使用して、AIスポーツトレーナーを開発する方法について説明しました。開発の各段階での重要な事項と、実践的なコーディングの例を紹介しました。
AIスポーツトレーナー 開発の振り返り
- 特徴と機能: AIスポーツトレーナーは、個々のユーザーのニーズに合わせてパーソナライズされたトレーニングアドバイスを提供します。これには、運動計画、パフォーマンス分析、健康アドバイスが含まれます。
- 開発プロセス: 開発プロセスでは、計画と設計の段階から、Pythonによる基本的なコーディング、ChatGPTの統合、デプロイメント方法に至るまで、慎重な検討が必要でした。
- 技術の選定: Pythonの柔軟性と豊富なライブラリ、ChatGPTの高度な自然言語処理能力が、AIスポーツトレーナー開発に不可欠でした。
- 実践的な活用: リアルタイムのフィードバック、進捗追跡、健康管理のアドバイスなど、多面的で活用できます。
AIエージェントの今後の可能性
AIスポーツトレーナーの、今後の可能性を考えてみましょう。
- 拡張されたカスタマイズ: AI技術の進歩により、より高度なパーソナライズが可能になります。ユーザーの生物学的データ、行動パターン、好みに基づいて、トレーニングをさらに個別化できます。
- ウェアラブルデバイスとの統合: ウェアラブルデバイスからのリアルタイムデータを活用して、トレーニングの効果を最大化し、健康リスクを最小限に抑えることができます。
- 仮想現実 (VR) と拡張現実 (AR) の活用: VRやAR技術を活用することで、ユーザーに没入型のトレーニング体験を提供できます。
- 予防医療への応用: AIスポーツトレーナーは、運動を通じて健康状態を改善し、慢性疾患の予防に役立ちます。
- グローバルなアクセシビリティ: オンラインとモバイルのプラットフォームによって、より多くの人々が専門的なトレーニングアドバイスを受けることができます。
AIスポーツトレーナーは、AIスポーツトレーナーがより多くの人々の健康とフィットネスに貢献し、より健康的な生活をサポートします。
全ての人が、人工知能の進化によって、スポーツのトレーニング方法などに関する優れたアドバイスを得られる時代です。「AIスポーツトレーナー」エージェントは、スポーツトレーナー業界の新たな標準となるでしょう。

▼AIを使った副業・起業アイデアを紹介♪

