
AIエンジニアやプログラマーに転職して、AIで人工コーヒーを開発しましょう。
最近の技術進歩によると、人工コーヒーは環境負荷を大幅に軽減し、安定した供給を実現できるとされています。
AIで人工コーヒーの開発に使用されるIT技術や具体的なPythonコードも解説しますので、AIエンジニアやプログラマーに転職したい方には必読の内容です。
また、この技術を応用したビジネスや他業種でのアイデアも紹介しますので、新しい視点や発想を得られますよ。
AIで人工コーヒーを開発

科学技術がもたらす新しい生活様式として、人工コーヒーの開発が進んでいるそうです。
現在、世界中で毎日20億杯のコーヒーが消費されていますが、その生産には大規模な森林伐採が伴い、農家は低賃金で働き、多くの二酸化炭素が排出されています。
特に気候変動の影響で、2050年までにはコーヒー栽培に適した土地の約半分が使えなくなるそうです。
こうした問題に対処するため、環境負荷の少ない人工コーヒーが注目されています。
人工コーヒーは、今後のコーヒー需要を満たしつつ、環境や社会への負担を軽減する可能性があるということです。
AIで人工コーヒーの開発:利用されるIT技術
本物のコーヒーは環境破壊を伴うので、人工コーヒーが注目されていると言うことですね。
おいしくて安い人工コーヒーを飲める日は近いようです。自分の好みに合ったコーヒーをAIがブレンドしてくれるサービスは既にあります。
AIで人工コーヒーを開発するために使用される主なIT技術は、下記のとおりです。
- プログラム言語:
Python:データ分析や機械学習のための主言語。
R:統計解析やデータビジュアライゼーションに使われる。 - AI技術:
機械学習:コーヒーの成分分析と味の予測に使用される。
自然言語処理 (NLP):消費者のフィードバック分析に役立つ。
コンピュータビジョン:コーヒー豆の品質検査や分類に使用される。 - データベース技術:
SQLデータベース:データの管理とクエリのために使用。
NoSQLデータベース (例: MongoDB):柔軟なデータ構造を扱うために利用。 - クラウド技術:
Amazon Web Services (AWS):データストレージと計算リソースの提供。
Google Cloud Platform (GCP):機械学習モデルのトレーニングとデプロイメントに使用。
Microsoft Azure:AIサービスとデータ分析ツールの統合。 - セキュリティ対策:
データ暗号化:データの安全な保管と転送を保証する。
認証とアクセス制御:システムへのアクセスを制限し、不正使用を防止。
セキュリティ監査:システムの脆弱性を定期的にチェックし、改善する。
PythonとAIで人工コーヒーを開発
PythonとAIで、人工コーヒーを開発するコードを書いてみましょう。
以下のPythonコードは、人工コーヒーの成分をAIと機械学習で分析します。
コーヒーの成分データを生成し、それを使って機械学習モデルをトレーニングし、コーヒーの品質を予測します。
- データ生成:サンプルデータを生成し、データフレームに格納します。
- データの前処理:データの正規化とトレーニングセットとテストセットの分割を行います。
- モデルのトレーニング:ランダムフォレストを使ってモデルをトレーニングします。
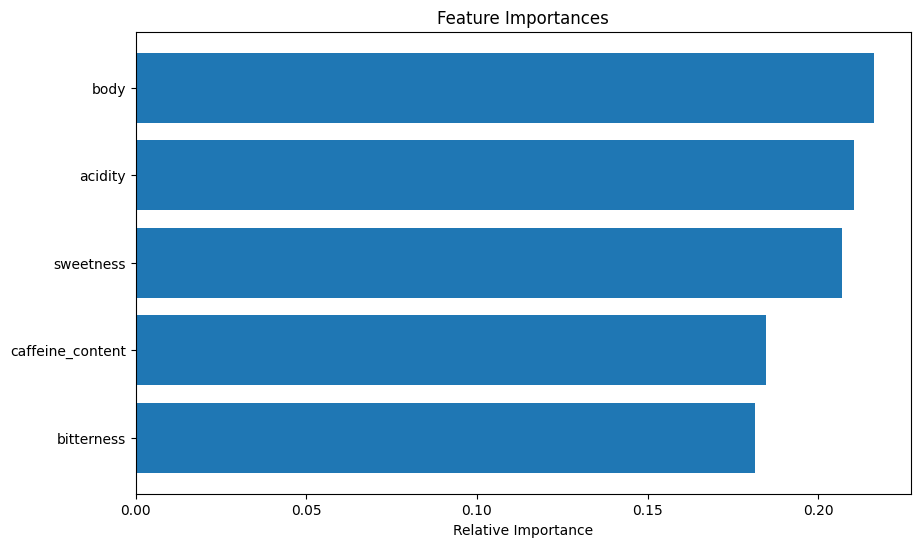
- モデルの評価:精度、混同行列、特徴量の重要度を評価し、結果をプロットします。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# Generate sample data
np.random.seed(0)
data_size = 200
features = {
'caffeine_content': np.random.normal(100, 10, data_size),
'acidity': np.random.normal(5, 1, data_size),
'bitterness': np.random.normal(3, 0.5, data_size),
'sweetness': np.random.normal(4, 1, data_size),
'body': np.random.normal(7, 1.5, data_size),
'quality': np.random.choice([0, 1], data_size) # 0: Low quality, 1: High quality
}
df = pd.DataFrame(features)
# Split data into features and target
X = df.drop('quality', axis=1)
y = df['quality']
# Split data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the data
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Train a Random Forest model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict the test set
y_pred = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
# Plot confusion matrix
plt.figure(figsize=(6, 4))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=['Low Quality', 'High Quality'], yticklabels=['Low Quality', 'High Quality'])
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
# Plot feature importance
feature_importances = model.feature_importances_
features = X.columns
indices = np.argsort(feature_importances)
plt.figure(figsize=(10, 6))
plt.title('Feature Importances')
plt.barh(range(len(indices)), feature_importances[indices], align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()Accuracy: 0.28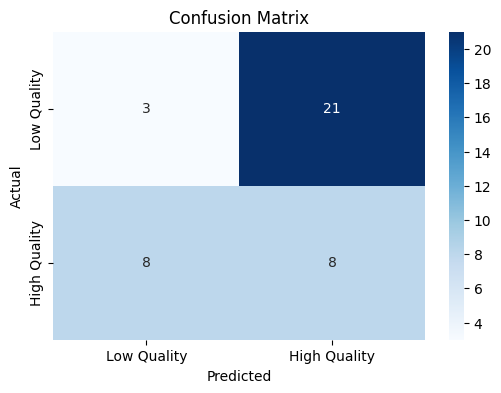
コードの解説:
- データ生成:
サンプルデータを生成し、pandasのデータフレームに格納しています。
各特徴量(カフェイン含量、酸味、苦味、甘味、ボディ)は正規分布に従ってランダムに生成されています。qualityは0(低品質)と1(高品質)のランダムな値を持ちます。 - データの前処理:
特徴量とターゲット変数にデータを分割しています。
データセットをトレーニングセットとテストセットに分割し、標準化しています。 - モデルのトレーニング:
ランダムフォレスト分類器を使用してモデルをトレーニングしています。 - モデルの評価:
テストセットに対する予測を行い、精度を評価しています。
混同行列をプロットし、モデルの性能を視覚的に評価しています。
特徴量の重要度をプロットし、どの特徴が品質予測に重要かを示しています。
AIと機械学習を用いて人工コーヒーの成分を分析し、品質を予測できます。
AIで人工コーヒーの開発:応用アイデア
AIで人工コーヒーを開発する技術の、応用アイデアを考えてみましょう。
同業種への応用アイデア(飲料業界):
- 人工ワインの開発:
ワインの風味や香りを分子レベルで解析し、人工的に再現する技術を活用できます。
気候変動やブドウの不作に対応する手段として有効です。 - 新しいフレーバーのコーヒー:
消費者の嗜好に合わせたカスタムフレーバーのコーヒーを作成できます。
市場調査とAIを組み合わせてトレンドを予測し、新製品を開発します。 - 低カフェインコーヒーの開発:
カフェインの含有量を調整し、健康志向の消費者に向けた製品を提供します。
機械学習を用いて最適な成分配合を見つけます。
他業種への応用アイデア:
食品業界:
- 人工チョコレートの開発:
カカオの風味を分子レベルで解析し、人工的に再現することで、安定供給を実現します。
環境負荷の少ない持続可能なチョコレート製品を開発できます。 - カスタム食品の開発:
消費者の健康状態や嗜好に合わせたオーダーメイド食品を作成します。
AIを使って個々の栄養ニーズに最適なレシピを生成します。
医薬品業界:
- 薬品の成分最適化:
AIを使って薬品の成分を最適化し、副作用を減らし効果を高めます。
患者データを解析し、個別の治療法を開発します。 - 新薬の開発:
化合物の効果を予測し、新薬の候補を迅速に見つけるために機械学習を使用します。
臨床試験のデータを解析し、安全性と有効性を向上させます。
ファッション業界:
- テキスタイルの開発:
AIを使って新しい素材の組み合わせやデザインを生成します。
消費者のトレンドを分析し、需要に応じた商品を迅速に提供します。 - 個別フィッティング:
顧客の身体データを解析し、最適なサイズや形状の衣服を提供します。
3Dスキャン技術とAIを組み合わせたカスタムフィットの衣服を製造します。
AIで人工コーヒーの開発は、さまざまな分野に応用できそうですね。まさに、早い者勝ちのビジネスチャンスです。
AIで人工コーヒーの開発:まとめ
AIで人工コーヒーの開発について解説しました。
AI技術やPythonを用いて、人工コーヒーの成分を分析し、品質を予測する具体的なコードを紹介しましたので、AIエンジニアやプログラマーに転職を考えている方の参考になったと思います。
また、AI技術を応用したビジネスアイデアも紹介しました。
あなたもAIエンジニアやプログラマーに転職して、AIで人工コーヒーの開発に挑戦しましょう。
これからの時代、革新的な製品を生み出すのは、AIエンジニアです。

▼AIを使った副業・起業アイデアを紹介♪

