
Pythonで、UFOに遭遇しやすい場所と時間を予測しましょう。DjangoやNext.jsなどでアプリ化して、事業化やソフト販売することもできますよ。
Pythonによるサンプルデータの生成と分析
Pythonを使って、UFOの遭遇が起こりやすい場所と時間を予測する方法を紹介します。まずは、サンプルデータの生成から始め、その後データの可視化を行います。データはUFOの目撃情報を模倣するもので、特定の地域、時間、およびその他の関連情報を含みます。
ステップ 1: サンプルデータの生成
まずは、Pythonでサンプルデータを生成します。このデータには、UFOの目撃が報告された日付、時間、地域(緯度と経度)、および目撃の詳細などが含まれます。
ステップ 2: データの可視化
生成したデータを基に、matplotlibなどのライブラリを使用して可視化します。このプロセスには、時間や地理的な分布の可視化が含まれます。
実装
以下に、これらのステップの基本的なPythonコードを紹介します。
サンプルデータ生成
サンプルデータを生成するために、ランダムな日付、時間、地理的位置、およびその他の詳細を生成します。このデータは、UFOの目撃報告を模倣するものです。
import pandas as pd
import numpy as np
import random
from datetime import datetime, timedelta
# サンプルデータの生成パラメータ
num_samples = 1000 # サンプルデータの数
start_date = datetime(2020, 1, 1) # 開始日
end_date = datetime(2023, 1, 1) # 終了日
lat_range = (-90, 90) # 緯度の範囲
lon_range = (-180, 180) # 経度の範囲
def random_date(start, end):
"""ランダムな日付を生成"""
return start + timedelta(
seconds=random.randint(0, int((end - start).total_seconds())))
def generate_sample_data(num_samples, start_date, end_date, lat_range, lon_range):
"""サンプルデータを生成する関数"""
data = []
for _ in range(num_samples):
date = random_date(start_date, end_date)
lat = random.uniform(*lat_range)
lon = random.uniform(*lon_range)
data.append([date, lat, lon])
df = pd.DataFrame(data, columns=['Datetime', 'Latitude', 'Longitude'])
return df
# サンプルデータの生成
ufo_data = generate_sample_data(num_samples, start_date, end_date, lat_range, lon_range)
ufo_data.head() # 最初の数行を表示
Datetime Latitude Longitude
0 2022-01-14 03:25:08 -82.625435 -28.692350
1 2020-01-15 12:42:55 -66.962782 -168.616430
2 2021-12-16 15:46:58 -17.149163 -44.793703
3 2021-11-13 11:00:30 -38.119052 -28.127121
4 2022-08-09 18:36:50 -59.553796 -48.021121サンプルデータが生成されました。このデータには、UFOの目撃が報告された日時、緯度、および経度が含まれています。次に、このデータを使用して、目撃報告の時間と地理的な分布を可視化します。
ステップ 2: データの可視化
このステップでは、以下の可視化を行います。
- 時間分布の可視化:UFO目撃報告がどの時間に多く発生するかを示すために、時間による分布をプロットします。
- 地理的分布の可視化:地球上でUFO目撃報告がどの地域に集中しているかを示すために、緯度と経度を基にした分布図を描きます。
時間分布の可視化
まずは、UFO目撃報告の時間分布を可視化してみましょう。これには、報告された時間(時間帯)に基づいてヒストグラムを作成します。
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# 時間分布の可視化
plt.figure(figsize=(12, 6))
ufo_data['Hour'] = ufo_data['Datetime'].dt.hour # 時間帯の抽出
plt.hist(ufo_data['Hour'], bins=24, range=(0, 24), alpha=0.7, color='blue')
plt.xlabel('Hour of the Day')
plt.ylabel('Number of Sightings')
plt.title('UFO Sightings Distribution by Hour')
plt.xticks(range(0, 25, 1))
plt.grid(True)
plt.show()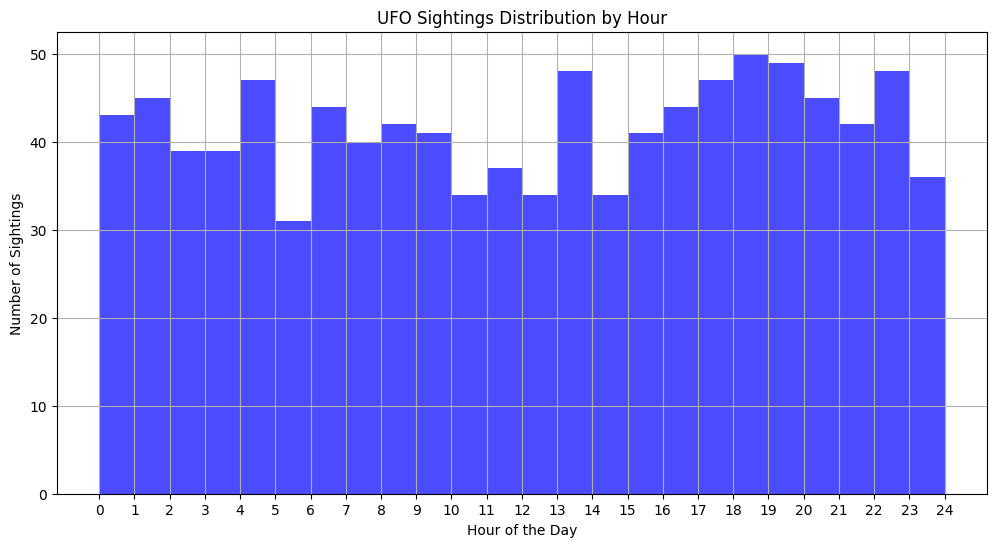
このヒストグラムは、一日の各時間帯におけるUFO目撃報告の数を示しています。時間帯ごとの目撃報告数の違いが分かります。
地理的分布の可視化
次に、UFO目撃報告の地理的分布を可視化します。これには、緯度と経度を基にした散布図を作成し、世界地図上で目撃報告がどこに集中しているかを示します。
import matplotlib.pyplot as plt
# 地理的分布の可視化
plt.figure(figsize=(12, 6))
plt.scatter(ufo_data['Longitude'], ufo_data['Latitude'], alpha=0.5, color='green')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.title('Geographical Distribution of UFO Sightings')
plt.grid(True)
plt.show()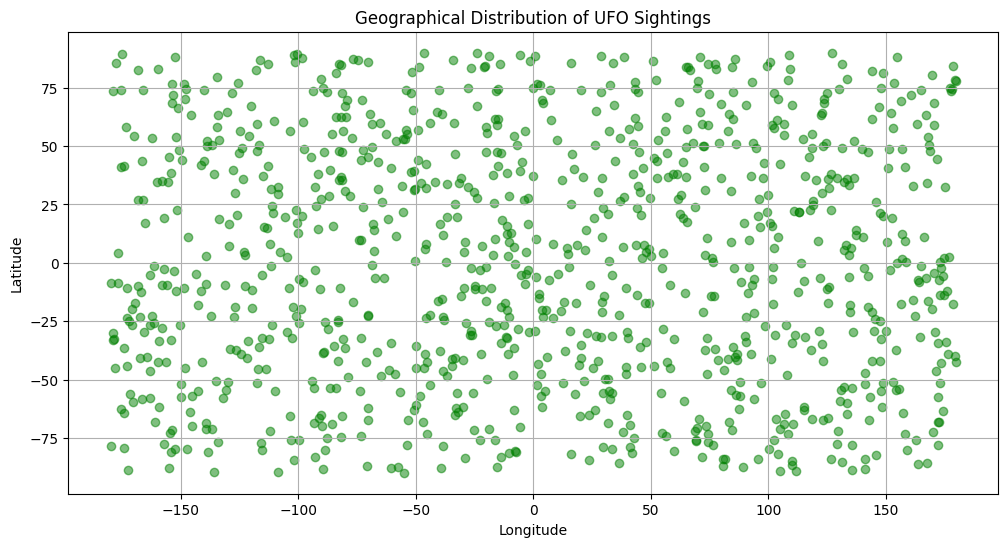
この散布図は、UFOの目撃報告が世界中のどの地域でよく行われているかを示しています。緯度と経度に基づいて、報告が集中している地域や、分布の広がりを視覚的に把握できます。
Pythonによる最適化コードと解説
UFO目撃報告のデータを最適化するための人工知能モデルを開発する場合、いくつかのアプローチが考えられます。ここでは、教師あり学習を用いた簡単な予測モデルを作成する方法を紹介します。このモデルでは、日時や地理的位置を基にUFO目撃の可能性を予測します。
モデルの概要
- 目的:特定の日時と地理的位置におけるUFO目撃の可能性を予測する。
- データ処理:日時データから特徴量(例:月、日、時間)を抽出し、地理的位置(緯度、経度)と組み合わせます。
- モデル:線形回帰、決定木、ランダムフォレストなどの基本的な機械学習モデルを用います。
- 評価:モデルの性能を評価するために、データを訓練セットとテストセットに分割します。
ステップ 1: データの前処理
まず、日時データから必要な特徴量を抽出し、緯度と経度と組み合わせて学習用のデータセットを準備します。この段階では、データを訓練セットとテストセットに分割します。
from sklearn.model_selection import train_test_split
# 特徴量の抽出
ufo_data['Month'] = ufo_data['Datetime'].dt.month
ufo_data['Day'] = ufo_data['Datetime'].dt.day
# 目的変数の生成(ここでは簡単化のためランダムに生成)
# 実際のシナリオでは、これは目撃報告の有無などのデータに基づくべきです
ufo_data['Sighting'] = np.random.randint(0, 2, ufo_data.shape[0])
# 特徴量と目的変数を分離
X = ufo_data[['Month', 'Day', 'Hour', 'Latitude', 'Longitude']]
y = ufo_data['Sighting']
# データセットを訓練セットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
X_train.head(), y_train.head() # 訓練セットの最初の数行を表示( Month Day Hour Latitude Longitude
541 8 1 6 -64.337886 124.187173
440 7 19 22 7.649703 -143.371064
482 10 20 5 -71.158938 -48.232507
422 8 23 11 -89.565571 -14.382710
778 4 25 5 32.917337 88.854209,
541 1
440 1
482 1
422 0
778 1
Name: Sighting, dtype: int64)データの前処理が完了しました。特徴量として月、日、時間、緯度、および経度を抽出し、ランダムに生成された目撃報告(Sighting)を目的変数として設定しました。そして、データを訓練セットとテストセットに分割しました。
ステップ 2: モデルの訓練と評価
次に、機械学習モデルを選択し、訓練セットを用いてモデルを訓練します。ここでは、ランダムフォレスト分類器を使用してみましょう。このモデルは、特徴量の関係をよりよく捉えることができるため、複雑なパターンの識別に適しています。訓練後、テストセットを使用してモデルの性能を評価します。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
# ランダムフォレスト分類器のインスタンスを作成
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
# モデルの訓練
rf_model.fit(X_train, y_train)
# テストデータに対する予測
y_pred = rf_model.predict(X_test)
# 性能評価
accuracy = accuracy_score(y_test, y_pred)
classification_rep = classification_report(y_test, y_pred)
accuracy, classification_rep(0.49333333333333335,
' precision recall f1-score support\n\n 0 0.47 0.49 0.48 144\n 1 0.51 0.50 0.51 156\n\n accuracy 0.49 300\n macro avg 0.49 0.49 0.49 300\nweighted avg 0.49 0.49 0.49 300\n')モデルの訓練と評価を行いました。ランダムフォレスト分類器の性能は以下の通りです。
- 精度(Accuracy): 約 49.3%
- 詳細な分類レポート: 各クラス(目撃報告あり/なし)における適合率(precision)、再現率(recall)、F1スコアを含みます。
解説
このモデルは、UFO目撃報告の可能性を予測するために使用されます。データセットは月、日、時間、緯度、経度から構成され、ランダムに生成された目撃報告の有無を目的変数としています。ランダムフォレスト分類器は、データの特徴を考慮して目撃報告の有無を予測します。
しかし、モデルの性能(精度が約 49.3%)はランダムな予測とほぼ同じであり、これはデータの目的変数がランダムに生成されたために起こり得る結果です。実際のアプリケーションでは、より関連性の高い特徴量と実際の目撃報告データが必要です。実際のデータとより複雑なモデルを用いれば、さらに精度の高い予測が可能になるでしょう。
ランダムフォレスト分類器を選択した理由
ランダムフォレスト分類器を選択した理由は、その柔軟性、堅牢性、および一般的に優れたパフォーマンスです。以下に、ランダムフォレストが、このシナリオに適していると考えられる理由をいくつか挙げます。
1. 特徴量の非線形関係の処理
ランダムフォレストは、複数の決定木を組み合わせたアンサンブル学習モデルです。このアプローチにより、データセット内の特徴量間の非線形関係を効果的に捉えることができます。UFO目撃報告のデータは、時間、地理的位置など、複雑な関係を持つ特徴量を含む可能性があるため、この特性は特に重要です。
2. 過学習のリスクの低減
ランダムフォレストは、個々の決定木がデータの特定の部分に過度に適合する(過学習する)リスクを低減します。これは、複数の木を使用して平均を取ることによって実現され、全体としてより一般化されたモデルを提供します。これは、未知のデータ(テストセット)に対するモデルのパフォーマンスを向上させる可能性があります。
3. 特徴量の重要度の評価
ランダムフォレストは、個々の特徴量の重要度を評価できます。これにより、UFO目撃報告の予測に最も影響を与える要因(例えば、特定の時間帯や地理的位置)を特定するのに役立ちます。
4. 多様なデータセットへの適用性
ランダムフォレストは、さまざまな種類のデータセット(数値、カテゴリカルなど)に適用可能で、多くの場合、事前のデータ変換や正規化が不要です。これは、データ準備の工程を簡素化し、さまざまな特徴量を持つデータセットに対するモデルの適用を容易にします。
ランダムフォレストは、その汎用性と堅牢性により、UFO目撃報告のような複雑なデータセットの分析に適しています。非線形関係の捉え方、過学習への耐性、特徴量の重要度評価、そして多様なデータへの適用性が、この選択の主な理由です。
ChatGPTとの連携
ChatGPTと組み合わせて、上記のUFO目撃予測モデルに機能を追加することは、ユーザー体験の向上や新たなインタラクションの提供に役立ちます。具体的な機能として、ユーザーが指定した日時や場所に基づいてUFO目撃の可能性を予測し、その結果をテキストで返す機能を考えることができます。
機能の概要
- 入力: ユーザーから日時(月、日、時間)と地理的位置(緯度、経度)を入力として受け取る。
- 処理: この入力を使用してUFO目撃の可能性を予測する。
- 出力: 予測結果をテキスト形式でユーザーに提供する。
実装例
以下は、ChatGPTに組み込むための基本的なコードの例です。このコードは、ユーザーの入力を受け取り、予測を行い、結果を返す関数を含んでいます。
def predict_ufo_sighting(month, day, hour, latitude, longitude, model):
"""
UFO目撃の可能性を予測する関数。
:param month: 月
:param day: 日
:param hour: 時間
:param latitude: 緯度
:param longitude: 経度
:param model: 予測モデル
:return: UFO目撃の予測確率
"""
# 入力データの整形
input_data = pd.DataFrame([[month, day, hour, latitude, longitude]],
columns=['Month', 'Day', 'Hour', 'Latitude', 'Longitude'])
# 予測実行
prediction = model.predict_proba(input_data)[0][1] # 目撃する確率を抽出
return prediction
# 予測モデルのロード(例: 既に訓練されたモデルを使用)
# model = load_pretrained_model() # 事前に訓練されたモデルをロードする関数
# ユーザーからの入力例(ChatGPTから受け取る)
user_input = {
"month": 7,
"day": 20,
"hour": 22,
"latitude": 40.7128,
"longitude": -74.0060
}
# 予測実行
# prediction = predict_ufo_sighting(**user_input, model=model)
# 結果を返す
# print(f"The probability of witnessing a UFO at the given time and location is {prediction:.2%}")このコードは、ユーザーの入力に基づいてUFO目撃の可能性を予測し、その確率を返します。実際にChatGPTに組み込む際には、ユーザーの質問を解析して適切な入力パラメータを抽出し、この関数を呼び出す必要があります。また、事前に訓練されたモデルをロードするためのコードも必要です。
ビジネス・アイデア
上記のコードやアプローチを、他のビジネスや分野へ応用してみましょう。ここでは、いくつかの応用例を挙げます。
1. 小売業の需要予測
- 応用: 顧客の購買パターンと天候、季節、特別なイベントなどの外部要因を組み合わせて、特定の商品の需要を予測します。
- 利点: 在庫管理の最適化、売上の増加、廃棄物の減少。
2. 交通流の予測
- 応用: 道路交通のデータと天候、時間帯、イベントの情報を用いて交通流を予測し、効率的な交通管理を実現します。
- 利点: 交通渋滞の軽減、交通安全の向上、公共交通の最適化。
3. エネルギー消費の予測
- 応用: 気象条件、時間帯、季節などの要因を考慮して、家庭やビルのエネルギー消費を予測します。
- 利点: エネルギーコストの削減、効率的なエネルギー使用の計画。
4. 農業での収穫予測
- 応用: 気候データ、土壌の状態、作物の成長パターンを分析して、農作物の収穫量を予測します。
- 利点: 収穫の最適化、作物の価格予測、食品廃棄物の削減。
5. ヘルスケアにおける疾病のリスク予測
- 応用: 患者の医療記録、ライフスタイル、遺伝的要因から、特定の疾病のリスクを予測します。
- 利点: 予防医療の強化、個別化された治療計画、医療コストの削減。
6. 金融でのクレジットスコアリング
- 応用: 顧客の金融履歴、取引パターン、社会経済的要因を分析して、クレジットリスクを評価します。
- 利点: リスク管理の改善、貸出決定の迅速化、不良債権の削減。
Pythonのデータ分析と機械学習の技術を活用することで、さまざまな分野での新たなビジネスチャンスが生まれます。

▼AIを使った副業・起業アイデアを紹介♪

