
はじめに
ゴミ収集の現状と課題
近年、都市化が進むにつれてゴミの量が増加し、その処理が大きな社会問題です。ゴミ収集の効率化は、環境負荷の軽減やコスト削減に直結するため、多くの自治体や企業がこの問題に取り組んでいます。しかし、ゴミの量は日々変動し、季節やイベントによっても大きく異ります。予測が困難であり、過剰または不足による収集作業の非効率が生じています。
本記事の目的と概要
Pythonと人工知能(AI)技術を活用して、ゴミの量を予測し、収集作業を最適化する方法について解説します。Pythonはその柔軟性と強力なライブラリにより、データ処理や機械学習に最適なプログラミング言語です。Pythonを使ってサンプルデータを生成し、これをもとにゴミ量の予測モデルを構築します。このプロセスで、実際のゴミ収集作業における効率化とコスト削減の可能性を探ります。AI技術の進歩により、将来的にはさらに高度な予測や自動化が可能になると考えられ、その展望についても解説します。
Pythonを活用したゴミ量予測の基本
Pythonとは何か?
Pythonは、その読みやすいコードと書きやすい構文で知られるプログラミング言語です。理解しやすく、さまざまなプログラミング分野で広く使われています。特にデータサイエンスや機械学習の分野での人気は高く、多くのデータ分析ツールやライブラリがPythonで提供されています。Pythonは、その汎用性と高い拡張性により、複雑なデータ処理や予測分析にも適しています。ゴミ量予測のようなタスクにも、有効に活用できます。
予測分析に必要なPythonライブラリの紹介
Pythonを使用する際、特にデータ分析や機械学習では、いくつかの重要なライブラリがあります。主なものとしては、以下のようなものが挙げられます。
- NumPy: 数値計算を効率的に行うためのライブラリで、大規模な数値データの操作や計算を高速に実行します。
- Pandas: データ分析を容易にするための機能を提供するライブラリで、データの読み込み、整理、分析が行えます。
- Matplotlib: データを視覚化するライブラリで、グラフやチャートを簡単に作成できます。
- Scikit-learn: 機械学習のためのライブラリで、多くの学習アルゴリズムや便利なツールを提供します。
これらのライブラリを組み合わせることで、ゴミの量の予測分析を効果的に行うことができます。
データの収集と前処理
データ分析のプロセスでは、データの収集と前処理がとても重要です。適切なデータを収集し、それを分析のために整えることが、予測の精度を高める鍵となります。ゴミ量予測の場合、収集するデータには、地域ごとのゴミの量、収集日、天気、季節、祝日などの情報が含まれることが一般的です。
まず、データ収集の段階では、これらの情報を過去数年分集めることが理想的です。実際には既存のデータセットを使うか、あるいは実験的にサンプルデータを生成して使用することもできます。次に、前処理の段階では、欠損値の処理や異常値の除去、データの正規化などを行います。これにより、データは分析に適した形に整えられます。
Pythonでは、データの前処理にPandasライブラリを使用するのが一般的です。例えば、以下のようなサンプルコードを使用して、簡単なデータセットの前処理を行うことができます。
import pandas as pd
import numpy as np
# サンプルデータの生成
data = {
'Date': pd.date_range(start='2023-01-01', periods=100, freq='D'),
'GarbageAmount': np.random.randint(100, 500, size=100),
'Weather': np.random.choice(['Sunny', 'Rainy', 'Cloudy'], size=100)
}
df = pd.DataFrame(data)
# データの前処理
df['DayOfWeek'] = df['Date'].dt.dayofweek
df['IsWeekend'] = df['DayOfWeek'].apply(lambda x: 1 if x >= 5 else 0)
df = pd.get_dummies(df, columns=['Weather'])
df.head()
Date GarbageAmount DayOfWeek IsWeekend Weather_Cloudy Weather_Rainy Weather_Sunny
0 2023-01-01 183 6 1 0 0 1
1 2023-01-02 189 0 0 1 0 0
2 2023-01-03 430 1 0 0 0 1
3 2023-01-04 283 2 0 0 0 1
4 2023-01-05 374 3 0 0 0 1このコードでは、日付、ゴミの量、天気の情報を含むサンプルデータセットを生成し、曜日や週末かどうかの情報を追加します。さらに、天気のデータをダミー変数に変換します。このような前処理を行うことで、データは機械学習モデルによる予測分析に適した状態になります。
Pythonでサンプルデータ作成と解説
予測モデルの開発には、実際のデータが不可欠ですが、時には実データが利用できないこともあります。そのような場合に役立つのが、Pythonを使ったサンプルデータの作成です。サンプルデータを生成することで、モデルの開発や評価を実施できます。
ここでは、PythonのPandasライブラリとNumPyライブラリを用いて、ゴミの量を予測するためのサンプルデータを作成する方法について説明します。このデータセットは、日付、ゴミの量、天気などの情報を含むことにします。
まず、必要なライブラリをインポートします。
import pandas as pd
import numpy as np次に、サンプルデータを生成します。ここでは、ランダムな日付とそれに対応するゴミの量、天気のデータを作成します。
# サンプルデータの生成
num_days = 365
start_date = '2023-01-01'
dates = pd.date_range(start=start_date, periods=num_days)
garbage_amount = np.random.randint(100, 500, size=num_days)
weather_conditions = np.random.choice(['Sunny', 'Rainy', 'Cloudy'], size=num_days)
data = {
'Date': dates,
'GarbageAmount': garbage_amount,
'Weather': weather_conditions
}
df = pd.DataFrame(data)ここで生成したデータフレーム df は、予測モデルの開発や評価のための基盤となります。例えば、以下のようにデータの一部を表示できます。
print(df.head()) Date GarbageAmount Weather
0 2023-01-01 445 Cloudy
1 2023-01-02 425 Rainy
2 2023-01-03 121 Rainy
3 2023-01-04 351 Cloudy
4 2023-01-05 235 Rainyこのサンプルデータを視覚化してみましょう。Matplotlibライブラリを使用して、ゴミの量の分布をグラフで表示します。
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(df['Date'], df['GarbageAmount'], label='Garbage Amount')
plt.xlabel('Date')
plt.ylabel('Garbage Amount')
plt.title('Daily Garbage Amount Over Time')
plt.legend()
plt.show()
このグラフを使うことで、データの傾向やパターンを視覚的に理解できます。サンプルデータの作成と分析は、実際のデータを用いた分析に不可欠なスキルです。
サンプルデータを利用した予測モデルの構築方法
作成したサンプルデータを活用して、ゴミの量を予測するモデルを構築する方法について説明します。この過程では、Pythonでのデータ処理技術や機械学習の基本的な知識が必要です。
データの準備
まず、サンプルデータを訓練データとテストデータに分割します。これには、scikit-learnライブラリの train_test_split 関数を使用します。
from sklearn.model_selection import train_test_split
# DataFrameの 'Date' 列が日付データを含んでいる場合
df['year'] = df['Date'].dt.year
df['month'] = df['Date'].dt.month
df['day'] = df['Date'].dt.day
# 元の 'Date' 列を削除
df = df.drop('Date', axis=1)
# 'Weather' 列をワンホットエンコーディングする
df_encoded = pd.get_dummies(df, columns=['Weather'])
# 新しいデータフレームを表示
print(df_encoded.head())
# 説明変数と目的変数の分離(エンコードされたデータを使用)
X = df_encoded.drop('GarbageAmount', axis=1)
y = df_encoded['GarbageAmount']
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)モデルの選択
ゴミの量の予測には、回帰モデルが適しています。ここでは、シンプルな線形回帰モデルを使用します。
from sklearn.linear_model import LinearRegression
# モデルのインスタンス化
model = LinearRegression()モデルの訓練
次に、モデルを訓練データで訓練します。
# モデルの訓練
model.fit(X_train, y_train)モデルの評価
モデルの性能を評価するために、テストデータを使用します。
from sklearn.metrics import mean_squared_error
# テストデータで予測
predictions = model.predict(X_test)
# 性能評価
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error: {mse}") GarbageAmount year month day Weather_Cloudy Weather_Rainy \
0 289 2023 1 1 1 0
1 383 2023 1 2 0 0
2 181 2023 1 3 1 0
3 327 2023 1 4 1 0
4 368 2023 1 5 1 0
Weather_Sunny
0 0
1 1
2 0
3 0
4 0
Mean Squared Error: 10647.059820535358結果の可視化
予測結果を可視化してみましょう。実際の値と予測値をプロットして比較します。
plt.figure(figsize=(10, 6))
plt.scatter(y_test, predictions)
plt.xlabel('Actual Garbage Amount')
plt.ylabel('Predicted Garbage Amount')
plt.title('Actual vs Predicted Garbage Amount')
plt.show()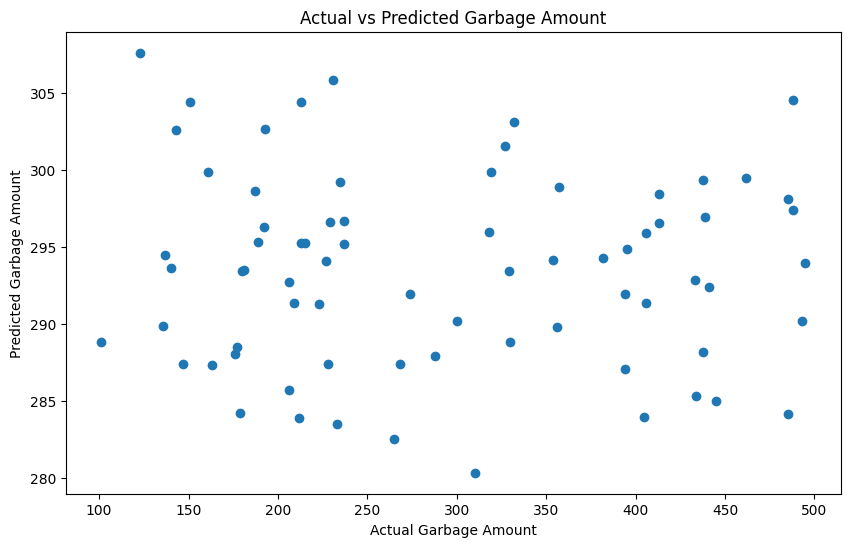
このグラフから、モデルがどの程度の精度でゴミの量を予測できているかを視覚的に確認できます。予測モデルの構築と評価は、実際のデータを用いた分析においてとても重要なステップです。
AIによるゴミ量予測のメカニズム
予測モデルの種類と特徴
AIを活用したゴミ量予測では、様々な予測モデルが使用されます。それぞれのモデルには独自の特徴があり、ゴミ収集の効率化や最適化において重要な役割を果たします。以下に、主なモデルの種類とその特徴を紹介します。
1. 線形回帰モデル
線形回帰は最も基本的な予測モデルであり、変数間の線形関係をモデル化します。シンプルで解釈しやすいため、初期の分析段階や比較的単純なデータセットに適しています。
2. 決定木
決定木は、データを分類するためのルールベースのアプローチを採用しています。このモデルは直感的であり、どのような条件で分割が行われるかを容易に理解できます。複雑なデータセットにも対応可能ですが、過学習する傾向に注意が必要です。
3. ランダムフォレスト
ランダムフォレストは複数の決定木を組み合わせたアンサンブル学習モデルです。単一の決定木よりも過学習のリスクを軽減し、高い精度を提供します。しかし、モデルの解釈性は低下する可能性があります。
4. サポートベクターマシン(SVM)
SVMは、特に分類問題で効果的なモデルですが、回帰問題にも応用できます。複雑なデータセットのパターンを把握するのに優れていますが、計算コストが高いというデメリットがあります。
5. ニューラルネットワーク
深層学習の基礎となるニューラルネットワークは、非線形関係や複雑なパターンを学習できます。大規模なデータセットに対して優れた予測精度を発揮しますが、モデルの解釈性や計算資源の要求は他のモデルより高いです。
6. 時系列モデル
ゴミ収集のような時間に依存するデータの予測には、時系列分析モデルが有効です。ARIMAや季節性を考慮したモデルなどがあり、時間の流れに沿った変動を捉えます。
これらのモデルは、それぞれに適した用途やデータタイプがあります。ゴミ量予測のような具体的な課題に対して最適なモデルを選択することが重要です。
ゴミ量予測に適したモデルの選定理由
ゴミ量の予測において、最適なモデルを選定することは、予測の精度を高めるためにとても重要です。ゴミ量予測に適したモデルを選定する際に考慮すべきポイントは以下の通りです。
データの性質の理解
ゴミ量のデータは、季節性、天候、地域のイベント、人口動態など、様々な要因によって影響を受ける可能性があります。これらの要因を考慮して、データの性質を正確に理解することが重要です。
時系列データの扱い
ゴミ量は時間経過とともに変化するため、時系列分析が適しています。季節性やトレンドを考慮できるモデル(例:ARIMA、季節性ARIMA)の選択が効果的です。
複雑なパターンの把握
ゴミ量に影響を与える要因が多様で、相互作用が複雑な場合は、ランダムフォレストやニューラルネットワークなどのより複雑な関係性をモデル化できる手法が適しています。
解釈性の重視
ゴミ収集業務の最適化を図る場合、モデルの解釈性は重要です。決定木や線形回帰モデルは、予測の根拠を理解しやすいため、適切な場合があります。
コンピューティングリソース
大規模なデータセットや複雑なモデルを用いる場合、計算資源の制約を考慮する必要があります。リソースが限られている場合は、計算コストが低いモデルを選択するか、クラウドコンピューティングリソースの活用を検討すると良いでしょう。
これらの考慮点を踏まえ、ゴミ量予測には時系列分析を基本とし、データの特性に応じて他のモデルを併用する手法が効果的です。実際のデータを用いたモデルの評価やチューニングを通じて、最適なモデルを選定します。
ゴミ量力のサンプルデータ作成と解説
ゴミ量予測モデルの開発にあたり、実際のデータを用いることが理想的ですが、ここではPythonを使ってサンプルデータを生成しましょう。
サンプルデータの生成
まず、PythonのNumPyとPandasライブラリを利用して、日付とゴミ量を含むサンプルデータを生成します。ここでは、次の要素を考慮してデータを作成します。
- 日付:特定の期間(例えば、過去1年間の毎日)。
- ゴミ量:日ごとのゴミ量で、季節性やランダムな変動を含む。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# サンプルデータの生成
np.random.seed(0)
dates = pd.date_range(start="2022-01-01", end="2022-12-31", freq='D')
daily_garbage = np.random.normal(20, 5, len(dates)) + 10 * np.sin(np.linspace(0, 2 * np.pi, len(dates)))
# データフレームの作成
df = pd.DataFrame({'Date': dates, 'Garbage': daily_garbage})
df.set_index('Date', inplace=True)
# 最初の5行を表示
print(df.head())Garbage
Date
2022-01-01 28.820262
2022-01-02 22.173392
2022-01-03 25.238851
2022-01-04 31.722080
2022-01-05 30.027701データの可視化
データの傾向を視覚的に理解するために、Matplotlibを使用して時系列プロットを作成します。
plt.figure(figsize=(12, 6))
plt.plot(df.index, df['Garbage'])
plt.title('Daily Garbage Volume Over a Year')
plt.xlabel('Date')
plt.ylabel('Garbage Volume')
plt.grid(True)
plt.show()
このプロットから、ゴミ量の日々の変動や季節的なパターンを観察できます。このような可視化は、モデルの選択や特徴量エンジニアリングの際にとても役立ちます。
データの基本的な特性
データの基本統計を調べることで、データの分布や範囲についての洞察を得られます。
print(df.describe())Garbage
count 365.000000
mean 19.937578
std 8.952009
min -3.857005
25% 12.692366
50% 19.787961
75% 26.509706
max 39.427524このサンプルデータの生成と解析は、ゴミ量予測モデルの構築において、初期段階の重要なステップです。実際のデータを扱う際にも、これらの手順はデータの理解を深め、適切なモデリング戦略を立てるのに役立ちます。
モデルの訓練と精度向上のコツ
人工知能(AI)によるゴミ量予測のために、Pythonを活用してモデルを訓練し、その精度を向上させる方法について解説します。
モデルの選択
ゴミ量予測には、時系列データを扱うことが多いため、その特性に適したモデルを選択することが重要です。たとえば、ランダムフォレストや勾配ブースティング、リカレントニューラルネットワーク(RNN)などが有効です。
データの前処理
データの品質はモデルの精度に直接影響します。不要なデータの除去、欠損値の処理、正規化などの前処理が重要です。
特徴量の選定
ゴミ量に影響を与える要因を特徴量として選定します。例えば、日付、天候、季節、イベントの有無などが考えられます。
モデルの訓練
サンプルデータをトレーニングセットとテストセットに分割し、モデルを訓練します。過学習を避けるため、適切なパラメータの調整が必要です。
精度の評価
モデルの精度を評価するために、RMSE(Root Mean Square Error)やMAE(Mean Absolute Error)などの指標を使用します。
ハイパーパラメータのチューニング
モデルの精度をさらに向上させるために、ハイパーパラメータのチューニングが効果的です。Grid SearchやRandom Searchを用いて、最適なパラメータを探索します。
可視化
Matplotlibを用いて、予測結果を可視化します。予測結果と実際のデータを比較することで、モデルの精度を直感的に評価できます。
# 予測結果の可視化例
plt.figure(figsize=(12, 6))
plt.plot(test_data['Date'], test_data['Actual'], label='Actual')
plt.plot(test_data['Date'], test_data['Predicted'], label='Predicted')
plt.title('Prediction vs Actual')
plt.xlabel('Date')
plt.ylabel('Garbage Volume')
plt.legend()
plt.grid(True)
plt.show()これらのステップに従うことで、精度の高いゴミ量予測モデルを構築できます。
ChatGPTとの連携
ChatGPTによるデータ分析と予測サポート
ChatGPTは、データ分析や予測においてとても役立つツールです。Pythonやデータサイエンスに関する豊富な知識を持ち、コードの提案やデバッグ、データ分析をアドバイスできます。また、機械学習モデルの選定やハイパーパラメータのチューニングに関するアドバイスも提供します。
ゴミ収集の最適化に向けた対話型プランニング
ゴミ収集の最適化において、ChatGPTは有益な対話型プランニングを提供します。これにより、異なるシナリオにおけるゴミ収集ルートの最適化、コスト削減の方法、収集スケジュールの調整などについて、リアルタイムで議論できます。さらに、ChatGPTは地域ごとのゴミの傾向や季節的な変動を考慮した提案もできます。
ChatGPTを用いたリアルタイムの問題解決とサポート
ChatGPTは、ゴミ収集におけるリアルタイムの問題解決にも役立ちます。たとえば、予期せぬ状況が発生した際の迅速な対応策の提案や、データ収集の最適化方法の提案などです。さらに、ChatGPTはデータ分析の結果を基に、将来のゴミ量の変動予測や収集スケジュールの調整に関するアドバイスが可能です。
これらの機能により、ChatGPTはゴミ収集作業の効率化に大きく貢献できます。
実際のゴミ収集作業への応用
収集作業の効率化とコスト削減
Pythonと人工知能(AI)を用いたゴミ量の予測は、ゴミ収集作業の効率化とコスト削減に大きく貢献します。この技術により、ゴミ収集のルーティングが最適化され、不要な走行距離が減少し、燃料費や時間の削減が実現できます。
ゴミ量予測の実践的な応用
- 最適化されたルートプランニング: 予測されたゴミの量に基づいて、収集ルートを効率的に計画できます。これにより、ゴミ収集車の走行距離が減少し、燃料コストの削減に繋がります。
- 収集スケジュールの調整: ゴミの量の予測を用いて、収集の頻度や日程を調整することで、無駄な収集回数を減らすことができます。
- リソースの最適配分: 予測に基づいて、必要な収集車両の数や人員を最適化できます。
コスト削減と環境への影響
- コスト削減: 効率化されたルートとスケジュールにより、全体的な運用コストが削減されます。
- 環境への配慮: 走行距離の削減は、CO2排出量の削減にも繋がり、環境にやさしいゴミ収集作業に貢献します。
PythonとAIの応用によって、ゴミ収集作業はよりスマートで効率的になります。
PythonとAIの将来的な可能性
ゴミ収集以外への可能性
PythonとAIの技術は、ゴミ収集の最適化だけでなく、さまざまな分野での応用が期待されています。例えば、交通流の予測、エネルギー消費の最適化、製造業の効率化など、多岐にわたる分野での活用が考えられます。
交通流の予測と管理
- 交通渋滞の予測: AIを利用して、都市部の交通渋滞を予測し、交通流をスムーズにします。
- 最適な交通管理: 交通量データを分析し、信号機のタイミングなどを最適化することで、交通の流れを改善できます。
エネルギー管理
- エネルギー消費の最適化: 建物や工場のエネルギー消費をAIで分析し、無駄な消費を削減します。
- スマートグリッドの管理: AIを活用して電力供給と需要をバランス良く管理し、エネルギー効率の向上を図ります。
スマートシティへの組み込みと社会的影響
スマートシティの構築において、PythonとAIの技術は中心的な役割を果たします。都市のインフラ、交通、エネルギー管理などが、データ駆動型で効率的に運用されるようになります。
スマートシティでの応用
- インフラの最適管理: AIによるデータ分析で、都市のインフラのメンテナンスや更新を効率的に行えます。
- 持続可能な都市開発: エネルギー、水資源、廃棄物管理などをAIで最適化し、持続可能な都市開発を実現します。
社会的影響
- 住民の生活の質の向上: 効率的な都市管理は、住民の生活の質の向上に直結します。
- 環境への配慮: エネルギー消費の削減や持続可能な資源管理により、環境への負荷が減少します。
PythonとAIの進展は、これらの分野でのイノベーションを促します。
まとめ
PythonとAIによるゴミ収集の最適化の重要性
Pythonと人工知能(AI)を活用して、ゴミ収集の効率化と最適化を実現する方法について詳しく解説しました。現代社会では、増加するゴミの量とその処理が大きな課題です。PythonとAIを組み合わせることで、この問題に対する革新的な解決策を提供できます。
- データ駆動型のアプローチ: ゴミの量を予測し、収集計画を最適化することで、効率的かつ環境に優しいゴミ収集が可能になります。
- コスト削減と環境への影響: 効率的な収集計画は、運用コストの削減と、CO2排出量の減少にも寄与します。
改善案と今後の展望
改善案
- リアルタイムデータの活用: ゴミ収集の現場からのリアルタイムデータをさらに積極的に取り入れることで、予測精度を向上させます。
- 市民参加型のアプローチ: 市民が自分たちの地域のゴミ量に関するデータを提供することで、より精度の高い予測と最適化が可能になります。
今後の展望
- 他分野への応用: この技術はゴミ収集だけでなく、都市計画、交通管理、環境保護など、さまざまな分野へ応用が可能です。
- スマートシティの実現: PythonとAIを活用したゴミ収集の最適化は、スマートシティ構想の実現に向けた一歩となります。
PythonとAIの可能性は広大で、今後も様々な分野での革新が期待されます。ゴミ収集の最適化は、生活の質の向上に貢献します。

▼AIを使った副業・起業アイデアを紹介♪

