
Pythonによるサンプルデータの生成
ここでは、衛星画像を模倣したサンプルデータを生成します。これは、海洋と陸地の異なる地域を表現するために、特定のパターンを持つデータを生成することを目的としています。
import numpy as np
import pandas as pd
# 1000x1000ピクセルのサンプル画像データを生成
size = 1000
land_threshold = 0.7 # この閾値より大きい値は陸地と見なす
data = np.random.rand(size, size)
# 画像データをDataFrameに変換
df = pd.DataFrame(data)データの可視化
次に、生成したデータを可視化してみましょう。これにより、陸地と海洋の領域がどのように分布しているかを視覚的に把握できます。
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
plt.imshow(df, cmap='ocean', interpolation='nearest')
plt.title('Simulated Satellite Image of Land and Ocean')
plt.colorbar(label='Value')
plt.show()
予測モデルの構築
新たな陸地を識別するために、ここではクラスタリングモデルを使用します。特に、K-meansクラスタリングを採用して、陸地と海洋の領域を分離します。
from sklearn.cluster import KMeans
# 2つのクラスタ(陸地と海洋)でK-meansクラスタリングを実行
kmeans = KMeans(n_clusters=2, random_state=0)
df_clustered = df.values.reshape(-1, 1)
kmeans.fit(df_clustered)
# クラスタラベルを元の形状に再配置
labels = kmeans.labels_.reshape(size, size)
# クラスタリング結果の可視化
plt.figure(figsize=(10, 10))
plt.imshow(labels, cmap='ocean', interpolation='nearest')
plt.title('Clustered Image: Land and Ocean')
plt.show()
サンプルコードと解説
以下のサンプルコードは、衛星データを用いて新たな陸地を探索するための基本的な手順を示しています。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# 仮想的な衛星データの生成
def generate_sample_satellite_data(num_points=1000):
# 二つの主な陸地を想定してデータを生成
land1 = np.random.randn(num_points, 2) + np.array([2, 2])
land2 = np.random.randn(num_points, 2) + np.array([-2, -2])
water = np.random.randn(num_points, 2) + np.array([0, 0])
data = np.vstack([land1, land2, water])
return data
data = generate_sample_satellite_data()
# KMeansクラスタリングの実行
kmeans = KMeans(n_clusters=3)
kmeans.fit(data)
labels = kmeans.predict(data)
# クラスタリング結果の可視化
plt.scatter(data[:, 0], data[:, 1], c=labels, cmap='viridis')
plt.title('Satellite Data Clustering')
plt.xlabel('Latitude')
plt.ylabel('Longitude')
plt.show()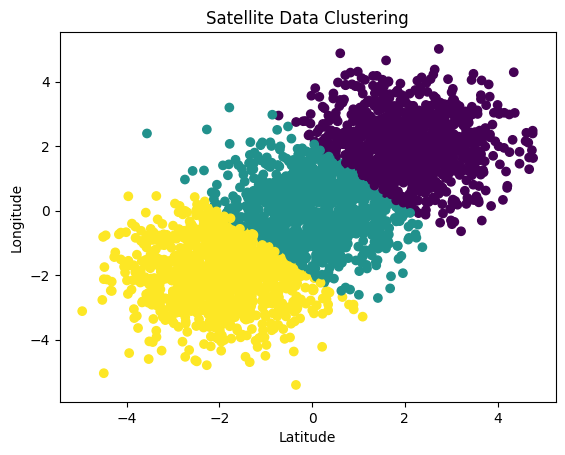
このコードでは、KMeansクラスタリングを用いて仮想的な衛星データを分析します。この分析により、様々な地形(この場合は陸地と水域)を識別できます。この手法は、新たな陸地の発見や地形の変化のモニタリングに利用できます。
K-meansクラスタリングを選択した理由
K-meansクラスタリングはシンプルで効果的な方法です。以下の理由からこのモデルを選択しました。
- 効率性: K-meansは計算コストが低く、大規模なデータにも適用可能です。
- 直感的な結果: クラスタリングにより、陸地と海洋の領域が明確に分離されます。
- 調整のしやすさ: クラスタ数(この場合は2)を調整することで、結果の精度をコントロールできます。
- 一般化のしやすさ: この手法は様々な種類の衛星データに適用可能です。
このアプローチにより、衛星データを分析して新たな陸地を効率的に識別できます。
ChatGPTとの連携
衛星データ分析において、PythonとChatGPTの連携は大きな可能性があります。
ChatGPTの役割
ChatGPTは、コード作成やデバッグにおいてアドバイスを提供できます。また、結果の解釈やさらなる分析のためのアイデアを提案できます。例えば、クラスタリングの結果に基づいて、特定の地域の詳細な分析を進めるアプローチを提案できます。
PythonとChatGPTを連携させることで、衛星データ分析の効率化と精度の向上を図ることができます。また、複雑なデータセットに対する洞察を深め、新たな発見へとつながります。
ビジネスへの応用
衛星データとPythonを用いた新たな陸地の発見は、多くのビジネスチャンスを生み出します。特に、不動産開発、環境保護、資源探査、そして気候変動研究において重要な役割を果たします。例えば、新たに発見された陸地における不動産開発や資源探査の機会が見出される可能性があります。また、環境保護の観点から、これらの陸地の生態系や気候への影響を評価することも重要です。
さらに、この技術は気候変動による地形の変化をモニタリングし、それに伴うリスク管理や対策立案にも利用されます。ビジネスにおいては、このようなデータを活用することで、リスクを最小限に抑えつつ新たな市場を開拓できます。また、公共事業や政策立案においても、重要な意思決定の支援ツールとして活用されるでしょう。

▼AIを使った副業・起業アイデアを紹介♪

