
AIエンジニアやプログラマーに転職して、新薬を開発し、年収アップをめざしましょう。
最近の研究によると、新薬Jemperli(dostarlimab-gxly)は局所進行直腸がんの患者42名全員の腫瘍を完全に消失させる驚異的な成果を上げています。
ここでは、AIを活用した新薬開発に必要なIT技術や具体的なPythonコードを解説します。AIエンジニアやプログラマーに転職したい方は、必見です。
また、この技術を応用したビジネスアイデアも紹介しますので、新しい視点や発想を得られますよ。
がん治療の革命 42名全員が完全治癒

新薬Jemperli(dostarlimab-gxly)は、第II相試験で局所進行直腸がんの42人全員の腫瘍を完全に消失させたそうです。
新薬Jemperliはミスマッチ修復欠損(dMMR)大腸がんにも効果を示しており、治療後平均26.3か月後もがんの再発が見られませんでした。
Jemperliは、化学療法や放射線治療を必要とせず、第一選択治療として有望です。昨年、FDAはこの薬を子宮内膜がんの補助治療として承認しました。
GSKは今後、他のタイプの大腸がんに対しても同様の研究を進める予定ということです。
AIで新薬開発:利用されるIT技術
42人全員の腫瘍が完全に消えたというのはすごいですね。
日本でも「光免疫療法」などに期待が集まっていますが、海外でも新しい治療法が開発されているようです。
AIで新薬開発に使用される主なIT技術は、下記のとおりです。
- プログラム言語:
Python:機械学習やデータ解析に広く使われている言語。豊富なライブラリ(TensorFlow、PyTorchなど)が新薬開発に役立つ。
R:統計解析やデータビジュアライゼーションに強みがある言語。 - AI技術:
機械学習(Machine Learning):大量のデータからパターンを学習し、新薬の効果や副作用を予測する技術。
深層学習(Deep Learning):特に画像解析や自然言語処理で活用され、新薬の分子構造解析や医学論文の解析に使用される。
自然言語処理(NLP):医学文献や患者データのテキスト解析に使用される。 - データベース技術:
SQLデータベース(MySQL、PostgreSQLなど):構造化データの管理と解析に使用される。
NoSQLデータベース(MongoDB、Cassandraなど):非構造化データや大量データの処理に適している。 - クラウド技術:
Amazon Web Services(AWS):データストレージ、計算リソース、AIサービスなどを提供。
Google Cloud Platform(GCP):機械学習モデルのトレーニングやデプロイに使用される。
Microsoft Azure:AIモデルの開発と運用に役立つサービスを提供。 - セキュリティ対策:
データ暗号化:患者データや研究データの保護に使用される。
アクセス制御:データへのアクセス権限を管理し、不正アクセスを防止する。
セキュリティ監査:システムの安全性を定期的にチェックし、脆弱性を発見・修正する。
各IT技術は、新薬開発において重要な役割を果たしています。
PythonとAIで新薬開発
PythonとAIで、新薬を開発するコードを書いてみましょう。
以下は、Pythonと機械学習で、新薬開発において有用なデータ分析と予測モデルを作成します。
サンプルコード
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
# Sample data creation
# Creating a synthetic dataset for drug effectiveness prediction
np.random.seed(42)
data_size = 100
data = {
'Feature1': np.random.normal(size=data_size),
'Feature2': np.random.normal(size=data_size),
'Feature3': np.random.normal(size=data_size),
'Effectiveness': np.random.choice([0, 1], size=data_size)
}
df = pd.DataFrame(data)
# Splitting the dataset into training and testing sets
X = df.drop('Effectiveness', axis=1)
y = df['Effectiveness']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Training a Random Forest Classifier
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
# Making predictions
y_pred = clf.predict(X_test)
# Evaluating the model
print("Classification Report:\n", classification_report(y_test, y_pred))
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))
# Plotting feature importances
feature_importances = clf.feature_importances_
features = X.columns
indices = np.argsort(feature_importances)
plt.figure(figsize=(10, 6))
plt.title('Feature Importances')
plt.barh(range(len(indices)), feature_importances[indices], align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()Classification Report:
precision recall f1-score support
0 0.70 0.54 0.61 13
1 0.40 0.57 0.47 7
accuracy 0.55 20
macro avg 0.55 0.55 0.54 20
weighted avg 0.59 0.55 0.56 20
Confusion Matrix:
[[7 6]
[3 4]]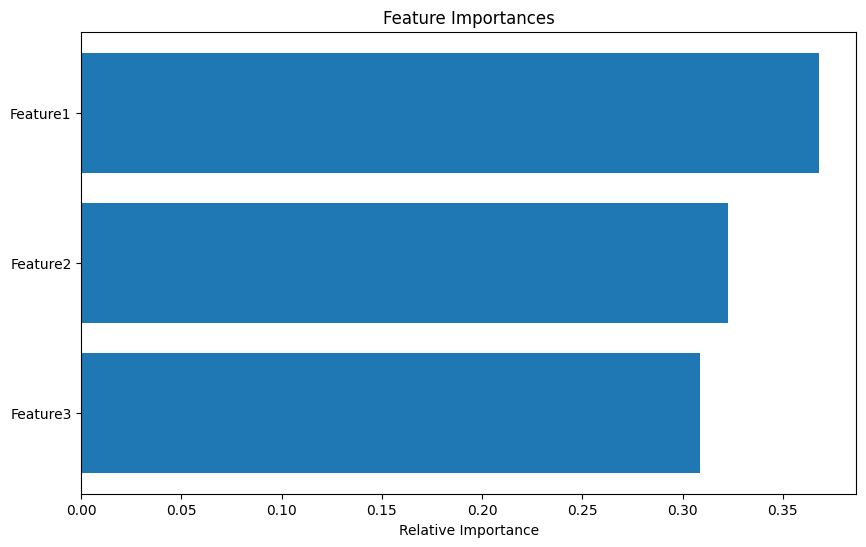
コード解説
- ライブラリのインポート:
必要なライブラリ(numpy、pandas、matplotlib、scikit-learn)をインポートします。 - サンプルデータの作成:
新薬の効果予測に使用する合成データを作成します。ここでは、100件のデータを生成し、3つの特徴量(Feature1, Feature2, Feature3)と効果(Effectiveness)を含めます。 - データセットの分割:
データセットをトレーニングセットとテストセットに分割します。ここでは、80%をトレーニングセット、20%をテストセットとしています。 - ランダムフォレスト分類器の訓練:
ランダムフォレスト分類器を使用してモデルを訓練します。訓練データを用いてモデルをフィットさせます。 - 予測の実行:
テストデータを用いて予測を行います。 - モデルの評価:
分類レポートと混同行列を表示して、モデルの性能を評価します。 - 特徴量の重要度のプロット:
各特徴量の重要度をプロットして視覚化します。特徴量の重要度は、モデルが予測にどの特徴量をどれだけ重要視したかを紹介します。
AIで新薬開発:応用アイデア
AIで新薬開発する技術の、応用アイデアを考えてみましょう。
同業種(医療・製薬業界)への応用アイデア
- 副作用予測:
新薬の開発段階で、副作用を予測し、事前にリスクを軽減するモデルを構築。 - 患者データ解析:
患者の遺伝子データや医療記録を解析し、個別化医療(Precision Medicine)を実現。 - 臨床試験の最適化:
AIを用いて臨床試験のデザインを最適化し、試験期間の短縮と成功率の向上を図る。 - 薬剤相互作用の検出:
複数の薬剤の相互作用を予測し、安全性を確保。
他業種への応用アイデア
- 金融業界:
リスク管理:投資リスクを予測し、ポートフォリオの最適化を行う。
不正検出:取引データを解析し、不正な取引を早期に検出。 - 製造業:
予知保全:機械の故障を予測し、メンテナンスを事前に計画する。
品質管理:生産ラインのデータを解析し、製品の品質向上を図る。 - 小売業:
需要予測:顧客の購買データを解析し、商品の需要を予測して在庫管理を最適化。
顧客分析:顧客の購買履歴を基に、個別化されたマーケティング戦略を立案。 - エネルギー業界:
スマートグリッド:電力消費データを解析し、エネルギー供給を最適化。
再生可能エネルギーの管理:天候データを解析し、太陽光や風力発電の効率を最大化。 - 物流業界:
ルート最適化:配送ルートをAIで最適化し、コスト削減と配送時間の短縮を実現。
在庫管理:需要予測を基に、最適な在庫レベルを維持。
AIで新薬開発する技術は、さまざまな分野に応用できそうですね。まさに、早い者勝ちのビジネスチャンスです。
AIで新薬開発:まとめ
AIで新薬開発する技術などについて解説しました。
新薬の開発に必要なIT技術や、具体的なPythonコードも紹介したので、AIエンジニアに転職を考えている人の参考になったと思います。
また、医療業界だけでなく、他の業界への応用アイデアも紹介しました。
あなたもAIエンジニアに転職して、画期的な新薬を開発しましょう。
これからの時代、病気を治すのは医者ではなく、AIエンジニアです。

▼AIを使った副業・起業アイデアを紹介♪

