
はじめに
サッカーは世界中でとても人気のあるスポーツです。特に国際試合やワールドカップなどの大会は、多くの人々の関心を引きつけます。その中でも、FIFAランキングは、各国のサッカーチームの実力を示す重要な指標として注目されています。
FIFAランキングとは
FIFAランキングは、国際サッカー連盟(FIFA)によって発表される、男女の国際Aマッチの結果に基づくサッカーの国際ランキングです。FIFAランキングは、各国のサッカーチームの過去の試合結果や得点などのデータを元に計算され、各チームの実力を数値化したものです。
本記事の目的
ここでは、日本のFIFAランキングの変遷データを元に、Pythonを使用して日本がFIFAランキングで1位になる日を予測する方法を解説します。具体的には、線形回帰という機械学習の手法を使用して、未来のランキングを予測します。
日本サッカーのFIFAランク1位予測のPythonコード
サッカーのFIFAランキングを予測するためには、まず必要なライブラリをインポートし、データの前処理を行い、モデルをトレーニングして予測する必要があります。以下では、これらのステップを解説します。
必要なライブラリのインポート
Pythonには、データ分析や機械学習を行うための多くのライブラリが存在します。今回の予測モデルの作成には、numpyとsklearn.linear_modelのLinearRegressionを使用します。
import numpy as np
from sklearn.linear_model import LinearRegressionnumpyは、数値計算を効率的に行うためのライブラリであり、LinearRegressionは、線形回帰モデルを実装するためのクラスです。
データの作成
日本代表 FIFAランキング(引用元:FIFA公式ページ)
| ▼日本代表 FIFAランキング | |||
| 日付 | 順位 | point | 国名 |
| 1993年 12月 | 43位 | 36pts | 日本 |
| 1994年 12月 | 36位 | 40pts | 日本 |
| 1995年 12月 | 31位 | 45pts | 日本 |
| 1996年 12月 | 21位 | 53pts | 日本 |
| 1997年 12月 | 14位 | 57pts | 日本 |
| 1998年 12月 | 20位 | 55pts | 日本 |
| 1999年 12月 | 57位 | 501pts | 日本 |
| 2000年 12月 | 38位 | 584pts | 日本 |
| 2001年 12月 | 34位 | 626pts | 日本 |
| 2002年 12月 | 22位 | 650pts | 日本 |
| 2003年 12月 | 29位 | 646pts | 日本 |
| 2004年 12月 | 17位 | 707pts | 日本 |
| 2005年 12月 | 15位 | 715pts | 日本 |
| 2006年 12月 | 47位 | 640pts | 日本 |
| 2007年 12月 | 34位 | 748pts | 日本 |
| 2008年 12月 | 35位 | 734pts | 日本 |
| 2009年 12月 | 43位 | 709pts | 日本 |
| 2011年 12月 | 19位 | 884pts | 日本 |
| 2012年 11月 | 24位 | 810pts | 日本 |
| 2013年 12月 | 47位 | 638pts | 日本 |
| 2014年 12月 | 54位 | 563pts | 日本 |
| 2015年 12月 | 53位 | 607pts | 日本 |
| 2016年 12月 | 45位 | 644pts | 日本 |
| 2017年 12月 | 57位 | 600pts | 日本 |
| 2018年 12月 | 50位 | 1414pts | 日本 |
| 2019年 12月 | 28位 | 1503pts | 日本 |
| 2020年 12月 | 27位 | 1502pts | 日本 |
| 2021年 12月 | 26位 | 1531.53pts | 日本 |
| 2022年 10月 | 24位 | 1559.54pts | 日本 |
| 2023年 9月 | 19位 | 1605.2pts | 日本 |
日本のFIFAランキングの変遷データをPythonのリストとして定義します。このデータには、年、ランキング、ポイントが含まれています。
# Sample Data: Japan FIFA Ranking from 1993 to 2023
years = [
1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000,
2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008,
2009, 2011, 2012, 2013, 2014, 2015, 2016, 2017,
2018, 2019, 2020, 2021, 2022, 2023
]
rankings = [
43, 36, 31, 21, 14, 20, 57, 38, 34, 22, 29, 17,
15, 47, 34, 35, 43, 19, 24, 47, 54, 53, 45, 57,
50, 28, 27, 26, 24, 19
]
points = [
36, 40, 45, 53, 57, 55, 501, 584, 626, 650, 646, 707,
715, 640, 748, 734, 709, 884, 810, 638, 563, 607, 644, 600,
1414, 1503, 1502, 1531.53, 1559.54, 1605.2
]このデータをグラフにプロットすることで、日本のランキングやポイントの変動を視覚的に確認できます。以下のコードは、そのためのサンプルコードです。
# Sample Python Code to Plot the Data
import matplotlib.pyplot as plt
fig, ax1 = plt.subplots()
color = 'tab:red'
ax1.set_xlabel('Year')
ax1.set_ylabel('Ranking', color=color)
ax1.plot(years, rankings, color=color, label='Ranking', linewidth=2.5)
ax1.tick_params(axis='y', labelcolor=color)
ax1.invert_yaxis() # Lower rank numbers are better
ax2 = ax1.twinx()
color = 'tab:blue'
ax2.set_ylabel('Points', color=color)
ax2.plot(years, points, color=color, label='Points')
ax2.tick_params(axis='y', labelcolor=color)
fig.tight_layout()
plt.title('Japan FIFA Ranking and Points (1993-2023)')
plt.show()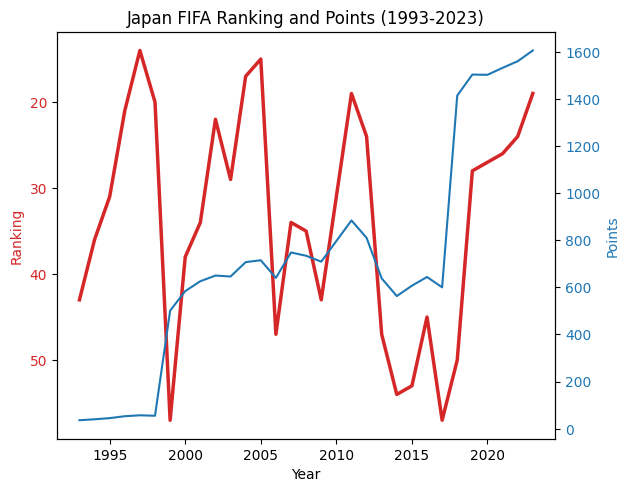
線形回帰を用いた予測モデルの実装
次に、線形回帰モデルを用いて日本のFIFAランキングのポイントを予測します。線形回帰は、与えられたデータに基づいて最もよくデータを説明する直線を見つける手法です。
まず、データを線形回帰モデルに適した形に整形します。そして、モデルをトレーニングし、未来のポイントを予測します。
import matplotlib.pyplot as plt
# 1位になる年までのデータをトリミング
index_1st_rank = np.argmax(predicted_points > max(points))
trimmed_future_years = future_years[:index_1st_rank+1]
trimmed_predicted_points = predicted_points[:index_1st_rank+1]
fig, ax1 = plt.subplots()
color = 'tab:red'
ax1.set_xlabel('Year')
ax1.set_ylabel('Ranking', color=color)
ax1.plot(years, rankings, color=color, label='Ranking', linewidth=2.5)
ax1.tick_params(axis='y', labelcolor=color)
ax1.invert_yaxis() # Lower rank numbers are better
ax2 = ax1.twinx()
color = 'tab:blue'
ax2.set_ylabel('Points', color=color)
ax2.plot(years, points, color=color, label='Actual Points')
ax2.plot(trimmed_future_years, trimmed_predicted_points, color=color, linestyle='--', label='Predicted Points')
ax2.tick_params(axis='y', labelcolor=color)
ax2.legend(loc='upper left')
# 1位になるときの予測されたポイント数を表示
predicted_1st_rank_points = predicted_points[index_1st_rank]
ax2.scatter(year_1st_rank, predicted_1st_rank_points, color='green', label='Predicted 1st Rank Points')
ax2.text(year_1st_rank, predicted_1st_rank_points, f'{predicted_1st_rank_points:.2f}', fontsize=9, verticalalignment='bottom')
fig.tight_layout()
plt.title(f'Japan FIFA Ranking and Points (1993-{year_1st_rank})')
plt.show()
year_1st_rank, predicted_1st_rank_points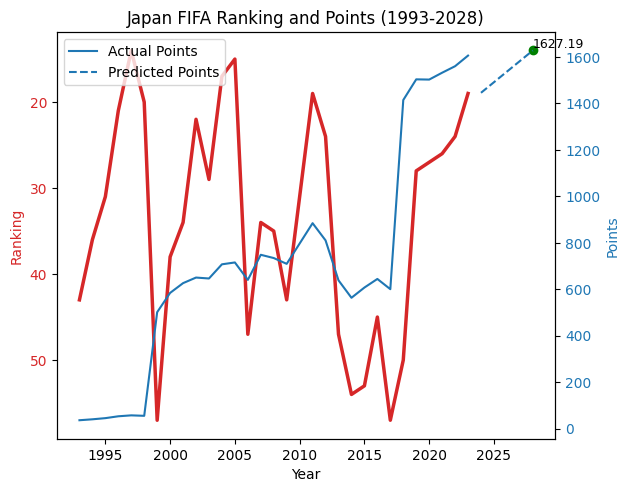
(2028, 1627.189862405081)このコードにより、日本がFIFAランキングで1位になると予測される年がyear_1st_rankに、その時のポイント数がpredicted_1st_rank_points格納されます。
AIは、2028年(ポイント1627.19)に日本がFIFAランキングで1位になると予想しています。
このように、Pythonを使用してデータの前処理、モデルのトレーニング、予測を行うプロセスはとてもシンプルです。次では、このモデルの詳細と、どのようにして予測が行われるのかを解説します。
線形回帰モデルの解説
線形回帰の選択理由
線形回帰は、データ分析で最も基本的かつ広く利用される手法の一つです。目的変数と説明変数の間の関係を直線的な関数でモデル化します。数式で表現すると、以下のようになります。
\[
y = \beta_0 + \beta_1 x + \epsilon
\]
ここで、
- \( y \) : 目的変数(予測したい変数、この場合はポイント)
- \( x \) : 説明変数(予測に使用する変数、この場合は年)
- \( \beta_0, \beta_1 \) : モデルのパラメータ
- \( \epsilon \) : 誤差項
「日本サッカーがFIFAランク1位になる日の予測」に線形回帰を選択した理由は以下の通りです。
- シンプルさ: 線形回帰は理解しやすく、結果の解釈も直感的です。
- 入門者向け: 線形回帰は機械学習の入門としてとても適しています。
- データのトレンド: 日本のFIFAランキングとポイントのデータを見ると、直線的なトレンドが確認できます。
モデルの説明
線形回帰モデルの構築は以下のステップで行われます。
- データの準備: まず、使用するデータを適切な形式に整形します。この場合、年を説明変数として、ポイントを目的変数として使用します。
X = np.array(years).reshape(-1, 1)
y = np.array(points)- モデルのトレーニング: sklearnのLinearRegressionクラスを使用して、データをもとにモデルをトレーニングします。
model = LinearRegression().fit(X, y)- 未来のポイントの予測: トレーニングしたモデルを使用して、未来のポイントを予測します。
future_years = np.array(list(range(2024, 2100))).reshape(-1, 1)
predicted_points = model.predict(future_years)- 1位になる年の予測: 予測されたポイントをもとに、日本が1位になる可能性のある年を予測します。
year_1st_rank = future_years[np.argmax(predicted_points > max(points))][0]この手法は、データのトレンドが将来も継続するという仮定に基づいています。しかし、実際のスポーツは多くの要因に影響を受けるため、この予測は参考の一つとして考えてください。
まとめ
FIFAランク1位予測の振り返り
日本サッカーがFIFAランク1位になる日を予測する方法について、Pythonと線形回帰を使用して説明しました。具体的には、過去のランキングとポイントのデータを使用して未来のポイントを予測し、それを基に1位になるであろう年を特定しました。しかし、このアプローチは単純な線形回帰に依存しているため、実際のスポーツで変動や他の要因を考慮していない点に注意してください。
今後の展望
サッカーは日々進化しており、AIとデータ分析の役割も増えています。今後は以下の点が期待されます。
- 高度なモデリング: 線形回帰だけでなく、より複雑なモデルや深層学習を使用して、より正確な予測を行う。
- リアルタイム分析: リアルタイムでの試合データの取得と分析により、戦略を即座に変更する。
- 選手の健康とパフォーマンスの最適化: 選手のフィジカルデータや健康情報を使用して、最適なトレーニングや休息を提案する。
サッカーとAIの組み合わせは、スポーツ界だけでなくビジネスの領域にも拡大していくでしょう。

▼AIを使った副業・起業アイデアを紹介♪

