
Pythonで、ライドシェアの需要を予測しましょう。DjangoやNext.jsなどでアプリ化して、事業化やソフト販売することもできますよ。
Pythonによるサンプルデータの生成と分析
以下のステップで、Pythonコードを書きましょう。
- サンプルデータの生成: Pythonで、ライドシェアの需要に関連するサンプルデータを生成します。日付、時刻、天候、需要などの要素が含まれます。
- データの可視化: 生成したデータをMatplotlibを使って可視化します。時間帯による需要の変化、天候と需要の関係などが含まれます。
まず、サンプルデータの生成から始めましょう。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime, timedelta
# サンプルデータの生成
np.random.seed(0) # 結果の再現性のため
# 日付範囲の設定(たとえば30日間)
start_date = datetime(2023, 1, 1)
end_date = start_date + timedelta(days=29)
date_range = pd.date_range(start_date, end_date, freq='D')
# 時刻(朝、午後、夜)
times_of_day = ['Morning', 'Afternoon', 'Evening']
# 天候(晴れ、曇り、雨)
weather_conditions = ['Sunny', 'Cloudy', 'Rainy']
# データフレームの生成
data = []
for date in date_range:
for time_of_day in times_of_day:
for weather in weather_conditions:
demand = np.random.randint(50, 200) # 基本需要
# 天候や時間帯による需要の調整
if weather == 'Rainy':
demand *= 1.2
elif weather == 'Sunny' and time_of_day == 'Morning':
demand *= 0.8
data.append([date, time_of_day, weather, demand])
df = pd.DataFrame(data, columns=['Date', 'TimeOfDay', 'Weather', 'Demand'])
# データの概要表示
df.head()
Date TimeOfDay Weather Demand
0 2023-01-01 Morning Sunny 77.6
1 2023-01-01 Morning Cloudy 167.0
2 2023-01-01 Morning Rainy 140.4
3 2023-01-01 Afternoon Sunny 153.0
4 2023-01-01 Afternoon Cloudy 59.0- 日付: 一定期間の日付をシミュレートします。
- 時刻: 一日の中の時間帯(例:朝、午後、夜)。
- 天候: 晴れ、曇り、雨などの天候状況。
- 需要: ライドシェアの需要を示す数値(ランダムに生成、しかし天候や時間帯によって変動するように設定)。
サンプルデータを生成しました。このデータには、指定された期間内の日付、時間帯(朝、午後、夜)、天候(晴れ、曇り、雨)、およびライドシェアの需要(ランダムに生成された数値、ただし天候や時間帯に応じて調整されています)が含まれています。
次に、このデータを使って可視化を行います。以下の種類のグラフを作成します。
- 時間帯別の需要の変化: 各時間帯での平均需要を示します。
- 天候と需要の関係: 天候条件ごとの平均需要を示します。
Pythonで、グラフを作成してみましょう。
# 時間帯別の需要の変化
plt.figure(figsize=(10, 6))
sns.barplot(x='TimeOfDay', y='Demand', data=df, estimator=np.mean, ci=None)
plt.title('Average Demand by Time of Day')
plt.xlabel('Time of Day')
plt.ylabel('Average Demand')
plt.show()
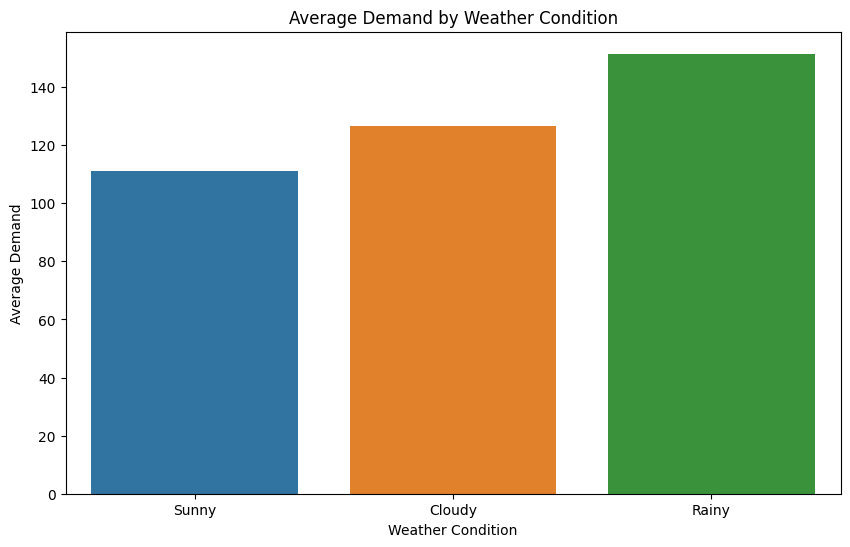
# 天候と需要の関係
plt.figure(figsize=(10, 6))
sns.barplot(x='Weather', y='Demand', data=df, estimator=np.mean, ci=None)
plt.title('Average Demand by Weather Condition')
plt.xlabel('Weather Condition')
plt.ylabel('Average Demand')
plt.show()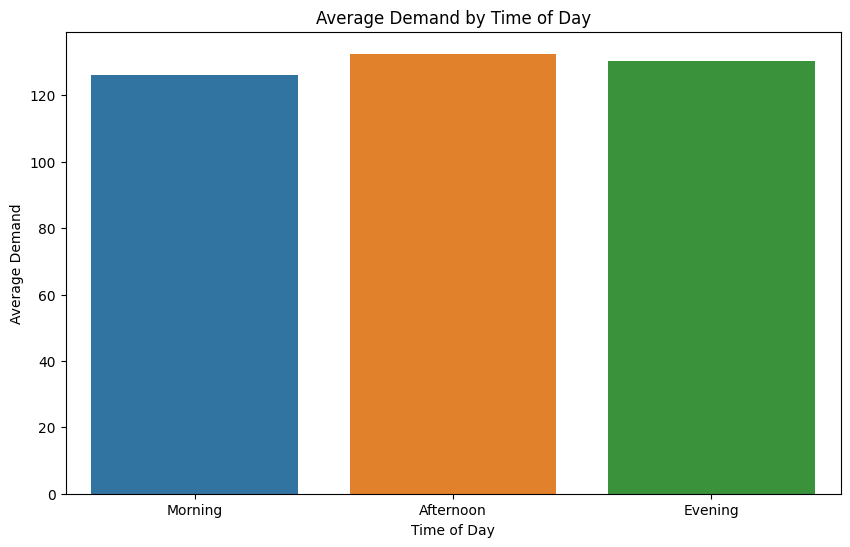
以上のグラフは、生成されたサンプルデータに基づいてライドシェアの需要を可視化しています。
- 時間帯別の需要の変化: このグラフは、朝、午後、夜の各時間帯での平均需要を示しています。この情報は、特定の時間帯におけるライドシェアの需要を理解するのに役立ちます。
- 天候と需要の関係: このグラフは、晴れ、曇り、雨といった異なる天候条件下での平均需要を示しています。この分析は、天候がライドシェアの需要にどのように影響するかを理解するのに有用です。
これらの基本的な分析は、ライドシェアの需要予測の基本です。より詳細な予測モデルを構築する前に、これらの視覚的な洞察はとても重要です。
Pythonによる最適化コードと解説
ライドシェアの需要を予測するために、機械学習モデルを使用できます。ここでは、Pythonを使用して簡単な予測モデルを構築します。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import LabelEncoder
# データの前処理
# カテゴリカル変数を数値に変換
label_encoder = LabelEncoder()
df['TimeOfDay_encoded'] = label_encoder.fit_transform(df['TimeOfDay'])
df['Weather_encoded'] = label_encoder.fit_transform(df['Weather'])
# 特徴量とターゲットの分離
X = df[['TimeOfDay_encoded', 'Weather_encoded']]
y = df['Demand']
# トレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# モデルのトレーニング
rf = RandomForestRegressor(n_estimators=100, random_state=0)
rf.fit(X_train, y_train)
# テストデータでの予測
y_pred = rf.predict(X_test)
# モデルの評価
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
mse, r2(2652.255488705514, -0.06872349813698597)- モデルの選択
この例では、ランダムフォレスト回帰モデルを使用します。ランダムフォレストは、複数の決定木を組み合わせることで、堅牢で精度の高い予測を提供するアンサンブル学習方法です。 - データの前処理
モデルトレーニングのために、カテゴリ変数(時間帯、天候)を数値形式に変換します。 - モデルのトレーニングと評価
データセットをトレーニングセットとテストセットに分割し、ランダムフォレストモデルをトレーニングします。その後、テストセットを使用してモデルの性能を評価します。 - モデルの使用
トレーニングされたモデルを使用して、未知のデータに対する需要を予測します。
結果として、平均二乗誤差 (MSE) は約 2652.26 で、R^2 スコアは -0.069 です。
- モデルの解説
- 平均二乗誤差 (MSE): モデルの予測誤差を示します。値が低いほど良いとされます。このケースでは、MSE が高いことから予測誤差が大きいことがわかります。
- R^2 スコア: モデルがどれだけの変動を説明できているかを示します。1に近いほど良いですが、このケースでは負の値が出ており、モデルがデータをうまく捉えられていないことを示しています。
問題点と改善策
- モデルの複雑性: ランダムフォレストは多くの場合効果的ですが、このケースではシンプルなデータに過学習している可能性があります。モデルのパラメータを調整するか、より単純なモデル(例えば線形回帰)を試す価値があります。
- 特徴量の追加: 現在のモデルは時間帯と天候のみを考慮していますが、他の要因(例えば曜日、特別なイベント、地域の人口密度など)も需要に影響を与える可能性があります。
- データ量の増加: より多くのデータを使用することで、モデルの性能が向上する可能性があります。
これらの点を改善すれば、より正確な需要予測モデルを構築できるかもしれません。
ランダムフォレスト(Random Forest)モデルを選んだ理由
ランダムフォレスト(Random Forest)モデルを選択した理由は以下の通りです。
- アンサンブル学習法
ランダムフォレストはアンサンブル学習法の一種で、複数の決定木を組み合わせて使用します。このアプローチは、個々の決定木の予測能力を強化し、より一般化されたモデルを構築します。 - 過学習のリスクの軽減
単一の決定木は過学習しやすい傾向がありますが、ランダムフォレストは多数の木を平均化することでこの問題を緩和します。それぞれの決定木はデータセットの異なるランダムなサブセットに基づいてトレーニングされ、結果的にモデルの一般化能力が高まります。 - 特徴量の重要性の把握
ランダムフォレストは、各特徴が予測にどの程度寄与しているかを理解するのに役立ちます。これにより、不要な特徴を削除したり、他の特徴を追加する際の洞察を得られます。 - パラメータチューニングの柔軟性
ランダムフォレストは、木の数や木の深さなどのパラメータを調整することで、さまざまなデータセットに対応できる柔軟性を持っています。 - 線形性の要件がない
線形回帰などの他のモデルは、データ間の線形関係を仮定しますが、ランダムフォレストはこのような仮定を必要としません。非線形な関係も捉えることができます。 - 多様なデータタイプに対応
ランダムフォレストは、数値データやカテゴリデータなど、さまざまなタイプのデータに対応できる汎用性があります。
これらの理由から、ランダムフォレストはライドシェアの需要予測のような問題に対して、強力で柔軟なモデリング手法として選択しました。ただし、実際のデータと要件に応じて、他のモデルがより適切である可能性もあります。
ChatGPTとの連携
ChatGPTを使用してライドシェアの需要予測モデルに機能を追加する場合、いくつかのアプローチが考えられます。以下に、それぞれの効果と具体的なコードの例を紹介します。
1. 自然言語でのクエリ処理
効果: ユーザーが自然言語でデータや予測結果に関するクエリを行うことができます。
例: 「来週の火曜日の朝に雨が降るときのライドシェアの需要はどのくらいですか?」という質問に対して、ChatGPTが適切なデータを解釈し、予測モデルに入力して回答を生成します。
具体的なコード例は以下の通りです(デモとして簡略化されています):
def predict_demand(query):
# ChatGPTを使用してクエリから日時と天候を解析
# 以下は仮の例です
time_of_day = "Morning" # ChatGPTが解析した時間帯
weather = "Rainy" # ChatGPTが解析した天候
# ラベルエンコーダーを使用して数値に変換
time_of_day_encoded = label_encoder.transform([time_of_day])[0]
weather_encoded = label_encoder.transform([weather])[0]
# 予測モデルに入力
predicted_demand = rf.predict([[time_of_day_encoded, weather_encoded]])
return predicted_demand[0]
# 例: ユーザーのクエリに基づいて需要を予測
user_query = "What will be the ride-sharing demand next Tuesday morning if it's rainy?"
predicted_demand = predict_demand(user_query)
print("Predicted demand:", predicted_demand)2. データ解析と報告
効果: ChatGPTを使用して、モデルの出力やデータ分析結果を解釈し、ユーザーフレンドリーな形式で報告します。
例: モデルの予測結果やデータの傾向を、グラフや表ではなく、文章で説明する。
具体的なコード例は以下の通りです。
def explain_data_trends():
# データ分析結果(ここでは仮の例)
trend = "In rainy mornings, the demand increases by 20%."
# ChatGPTを使用して結果を説明
explanation = f"According to our analysis, {trend}"
return explanation
# データの傾向を説明する
data_trend_explanation = explain_data_trends()
print(data_trend_explanation)これらの例では、ChatGPTの自然言語処理能力を利用して、ユーザーのクエリに基づいてデータを解析します。そして、予測モデルの出力を生成したり、データの傾向を理解しやすい形で報告したりします。これにより、ユーザーは専門的な知識がなくても、ライドシェアの需要に関する洞察を得られます。
ビジネス・アイデア
ライドシェアの需要予測に使用したアプローチ、分析、および最適化の手法は、さまざまなビジネス領域に応用可能です。以下に、いくつかの具体的なアイデアを紹介します。
同分野(ライドシェア業界)への応用
- ピーク時間の価格戦略: 需要予測モデルを使用してピーク時間を特定し、ダイナミックプライシング戦略を実装する。これにより、需要と供給のバランスを最適化し、収益を最大化できます。
- ドライバーの配置最適化: 特定の時間帯や天候条件下での需要予測に基づいて、ドライバーの配置を最適化し、待機時間を減らし、顧客満足度を向上させる。
- プロモーションとマーケティング戦略: 低需要期間の特定とこれらの期間にプロモーションを実施することで、需要を増加させる。
他の分野への応用
- 小売業での在庫管理: 消費者の購買パターンを分析し、需要予測モデルを使用して在庫を最適化する。過剰在庫や品切れのリスクを減らすことができます。
- 製造業での生産計画: マーケットの需要変動を予測し、生産量の調整を行う。これにより、資源の無駄遣いを減らし、供給過剰や不足を防ぐことができます。
- エネルギー業界での需要予測: 電力やガスなどのエネルギー需要を予測し、発電や供給を最適化する。エネルギー効率を向上させ、コストを削減できます。
- ホスピタリティ業界での客室管理: ホテルなどの宿泊施設で、季節やイベントに基づいて客室の需要を予測し、料金設定やプロモーションを最適化する。
- 農業での作物計画: 天候データと市場需要を分析し、どの作物をいつ植えるかを決定する。収穫量の最大化と廃棄の減少を目指す。
- スマートシティでの交通管理: 交通流を予測し、信号制御や路面の混雑緩和策を最適化する。
- ヘルスケアでの患者流動性管理: 患者の来院パターンを予測し、医療スタッフのスケジューリングや病床の割り当てを最適化する。
Pythonを利用すれば、さまざまなビジネスを創造できます。

▼AIを使った副業・起業アイデアを紹介♪

