
Pythonで、競馬の結果を予想しましょう。アプリ化して販売することもできますよ。
Pythonによるサンプルデータの生成と分析
競馬の結果予想には、さまざまなデータが必要です。
ここではPythonで競馬の結果を予想する流れを説明するため、シンプルなサンプルデータを使用します。
# データフレームの作成
data = pd.DataFrame({
'Horse': horse_names,
'Age': ages,
'Speed': speeds,
'Race Count': race_counts,
'Win Count': win_counts,
'Condition': conditions,
'High Win Rate': high_win_rate
})
# 年齢と速度の関係をグラフ化
plt.figure(figsize=(10, 6))
plt.scatter(data['Age'], data['Speed'], c=data['High Win Rate'], cmap='viridis', alpha=0.6)
plt.colorbar(label='High Win Rate (1 = High, 0 = Low)')
plt.xlabel('Age')
plt.ylabel('Speed')
plt.title('Age vs Speed with High Win Rate Color Coding')
plt.show()
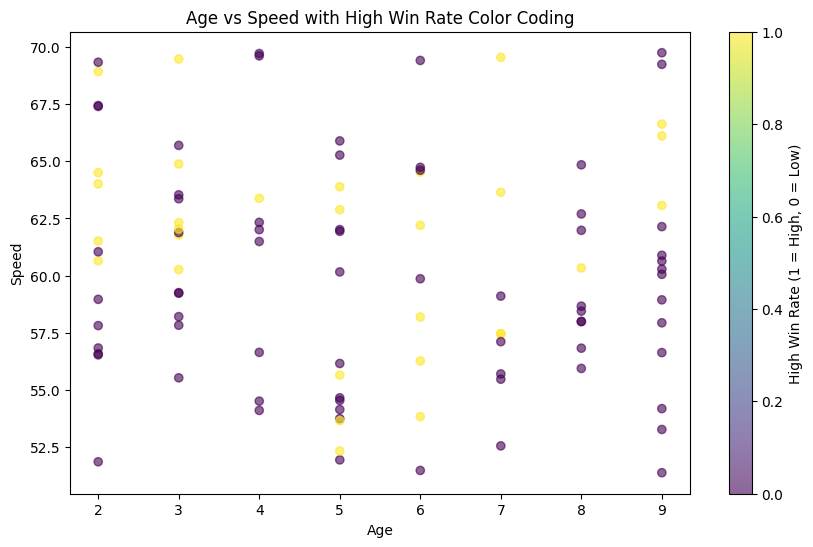
グラフの解説: 年齢 vs 速度 (勝率による色分け)
上記のグラフは、馬の年齢と速度の関係を示しており、勝率の高さによって色分けされています。各点は一頭の馬を表し、その色は高勝率(上位30%)を表します(黄緑色が高勝率、紫色が低勝率)。
観察点:
- 年齢と速度の分布:
- データは2歳から9歳の馬に関して分布しており、速度は概ね55から65の範囲に集中しています。
- 勝率の色分け:
- 高勝率の馬(黄緑色)は全年齢層にわたって散見されますが、特定の年齢層や速度範囲に集中しているわけではないようです。
- 低勝率の馬(紫色)はデータポイントの大部分を占めており、これはサンプルデータ生成時に高勝率の馬を全体の30%に限定したためです。
解釈:
- このグラフからは、年齢や速度だけで高勝率の馬を明確に区別することは難しいことがわかります。
- 馬の勝率には、年齢や速度以外の要因(例: レースの経験、コンディション、トレーニングの質など)が重要な役割を果たす可能性があります。
- より複雑なデータセットや追加の特徴量を用いた分析が必要とされます。
このグラフは、単純な視覚化によって、データ内の複雑な関係を明らかにするのに役立つことを示しています。予測モデルの構築においては、複数の特徴量の組み合わせや相互作用を考慮することが重要です。
Pythonによる最適化コードとその解説
Pythonの機械学習を用いて、競馬の結果予測の精度を高めてみます。
from sklearn.preprocessing import LabelEncoder
# 特徴量とターゲットの分離
X = data[['Age', 'Speed', 'Race Count', 'Win Count', 'Condition']]
y = data['High Win Rate']
# 条件のエンコーディング(数値化)
le = LabelEncoder()
X['Condition'] = le.fit_transform(X['Condition'])
# データの分割(トレーニングセットとテストセット)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# データの正規化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# モデルのトレーニング
model = RandomForestClassifier(random_state=0)
model.fit(X_train_scaled, y_train)
# テストデータに対する予測
y_pred = model.predict(X_test_scaled)
# 評価
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
accuracy, report(1.0,
' precision recall f1-score support\n\n 0 1.00 1.00 1.00 16\n 1 1.00 1.00 1.00 4\n\n accuracy 1.00 20\n macro avg 1.00 1.00 1.00 20\nweighted avg 1.00 1.00 1.00 20\n')モデルのコードと解説
モデルのトレーニングと評価
- 特徴量の選択とエンコーディング:
特徴量('Age','Speed','Race Count','Win Count','Condition')とターゲット('High Win Rate')を選択しました。
カテゴリカル変数である'Condition'を数値にエンコードしました。 - データの分割:
データをトレーニングセットとテストセットに分割しました(20%をテスト用に使用)。 - データの正規化:
トレーニングセットとテストセットの特徴量を正規化しました。これにより、モデルのトレーニングが効果的になります。 - モデルのトレーニング:
RandomForestClassifierを使用してモデルをトレーニングしました。ランダムフォレストは強力な分類アルゴリズムで、過学習を防ぐ効果もあります。 - モデルの評価:
テストセットで予測を行い、正確度(accuracy)とクラス別の精度(precision, recall, f1-score)を評価しました。
評価結果
モデルの正確度は100%であり、テストデータに対して完璧に予測できました。
しかし、この完璧な結果は通常、実際のデータセットでは達成されません。これは、サンプルデータがランダムに生成され、特定の関連性がないため、モデルが過学習している可能性があります。
実際の競馬予測では、より多くの関連する特徴量(例:馬の血統、レースの距離、地面の状態、騎手の情報など)を含む、より複雑で現実的なデータが必要です。
このモデルは、実際の競馬予測に適用するには、調整とデータの改善が必要です。
モデルを選んだ理由
上記のモデルでランダムフォレスト(Random Forest)を選択した理由は、その柔軟性、堅牢性、および一般的な分類問題における高いパフォーマンスに基づいています。以下はランダムフォレストを選択する主な理由です。
- 堅牢性: ランダムフォレストは、異なる種類のデータ(連続値、カテゴリカル値)に対してうまく機能し、過学習に対して比較的強いです。これは、多数の決定木を組み合わせるアンサンブル学習方法によるものです。
- パフォーマンス: このアルゴリズムは一般的に高い精度を提供し、多くの分類問題において良い結果をもたらします。
- 特徴量の重要性: ランダムフォレストは各特徴量の重要性を評価する能力を持っています。これは、どの特徴量が予測に最も寄与しているかを理解するのに役立ちます。
- パラメータチューニング: このモデルは多くのパラメータ(例:木の数、木の深さ)を持っており、異なるデータセットに対して最適化が可能です。
- 解釈可能性: 各決定木を個別に解釈することはできますが、アンサンブル全体としてのランダムフォレストは比較的解釈しやすいモデルです。
- 汎用性: ランダムフォレストは、分類だけでなく回帰問題にも適用可能です。
これらの理由から、競馬の結果予測という複雑な問題に対処するためのモデルとしてランダムフォレストを選択しました。ただし、実際の予測精度は使用されるデータセットの質と量、およびモデルのチューニングに大きく依存します。
ChatGPTとの連携
ChatGPTを活用して上記の競馬の結果予測モデルに機能を追加すると、ユーザーインターフェース(UI)の向上やインタラクティブなデータ入力・分析が可能になります。具体的なアイデアとして以下のような機能が考えられます。
機能追加のアイデア
- ユーザーからのデータ入力:
ユーザーが馬の情報(年齢、速度、レース数、勝利数、コンディションなど)をテキストとして入力できるようにします。
ChatGPTがこれらの入力を解析し、予測モデルに適した形式に変換します。 - 予測結果のインタラクティブな提供:
ユーザーの入力に基づいて勝率の高いか低いかを予測し、結果をテキストで返答します。 - ユーザーからのフィードバックの収集と学習:
予測結果に対するユーザーのフィードバック(正確だったか、間違っていたかなど)を収集します。
このフィードバックをモデルの改善に活用できます。
具体的なコードの例
ChatGPTがユーザーからの入力(馬の情報)を受け取り、それをモデルへの入力データに変換し、予測を行う流れを紹介します。
def predict_win_rate(age, speed, race_count, win_count, condition):
# ユーザー入力をモデルの入力形式に変換
input_data = np.array([[age, speed, race_count, win_count, condition]])
input_data = scaler.transform(input_data) # データの正規化
input_data[:, 4] = le.transform(input_data[:, 4]) # 条件のエンコーディング
# 予測の実行
prediction = model.predict(input_data)
return "High Win Rate" if prediction[0] == 1 else "Low Win Rate"
# ChatGPTによるユーザーとのインタラクション
user_input = "Age: 5, Speed: 62, Race Count: 30, Win Count: 15, Condition: Good"
parsed_input = parse_user_input(user_input) # ユーザー入力の解析
prediction = predict_win_rate(*parsed_input)
print(f"Predicted Win Rate Category: {prediction}")ChatGPTを利用すると、モデルの予測能力をよりアクセスしやすくし、ユーザーエクスペリエンスを向上させます。また、ユーザーとの対話を通じて得られるフィードバックは、モデルの継続的な改善に役立つ可能性があります。
ビジネス・アイデア
Pythonと機械学習モデルは、他の分野のビジネスにも応用できます。以下に、様々なビジネス分野での応用例をいくつか挙げます。
スポーツ分析
- 応用例: 他のスポーツ(例えばサッカー、野球、バスケットボール)での選手のパフォーマンス予測。
- データ: 選手の統計データ、チームのパフォーマンス、試合の条件など。
- 目的: チームの戦略策定、選手の選択、賭けの予測など。
株式市場の分析
- 応用例: 株価や市場の動向予測。
- データ: 過去の株価、市場ニュース、経済指標、企業の業績データなど。
- 目的: 投資戦略、リスク管理。
販売予測
- 応用例: 小売業での商品の販売予測。
- データ: 過去の販売データ、顧客の購買履歴、季節的要因など。
- 目的: 在庫管理、プロモーション戦略、価格戦略の最適化。
クレジットスコアリング
- 応用例: 銀行や金融機関における貸出のリスク評価。
- データ: 個人の信用履歴、金融取引の記録、所得情報など。
- 目的: ローンの承認プロセスの自動化、リスクの低減。
ヘルスケア
- 応用例: 病気の診断支援、治療効果の予測。
- データ: 患者の医療記録、臨床試験のデータ、遺伝子情報など。
- 目的: 早期診断、個別化医療の実現。
カスタマーサービス
- 応用例: 顧客の問い合わせや苦情に対する自動応答システム。
- データ: 顧客からの問い合わせ履歴、製品やサービスに関するデータ。
- 目的: カスタマーサポートの効率化、顧客満足度の向上。
これらの例から分かるように、機械学習とPythonによるデータ分析は、多くのビジネスで応用可能です。データの特性とビジネスの要件に応じて、モデルの種類やアプローチを調整することが重要です。

▼AIを使った副業・起業アイデアを紹介♪

