
Pythonで、収益の上がる不動産を予測しましょう。
Pythonによるサンプルデータの生成と分析
下記のPythonコードでは、不動産の収益性に関連するサンプルデータを生成し、それらを可視化しています。これにより、不動産のサイズ、立地の質、築年数が賃貸収入にどのように影響を与えるかを理解できます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# サンプルデータの生成
np.random.seed(0)
n_properties = 100
size = np.random.uniform(50, 200, n_properties) # 面積(平方メートル)
location_quality = np.random.choice(['Low', 'Medium', 'High'], n_properties) # 立地の質
age = np.random.randint(0, 50, n_properties) # 築年数(年)
rental_income = size * np.random.uniform(20, 50, n_properties) # 賃貸収入(月額)
# 立地の質に応じて賃貸収入を調整
rental_income *= np.where(location_quality == 'Low', 0.8, 1)
rental_income *= np.where(location_quality == 'High', 1.2, 1)
# データフレームの作成
df = pd.DataFrame({
'Size': size,
'Location Quality': location_quality,
'Age': age,
'Rental Income': rental_income
})
# データの可視化
plt.figure(figsize=(15, 5))
# 面積と賃貸収入の関係
plt.subplot(1, 3, 1)
sns.scatterplot(x='Size', y='Rental Income', data=df)
plt.title('Size vs. Rental Income')
# 立地の質と賃貸収入の関係
plt.subplot(1, 3, 2)
sns.boxplot(x='Location Quality', y='Rental Income', data=df)
plt.title('Location Quality vs. Rental Income')
# 築年数と賃貸収入の関係
plt.subplot(1, 3, 3)
sns.scatterplot(x='Age', y='Rental Income', data=df)
plt.title('Age vs. Rental Income')
plt.tight_layout()
plt.show()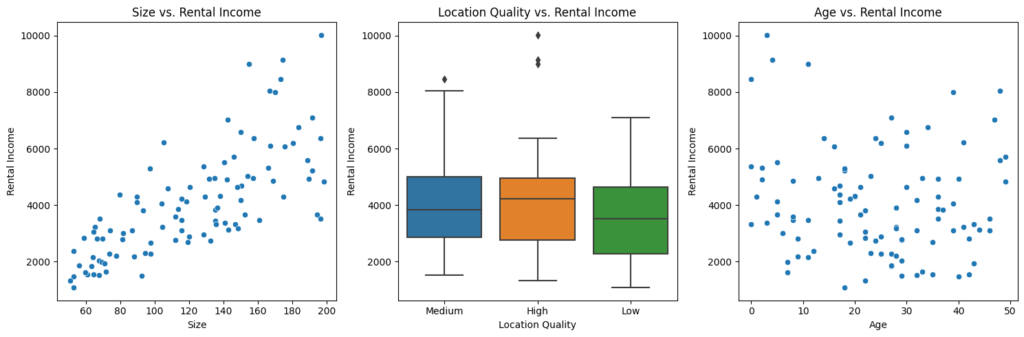
可視化グラフの解説
3つのグラフを作成しました。
- 面積と賃貸収入の関係:
- 不動産の面積が大きくなるにつれて、賃貸収入が増加する傾向が見られます。これは、一般的に大きな物件がより高い賃貸料をもたらすことを示しています。
- 立地の質と賃貸収入の関係:
- 立地の質が高いほど、賃貸収入が高くなる傾向があります。特に「High」の立地では、賃貸収入の中央値と範囲が明らかに高いことが分かります。これは、良好な立地が賃貸市場で重要な要素であることを示しています。
- 築年数と賃貸収入の関係:
- 新しい物件ほど賃貸収入が高い傾向がありますが、築年数が増えるにつれてその影響は緩やかになることが観察されます。これは、新築物件が高い魅力を持つ一方で、ある程度の築年数が経過した物件でも適切な管理と立地によっては十分な収益が上がることを示唆しています。
これらの可視化を通じて、不動産投資における収益性を評価し、より効果的な投資戦略を立てるための洞察を得られます。不動産のサイズ、立地、築年数は賃貸収入に重要な影響を与える要因であり、これらを考慮した投資計画を立てることが重要です。
Pythonによる最適化コードとその解説
不動産の賃貸収入を最適化するために、ランダムフォレスト回帰モデルを構築し、評価を行いました。結果は以下の通りです。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
# カテゴリ変数をダミー変数に変換
df_encoded = pd.get_dummies(df, columns=['Location Quality'])
# 特徴量と目的変数の定義
X = df_encoded.drop('Rental Income', axis=1)
y = df_encoded['Rental Income']
# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# ランダムフォレスト回帰モデルの作成
model = RandomForestRegressor(n_estimators=100, random_state=0)
model.fit(X_train, y_train)
# テストデータに対する予測
y_pred = model.predict(X_test)
# モデルの評価
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
mse, r2(1309905.4276118914, 0.4634951144367171)- 平均二乗誤差 (MSE): 約 1,309,905
- 決定係数 (R²): 約 0.463
このモデルの解説と結果の解釈、選択理由は次の通りです。
モデルの解説
ランダムフォレスト回帰モデルは、複数の決定木を組み合わせて動作するアンサンブル学習モデルです。このモデルは、特に特徴量間の複雑な相互作用や非線形関係を捉えるのに優れています。
データの準備
- カテゴリ変数(「Location Quality」)をダミー変数に変換し、モデルが数値として扱えるようにしました。
- 不動産のサイズ(Size)、築年数(Age)、立地の質(Location Quality)を特徴量として使用し、目的変数は賃貸収入としました。
モデルのトレーニングと評価
- トレーニングデータとテストデータに分割し、ランダムフォレストモデルをトレーニングしました。
- テストデータを用いてモデルの予測性能を評価しました。
結果の解釈
- 平均二乗誤差は約1,309,905であり、予測された賃貸収入と実際の賃貸収入の差の平均を表します。この値が小さいほど、モデルの予測精度が高いことを意味します。
- 決定係数(R²)は約0.463で、モデルがデータの変動の約46.3%を説明していることを示します。
洞察と改善の方向
このモデルは不動産の賃貸収入予測において一定の性能を示していますが、さらなる改善の余地があります。特徴量の選択、ハイパーパラメータの調整、他のアルゴリズムの試行などによってモデルの性能を向上させます。また、追加のデータ(例えば、近隣施設の情報、市場動向など)を取り入れることで、より正確な予測が可能になるかもしれません。
モデルを選んだ理由
ランダムフォレスト回帰モデルを選択した理由は、その柔軟性、堅牢性、そして一般的に高い予測精度にあります。具体的な理由は次の通りです。
1. 柔軟性と非線形の捉えやすさ:
- ランダムフォレストは、特徴量間の非線形関係や複雑な相互作用を効果的に捉えることができます。不動産市場では、さまざまな要因が複雑に絡み合って賃貸収入に影響を与えるため、この特性が有用です。
2. 過学習への抵抗力:
- 個々の決定木は過学習(トレーニングデータに過度に適合すること)しやすいですが、ランダムフォレストは多数の木を組み合わせることでこの問題を緩和します。これにより、モデルの一般化能力が向上します。
3. 特徴量の重要性の評価:
- ランダムフォレストは、各特徴量が予測にどの程度影響を与えているかを評価する機能を提供します。これにより、不動産市場における重要な要因を特定し、さらなる分析の方向性を定めるのに役立ちます。
4. 広範な応用範囲:
- ランダムフォレストは、さまざまな種類のデータセットに対して良好な性能を発揮することが知られています。つまり、不動産市場のデータが持つ特性(例えば、異なるスケールの特徴量、欠損値など)に対しても効果的に機能する可能性があります。
5. 実装の容易さと解釈のしやすさ:
- ランダムフォレストは、多くの機械学習ライブラリで容易に利用でき、その結果も比較的解釈しやすいです。実際のビジネス応用においては、これらの特性が導入と運用のハードルを下げます。
以上の理由から、ランダムフォレストは不動産の賃貸収入予測という問題に対して適切な選択肢と考えられます。実際のビジネス応用においては、データの特性や要件に応じて他のモデルも検討する必要があります。
ChatGPTとの連携
ChatGPTを上記のランダムフォレスト回帰モデルと組み合わせることで、不動産投資に関するユーザー体験を強化し、より直感的で対話的なデータ分析を提供できます。以下に具体的な機能追加とその効果を紹介します。
機能追加のアイデア:
- 対話型のデータ入力とフィードバック:
- ユーザーが不動産の特性(例:面積、立地の質、築年数)についてChatGPTに質問したり入力したりすると、モデルがその情報に基づいて賃貸収入の予測を行い、結果をユーザーに伝えます。
- 市場動向や投資戦略に関するアドバイス:
- ChatGPTは、現在の市場動向、投資戦略、または不動産投資に関する一般的なヒントを提供できます。
- データ解析結果の解釈と説明:
- ユーザーがモデルの出力(予測結果や特徴量の重要性など)について質問した場合、ChatGPTはそれをわかりやすく解説し、より深い理解をサポートします。
具体的なコードの例:
以下のコードは、PythonでChatGPTを利用する簡単な例です。この例では、ユーザーが提供した不動産の特性に基づいて賃貸収入を予測する対話型のインターフェースを想定しています。
# ChatGPTとの対話的なインターフェースの例
# このコードは概念的なものであり、実際のChatGPT APIの使用方法とは異なる可能性があります。
import openai
def predict_rental_income(size, location_quality, age):
# ここにランダムフォレストモデルの予測ロジックを入れる
# 例:return model.predict([[size, location_quality, age]])[0]
def interact_with_user():
user_input = input("Tell me about the property you are interested in: ")
response = openai.ChatGPT(user_input)
# ここでユーザーの入力に基づいて質問を解析し、必要な情報を抽出する
size, location_quality, age = parse_user_input(response)
estimated_income = predict_rental_income(size, location_quality, age)
print(f"The estimated rental income for this property is: {estimated_income}")
# この関数を実行してユーザーとの対話を開始
interact_with_user()このコードは、ユーザーが不動産に関する情報を入力し、それに基づいて賃貸収入を予測する機能を示しています。実際の実装には、OpenAIのAPIキー、ユーザー入力の解析ロジック、そして予測モデルの統合が必要です。
ChatGPTとの連携で得られる効果
- ユーザーエクスペリエンスの向上:対話型インターフェースにより、ユーザーはより直感的で自然な方法で情報を入力し、フィードバックを受け取ることができます。
- 迅速な意思決定サポート:リアルタイムでの質問応答と予測提供により、ユーザーは迅速に情報に基づいて意思決定できます。
- 複雑なデータの解釈の容易化:ChatGPTによる解説とアドバイスは、ユーザーがデータをより深く理解するのを助けます。
ビジネス・アイデア
上記のコード、アプローチ、分析、および最適化は、不動産業界以外の様々な分野にも応用できます。以下に、いくつかの応用例を紹介します。
1. 小売業界での需要予測:
- 小売業界では、商品の需要予測がとても重要です。ランダムフォレストモデルを使用して、季節、天候、販売促進活動などの要因に基づいて、商品の売上を予測できます。また、ChatGPTを組み込むことで、店舗マネージャーが容易に予測結果を解釈し、在庫管理や販売戦略を調整できます。
2. ヘルスケア分野での患者の診断支援:
- 患者の症状や医療履歴を基に、疾患の診断を支援するモデルを構築できます。ランダムフォレストは、症状のパターンを識別し、特定の病気の可能性を評価するのに有効です。ChatGPTとの組み合わせにより、医師が患者の情報を入力し、診断結果について質問できる対話型インターフェースを提供できます。
3. 金融業界でのクレジットスコアリング:
- 顧客のクレジット履歴、取引記録、個人情報などを用いて、クレジットリスクを評価するモデルを構築できます。ランダムフォレストは、これらの複雑なデータセットからパターンを識別し、クレジットスコアリングに利用きます。ChatGPTによる対話型インターフェースは、信用リスク管理者が顧客のリスクプロファイルに関する質問に即座に応答するのに役立ちます。
4. 製造業での生産最適化:
- 機械の運用データや生産プロセスのパラメータを分析し、生産効率を最大化するための最適な設定が見つかります。ランダムフォレストは、これらのパラメータと生産出力の間の複雑な関係をモデル化し、生産プロセスの改善に役立ちます。ChatGPTを活用することで、製造技術者がプロセスデータに基づいた意思決定を支援します。
これらの例は、機械学習モデルとChatGPTの組み合わせが、さまざまな業界でどのように有用であるかを示しています。予測分析と対話型インターフェースの組み合わせは、より迅速でデータに基づいた意思決定を実現します。また、業務の効率化と戦略的な洞察を提供します。

▼AIを使った副業・起業アイデアを紹介♪

