
はじめに
ペットとIoTの融合の可能性
日常生活で忙しい中で、ペットの健康管理を十分に行うことは難しいことがあります。近年、IoT(モノのインターネット)技術が急速に発展し、生活に変化をもたらしています。IoT技術をペットの健康管理に応用することで、オーナーはいつでもペットの状態を把握し、よりよいケアを提供できます。例えば、IoTデバイスを使用してペットの活動量を監視したり、食事や睡眠のパターンを追跡することで、健康の早期の兆候を捉えることができます。
本記事の目的と構造
本記事では、PythonとIoTを活用してペットの健康状態をリアルタイムで分析する方法について解説します。Pythonはその柔軟性と強力なライブラリのサポートにより、データ収集から解析、可視化まで一連のプロセスを簡単に実装できる言語です。まず、IoTデバイスからデータを収集する方法と、そのデータをPythonでどのように扱うかを見ていきます。そして、データ前処理の重要性を紹介し、リアルタイム解析アルゴリズムの実装について解説します。さらに、機械学習を取り入れてペットの健康状態をより詳細に分析する方法についても紹介します。ChatGPTとの連携によるペットモニタリングの未来についても考察します。
IoTを活用したペットの健康管理システムの概要
IoTデバイスの種類とその特徴
IoTデバイスには、さまざまな種類があり、それぞれに独特の特徴があります。例えば、ウェアラブルデバイスはペットの首輪に取り付けられ、活動量や睡眠パターンを記録します。また、スマートフィーダーは、ペットの食事の量や時間を自動でコントロールし、健康的な体重維持に役立ちます。これらのデバイスは、BluetoothやWi-Fiなどの無線通信を介してデータを送信し、ペットの健康状態をリアルタイムでモニタリングできます。
PythonとIoTデバイスの連携方法
Pythonは、その読みやすい構文と強力なライブラリによって、IoTデバイスとの連携にとても適しています。IoTデバイスから送られてくるデータを処理するためには、通常、MQTTプロトコルやHTTPリクエストを用いた通信が行われます。Pythonにはこれらのプロトコルを簡単に扱うことができるpaho-mqttやrequestsなどのライブラリがあります。IoTデバイスからデータを受け取り、解析するプロセスを簡単に実装できます。
def simulate_mqtt_example():
import paho.mqtt.client as mqtt
def on_connect(client, userdata, flags, rc):
print("Connected with result code "+str(rc))
client.subscribe("pets/health")
def on_message(client, userdata, msg):
print(msg.topic+" "+str(msg.payload))
client = mqtt.Client()
client.on_connect = on_connect
client.on_message = on_message
# シミュレートされた接続イベント
on_connect(client, None, None, 0)
# シミュレートされたメッセージイベント
class SimulatedMessage:
def __init__(self, topic, payload):
self.topic = topic
self.payload = payload
simulated_msg = SimulatedMessage("pets/health", b"Sample payload")
on_message(client, None, simulated_msg)
simulate_mqtt_example()Connected with result code 0
pets/health b'Sample payload'ペットの健康データの種類と収集手法
ペットの健康データには、心拍数、体温、活動量、睡眠の質など、様々な種類があります。これらのデータは、上述のウェアラブルデバイスやスマートホームデバイスを通じて収集されます。これらのデータを集積し、分析することで、ペットの健康状態に関する洞察を得られます。例えば、活動量のデータは、Matplotlibライブラリを使用して視覚的に表現できます。
# Matplotlibを使用してペットの活動量データをグラフ化するPythonの例
import matplotlib.pyplot as plt
# サンプルデータ
activity_data = [5, 6, 7, 8, 5, 4, 6, 7, 8, 9, 6, 5, 4]
# グラフの作成
plt.plot(activity_data)
plt.title('Pet Activity Levels')
plt.xlabel('Time')
plt.ylabel('Activity')
plt.show()
収集されたデータを適切に処理・分析することにより、ペットの健康管理に役立つ情報を得られます。
Pythonを使用したペットデータのリアルタイム解析
Pythonライブラリの紹介とセットアップ
ペットの健康状態をリアルタイムで分析するためには、Pythonを活用したデータ解析が有効です。Pythonは、その読みやすさ、豊富なライブラリ、そしてデータサイエンスへの適合性から、この分野で広く利用されています。ここでは、リアルタイム分析に必要なPythonライブラリをいくつか紹介し、基本的なセットアップ方法について解説します。
まず、データ処理にはpandasライブラリを使用します。これはデータ分析を容易にする機能を多数提供しています。次に、数値計算にはnumpyが欠かせません。リアルタイムでのデータストリームを扱う場合にはpySerialを使用することで、シリアルポート経由のデータの読み書きを行えます。
グラフや可視化には、matplotlibライブラリを使用します。matplotlibにより、収集したデータを直感的に理解できます。また、リアルタイムデータのプロットにはmatplotlib.animationモジュールが役立ちます。
これらのライブラリをインストールするには、以下のコマンドを実行します。
pip install pandas numpy pyserial matplotlibインストール後、実際にセンサーからのデータをグラフにプロットするサンプルコードは以下の通りです。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from datetime import datetime, timedelta
from matplotlib.animation import FuncAnimation
# シミュレーション用の時間とデータを生成
start_time = datetime.now()
def simulate_serial_read():
global start_time
sensor_value = np.random.random() * 100 # 0 to 100の乱数を生成
time = start_time.strftime('%Y-%m-%d %H:%M:%S')
start_time += timedelta(seconds=1)
return f"{time},{sensor_value}"
# プロットするデータを保持するリスト
data = {
'time': [],
'sensor_value': []
}
fig, ax = plt.subplots()
line, = ax.plot_date(data['time'], data['sensor_value'], '-')
def update(frame):
line_data = simulate_serial_read()
time, sensor_value = line_data.split(",")
data['time'].append(pd.to_datetime(time))
data['sensor_value'].append(float(sensor_value))
line.set_data(data['time'], data['sensor_value'])
ax.relim()
ax.autoscale_view()
fig.autofmt_xdate()
ani = FuncAnimation(fig, update, interval=1000)
plt.show()

上記のコードは、シリアルポート経由でペットの健康データ(ここでは時間とセンサー値)をリアルタイムで受け取り、matplotlibを用いてグラフにプロットするものです。FuncAnimationは、グラフを定期的に更新するために使用します。
これにより、ペットの健康状態をリアルタイムで視覚化し、分析できます。
Pythonを使用したペットデータのリアルタイム解析
Pythonでサンプルデータ作成と解説
Pythonでのサンプルデータの作成は、実際のペット健康データ解析に先立って、解析手法やアルゴリズムの理解に有用です。ここでは、ペットの健康状態を示す架空のデータセットを生成し、基本的な統計情報を取得して可視化するプロセスを紹介します。
まず、データセットの作成にはPythonのpandasライブラリを使用します。pandasはデータの操作と分析に特化した強力なツールで、Excelのような表形式のデータを扱うことができます。
import pandas as pd
import numpy as np
# サンプルデータセットの生成
np.random.seed(0)
dates = pd.date_range('20230101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
# データセットの先頭を表示
print(df.head()) A B C D
2023-01-01 1.764052 0.400157 0.978738 2.240893
2023-01-02 1.867558 -0.977278 0.950088 -0.151357
2023-01-03 -0.103219 0.410599 0.144044 1.454274
2023-01-04 0.761038 0.121675 0.443863 0.333674
2023-01-05 1.494079 -0.205158 0.313068 -0.854096次に、データの可視化にはmatplotlibライブラリを利用します。matplotlibは、グラフを簡単に作成できるライブラリです。ここでは、生成したデータの時系列変化を線グラフで表示してみましょう。
import matplotlib.pyplot as plt
# データのプロット
plt.figure(figsize=(10,6))
plt.plot(df.index, df['A'], marker='o', label='Column A')
plt.plot(df.index, df['B'], marker='x', label='Column B')
plt.legend(loc='best')
plt.title('Sample Data Visualization')
plt.xlabel('Date')
plt.ylabel('Value')
plt.grid(True)
plt.show()
このコードは、時間とともに変化するペットの健康データを模擬しており、グラフを通じて変動パターンを視覚的に捉えることができます。リアルタイムでの健康状態の監視には、これらの基本を応用し、IoTデバイスから送信されるデータストリームを処理して可視化する方法などがあります。
データ前処理は、データの質を高め、機械学習モデルの性能を最大化するために不可欠です。Pythonでは、NumPyやPandasなどのライブラリを使って、このプロセスを簡潔かつ効率的に実施できます。
Pythonでサンプルデータを生成して前処理を行う方法を以下に紹介します。
import numpy as np
import pandas as pd
from scipy import stats
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# 乱数のシードを設定
np.random.seed(0)
# サンプルデータの生成
# 年齢は1〜10歳、体重は1〜40kgの範囲でランダムなデータを100個生成すると仮定
age_data = np.random.randint(1, 11, 100)
weight_data = np.random.randint(1, 41, 100)
health_scores = np.random.randint(1, 101, 100) # 健康スコアを1〜100で生成
# pandas DataFrameに変換
data = pd.DataFrame({
'Age': age_data,
'Weight': weight_data,
'HealthScore': health_scores
})
# 欠損値のシミュレーション
# AgeとWeightにランダムに欠損値を挿入する
for col in ['Age', 'Weight']:
data.loc[data.sample(frac=0.1).index, col] = np.nan
# 欠損値を中央値で埋める
data.fillna(data.median(), inplace=True)
# 外れ値を検出し、外れ値がある行を削除する
data = data[(np.abs(stats.zscore(data)) < 3).all(axis=1)]
# データの正規化
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# 正規化されたデータの確認
print(pd.DataFrame(data_scaled).head())
# 年齢のヒストグラムを描画する
plt.hist(data['Age'], bins=10, edgecolor='black')
plt.title('Age Distribution')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()
# 体重のヒストグラムを描画する
plt.hist(data['Weight'], bins=10, edgecolor='black')
plt.title('Weight Distribution')
plt.xlabel('Weight')
plt.ylabel('Frequency')
plt.show() 0 1 2
0 0.555556 0.743590 0.237113
1 0.000000 0.076923 0.546392
2 0.333333 0.871795 0.525773
3 0.333333 0.333333 0.474227
4 0.777778 1.000000 0.206186
このコードでは、まずランダムな数値を生成してサンプルデータを作成し、その後に実際のデータセットに存在しうるような欠損値を模擬的に生成しています。次に、欠損値を中央値で補完し、Zスコアを用いて外れ値を除去します。最後に、データを正規化してから、年齢と体重の分布をヒストグラムで可視化しています。
これらのステップはデータをクリーニングし、機械学習モデルが扱いやすい形式に変換するために行います。実際のデータ分析では、これらのプロセスをデータセットの特性に応じて調整し、最適化することが重要です。
リアルタイム解析アルゴリズムの実装と解説
IoTデバイスからリアルタイムで得られるペットの健康データは、そのままでは解析に適していない場合があります。そのため、リアルタイム解析を行う際には、データをクリーニングし、適切な加工が必須となります。Pythonでは、これらのプロセスを簡単に実行できるライブラリが多数あります。
まず、サンプルデータを生成するには、NumPyやPandasなどのライブラリが有効です。以下のコードは、リアルタイムデータの流れをシミュレートするサンプルデータを生成します。
import numpy as np
import pandas as pd
# サンプルデータの生成
np.random.seed(0)
time_stamps = pd.date_range('20230101', periods=60, freq='S')
data = pd.DataFrame({
'Time': time_stamps,
'HeartRate': np.random.randint(60, 120, size=(60)),
'Temperature': np.random.uniform(37.5, 39.5, size=(60)),
'Activity': np.random.choice(['Resting', 'Playing', 'Eating'], size=(60))
})
print(data.head())Time HeartRate Temperature Activity
0 2023-01-01 00:00:00 104 38.973836 Eating
1 2023-01-01 00:00:01 107 37.933101 Resting
2 2023-01-01 00:00:02 113 37.770436 Resting
3 2023-01-01 00:00:03 60 38.148282 Eating
4 2023-01-01 00:00:04 63 37.799350 Restingこのデータを用いてリアルタイム解析を行うには、データストリームを模倣する必要があります。ストリーミングデータを処理する一つの方法は、Pythonのジェネレータを使用することです。以下のコードは、生成されたサンプルデータをリアルタイムで処理するためのジェネレータ関数を示しています。
def stream_data(data_frame):
for _, row in data_frame.iterrows():
yield row
# ジェネレータを作成
data_stream = stream_data(data)
# データストリームから1行ずつデータを処理する
for data_point in data_stream:
print(data_point)Time 2023-01-01 00:00:57
HeartRate 83
Temperature 37.666225
Activity Playing
Name: 57, dtype: object
Time 2023-01-01 00:00:58
HeartRate 95
Temperature 38.055437
Activity Playing
Name: 58, dtype: object
Time 2023-01-01 00:00:59
HeartRate 71
Temperature 37.518713
Activity Resting
Name: 59, dtype: objectデータがリアルタイムで流れてくると想定し、このジェネレータは各時点のデータポイントを一つずつ出力します。ここで、データのクリーニングや変換を行う処理を挿入できます。
リアルタイム解析では、データの傾向を迅速に把握するために、時系列グラフなどの可視化が有効です。Matplotlibを使用して、動的に更新されるグラフを作成できます。
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
# プロットの初期化
fig, ax = plt.subplots()
xdata, ydata = [], []
ln, = plt.plot([], [], 'r-', animated=True)
def init():
ax.set_xlim(pd.Timestamp('2023-01-01'), pd.Timestamp('2023-01-01 00:00:59'))
ax.set_ylim(0, 150)
return ln,
def update(frame):
xdata.append(frame['Time'])
ydata.append(frame['HeartRate'])
ln.set_data(xdata, ydata)
return ln,
ani = FuncAnimation(fig, update, frames=stream_data(data), init_func=init, blit=True)
plt.show()
このアニメーションの例では、心拍数の変化をリアルタイムでプロットします。FuncAnimationは更新関数を定期的に呼び出し、グラフを新しいデータポイントで更新します。
Pythonと適切なライブラリを用いることで、リアルタイムデータの解析と可視化を効果的に実施できます。これは、ペットの健康管理システムにおいて、異常を迅速に検知し対処するために有効です。
機械学習を取り入れたペットの健康状態分析
ペットの健康を管理する上で、機械学習はとても強力なツールです。大量のデータからパターンを学習し、ペットの健康状態に関する洞察を提供できます。今回は、特徴量エンジニアリングについて解説します。
ペットの健康に関するデータの特徴量エンジニアリング
特徴量エンジニアリングとは、機械学習モデルがデータから学習するために、データを最も有効な形に加工する作業です。このプロセスでは、元のデータセットからより有用な特徴量を生成したり、不要な特徴量を削除することによって、モデルの性能を向上させます。
たとえば、ペットの活動量や睡眠パターン、食事量などの時系列データから、平均、最大、最小、標準偏差といった統計的な特徴量を生成できます。これにより、単なる生データよりもはるかに多くの情報を機械学習モデルに提供できます。
Pythonを使用して、ペットの健康データから基本的な特徴量を生成するサンプルコードを見てみましょう。
import numpy as np
# ペットの1週間の活動データを模擬的に生成する
np.random.seed(0)
activity_data = np.random.normal(5000, 800, 7) # 1週間の活動量のサンプルデータ
# 基本的な統計量を計算
mean_activity = np.mean(activity_data)
max_activity = np.max(activity_data)
min_activity = np.min(activity_data)
std_activity = np.std(activity_data)
# 結果を表示
print(f"Mean activity: {mean_activity:.2f}")
print(f"Max activity: {max_activity:.2f}")
print(f"Min activity: {min_activity:.2f}")
print(f"Standard deviation: {std_activity:.2f}")Mean activity: 5825.62
Max activity: 6792.71
Min activity: 4218.18
Standard deviation: 808.04このような基本統計量は、ペットの活動の変動を把握するのに役立ちます。次に、これらの特徴量をMatplotlibを使って視覚化します。
import matplotlib.pyplot as plt
# 活動量のデータと基本統計量をプロット
days = ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
plt.plot(days, activity_data, marker='o', label='Activity')
plt.axhline(y=mean_activity, color='r', linestyle='-', label='Mean Activity')
# グラフのタイトルと軸ラベルを追加
plt.title('Pet Activity During the Week')
plt.xlabel('Day of the Week')
plt.ylabel('Activity Level')
# 凡例を表示
plt.legend()
# グラフを表示
plt.show()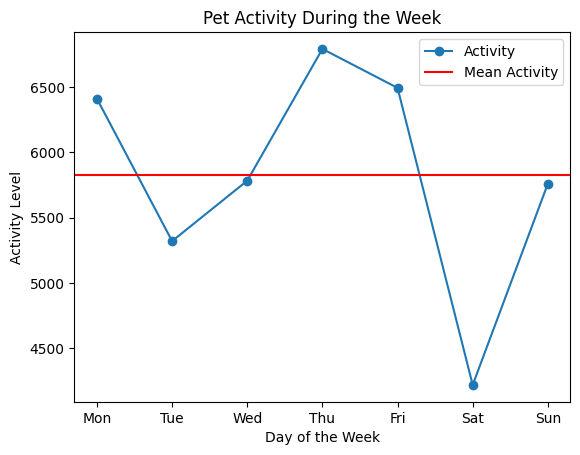
このグラフは、ペットの活動量が1週間でどのように変動するかを一目で理解できます。さらに、平均値の線が活動パターンにおける基準点となります。
このプロセスを繰り返すことで、さまざまな側面からペットの健康状態を分析するための豊富な特徴量セットを構築できます。
適切な機械学習モデルの選定とその根拠
ペットの健康状態を分析するためには、多様なデータから有益な情報を抽出し、正確な予測を行う機械学習モデルの選定が重要です。ペットの行動パターンや生体信号など、IoTデバイスから取得したデータセットの特性に合わせたモデルを選ぶ必要があります。
分類問題として考えた場合、健康状態を「正常」と「異常」の2つのクラスに分けることが一般的です。ここで、サポートベクターマシン(SVM)、ランダムフォレスト、勾配ブースティングマシン(GBM)、そして深層学習モデルなどが候補に挙がります。
Pythonでサンプルデータを作成し、簡単な特徴量エンジニアリングを行った後、これらのモデルの性能を比較検討します。ここでは、Scikit-learnライブラリを使用して、ランダムフォレスト分類器のサンプルコードを解説します。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# サンプルデータの生成
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ランダムフォレスト分類器のインスタンス化と学習
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
rf_classifier.fit(X_train, y_train)
# 性能評価
y_pred = rf_classifier.predict(X_test)
print(classification_report(y_test, y_pred))
# 混同行列の可視化
conf_matrix = confusion_matrix(y_test, y_pred)
sns.heatmap(conf_matrix, annot=True, fmt='d')
plt.title('Confusion Matrix')
plt.show()precision recall f1-score support
0 0.92 0.93 0.93 100
1 0.93 0.92 0.92 100
accuracy 0.93 200
macro avg 0.93 0.93 0.92 200
weighted avg 0.93 0.93 0.92 200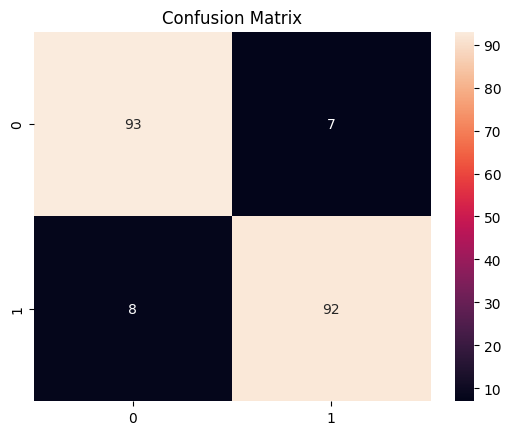
このコードは、ランダムフォレストモデルを用いて生成されたサンプルデータを分類し、性能評価として分類レポートと混同行列を出力します。混同行列を可視化することで、モデルがどのように正誤を判断しているかが一目でわかります。
モデル選定の根拠としては、データの特性(特徴量の数、サンプルサイズ、クラスのバランスなど)と計算コスト、解釈可能性を考慮します。例えば、ランダムフォレストは特徴量の重要度を評価できるため、どの変数が予測に寄与しているかを知るのに役立ちます。また、非線形なデータパターンに対しても頑健であり、過学習にも比較的強いです。
これに対して、深層学習モデルは、より複雑なデータの特徴を捉えられる可能性がありますが、大量のデータと計算リソースを必要とするため、状況に応じた適切な選択が求められます。最終的には、クロスバリデーションなどを行い、複数のモデルの性能を慎重に比較した上で、最も適したモデルを選定します。
モデルのトレーニングと評価方法
ペットの健康状態を分析するためには、正確な機械学習モデルの構築が不可欠です。ここでは、Pythonを使用してモデルをトレーニングし、その評価方法について解説します。
まず、トレーニングには教師あり学習を利用します。これは、入力データと正解ラベルをモデルに与え、予測能力を高める方法です。以下にPythonでのサンプルコードを紹介します。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# サンプルデータの生成
X, y = make_classification(n_samples=1000, n_features=10, random_state=42)
# データセットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# モデルのインスタンス化とトレーニング
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# テストデータに対する予測
y_pred = model.predict(X_test)
# 評価結果の表示
print(classification_report(y_test, y_pred)) precision recall f1-score support
0 0.85 0.93 0.89 113
1 0.94 0.87 0.90 137
accuracy 0.90 250
macro avg 0.90 0.90 0.90 250
weighted avg 0.90 0.90 0.90 250このコードでは、まずデータセットをトレーニング用とテスト用に分割し、ランダムフォレスト分類器をトレーニングしています。その後、テストデータに対する予測を行い、その結果をclassification_reportを用いて評価します。
モデルの評価では、精度(Accuracy)、適合率(Precision)、再現率(Recall)、F1スコアなどの指標を確認します。これらの指標はモデルがどれだけ正確に予測できているかを示す重要な指標です。
また、モデルのトレーニングプロセスや評価結果を視覚的に理解しやすくするために、Matplotlibを使用してグラフを描画できます。例えば、以下のコードはモデルの評価指標を棒グラフで表示します。
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 評価指標の計算
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
# 評価指標をリストに格納
metrics = [accuracy, precision, recall, f1]
metrics_labels = ['Accuracy', 'Precision', 'Recall', 'F1 Score']
# 棒グラフの描画
plt.bar(metrics_labels, metrics)
plt.title('Model Evaluation Metrics')
plt.ylabel('Score')
plt.show()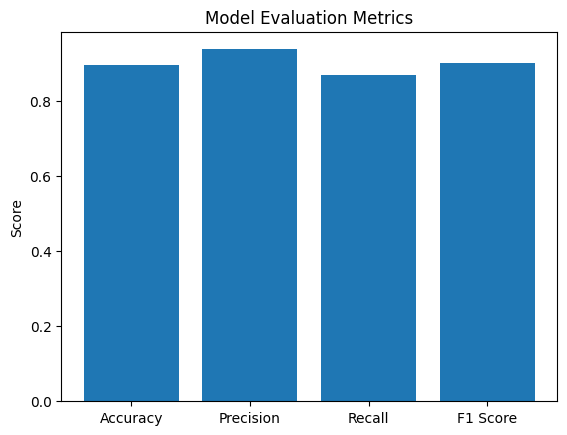
トレーニングされたモデルが未知のデータに対しても良いパフォーマンスを発揮することが期待されますが、過学習を防ぐためにも、様々なデータセットでの評価が重要です。最終的には、このモデルを用いてペットの健康状態をリアルタイムで監視し、ペットオーナーに貴重な情報を提供することが目標です。
ChatGPTを活用したペットモニタリング
ChatGPTを組み込んだペットモニタリングシステムの構築
ChatGPTは自然言語処理技術を活用し、リアルタイムでの対話が可能なAIです。ペットモニタリングシステムにChatGPTを組み込むことで、飼い主や獣医師が直接ペットの健康状態について問い合わせると、システムがリアルタイムで適切な情報を提供できます。
Pythonを使用してChatGPTをペットモニタリングシステムに組み込むには、まずOpenAI提供のAPIキーを取得する必要があります。次に、openaiライブラリをインストールし、APIキーを用いてAPIと通信するスクリプトを書きます。例えば、ペットの活動量や食事摂取量などのデータを収集し、それらの情報を基にChatGPTがペットの健康状態を評価するための質問に答えられるようになります。
リアルタイムでの質問応答によるペットケアのサポート
リアルタイムでの質問応答機能は、飼い主がペットの日常的な健康管理をサポートします。たとえば、ペットが今日どれくらい運動したかや、何を食べたかなどの質問に、ChatGPTが集めたデータに基づいて回答します。これには、IoTデバイスから送信されるデータをリアルタイムで解析する機能が必要です。Pythonでは、websocketsなどのライブラリを使用してリアルタイムデータ通信を実現できます。
ChatGPTを使用した獣医師との連携
ChatGPTは、獣医師が遠隔でペットの健康を監視する際にも役立ちます。獣医師はChatGPTを通じてペットの健康データにアクセスし、必要に応じてアドバイスを送ることができます。例えば、Pythonスクリプトを使用して獣医師にリアルタイムのアラートを送信するシステムを構築できます。このような連携は、特に緊急時において、迅速な対応を促すことに繋がります。
IoTとAIを融合したペットケアの未来
AIによる異常検知とリアルタイムアラートシステム
ペットの健康管理において、AIの導入は大きな変化をもたらします。特に、AIによる異常検知システムは、ペットの日常生活における健康状態の微妙な変化を敏感に捉え、飼い主や獣医に対してリアルタイムでアラートを提供できます。例えば、Pythonで実装された異常検知アルゴリズムは、ペットの活動量や体温、食欲などのデータを解析し、普段とは異なるパターンを検出した場合にアラートを発することができます。
以下に、簡単な異常検知のサンプルコードを解説します。ここでは、ペットの体温が一定の範囲を超えた場合に警告を出すコードです。
import numpy as np
# 体温データのサンプル
temperatures = np.random.normal(38.5, 0.5, 100)
# 異常体温の閾値設定
THRESHOLD_HIGH = 39.5
THRESHOLD_LOW = 37.5
def detect_anomaly(temp):
if temp > THRESHOLD_HIGH or temp < THRESHOLD_LOW:
return "警告: 異常な体温検出!"
else:
return "正常範囲内です。"
# 体温データをチェック
for t in temperatures:
status = detect_anomaly(t)
if "警告" in status:
print(f"異常体温: {t:.2f}℃ - {status}")異常体温: 37.22℃ - 警告: 異常な体温検出!
異常体温: 39.63℃ - 警告: 異常な体温検出!Pythonを活用することで、ペットの健康状態の異常をリアルタイムに把握し、早急な対応を促すことができます。
データ駆動型ペットケアの利点と課題
データ駆動型ペットケアは、ペットの健康状態をより客観的に把握できるという大きな利点があります。IoTデバイスから収集される膨大なデータを活用し、ペットの健康トレンドを分析することで、病気の予防や早期発見につながります。さらに、これらのデータを基にカスタマイズされたケアプランを構築でき、各ペットに最適なケアを提供できます。
しかし、これには課題も存在します。大量のデータを安全に保管・管理するためのインフラストラクチャが必要であり、プライバシー保護の観点からも慎重な取り扱いが必須です。また、データの解釈には専門知識が必要となるため、獣医師とデータサイエンティストの間での連携が不可欠です。データを基にした意思決定を支援するために、正確で信頼性の高いモデルの構築が求められます。

▼AIを使った副業・起業アイデアを紹介♪

